
MapReduce原理
HSql [Group by] 语句 执行阶段:
输入文件->输入分片->Map阶段->Combiner阶段->Shuffle阶段->Reduce阶段->输出文件
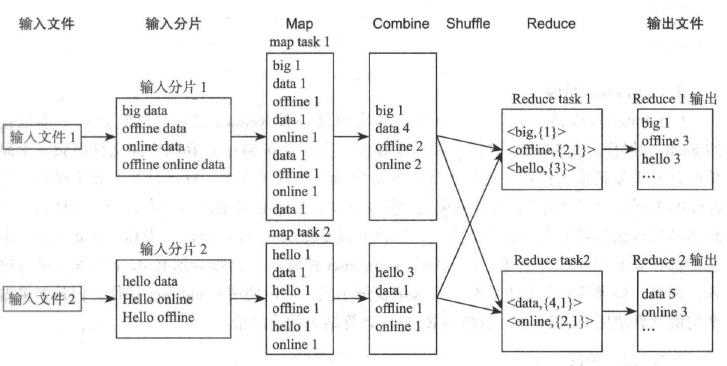
1) 输入文件
2) 输入分片阶段:
split数量由文件大小决定,不同版本split大小不同。hadoop1.x 是64MB, hadoop2.x是128MB
3) Map阶段:
map 任务的个数由分片阶段的split个数决定
4) Combiner阶段
Combiner阶段是可选的,如果指定了Combiner操作,那么hadoop会在Map任务的本地输出中执行Combiner操作,主要是在Map计算出文件前做一个简单的合并重复键值的操作,好处是可以去除冗余输出,避免不必要的后续处理和网络开销等。
但Combiner操作是有风险的,使用它的原则就是Combiner的输出不会影响到Reduce计算的最中输入。
例如,如果计算只是求总数、最大值和最小值,可以使用Combiner,但是如果做平均值计算了,使用的Combiner,那么最终的Reduce极端结果就会出错。
5) Shuffle阶段
Map任务的输出必须经过Shuffle阶段才能被Reducer处理,Shuffle过程是MapReduce的核心,是指Map任务输出到Reduce任务输入的整个处理过程。
Shuffle阶段的性能直接影响整个MapReduce的性能。
Shuffle分为Map端和Reduce端的Shuffle,完整的Shuffle过程包含5个过程:
partition(分区) sort(排序) spill(分隔) copy(复制) merge(合并)
Map端Shuffle:
1)spill(分隔):Map的输出的数据都很大,而且还需要对结果进行排序,内存开销很大,因此完全在内存中完成是不可能的。
所以Map输出事会在内存里开启一个环形内存缓存区,并且为了这个缓存区配置一个阈值(默认80%),
如果缓存区的内存使用达到了阈值,那么就会把内存内容写到磁盘上。
2)partition(分区):内存缓冲区内容分隔到磁盘前,会首先进行分区操作,分区数量由Reduce的数量决定。
3)merge(合并):每次分隔操作都会生成一个分隔文件。全部Map输出完成后,可能会有很多的分隔文件,所以在Map任务结束前,还要进行合并操作。
即将这些分隔文件按照分区合并为单独的文件。在合并过程中,同样也会进行排序,如果定义了Combiner函数,也会精心Combiner操作。
Reduce端Shuffle: Shuffle在Reduce阶段可以分为3个阶段
1)Copy Map输出
Map任务完成后,会通知父TaskTracker状态已完成,TaskTracker进而通知JobTracker。对于job来说JobTracker记录了Map输出和TaskTracker的映射关系。
同时Reduce任务也会定期的向JobTracker获取Map的输出与否以及输出的文件位置,一旦拿到输出位置,Reduce任务就会启动Copy线程
2)Merge阶段
此处的合并与Map阶段的合并类似,复制过来的数据会首先放入到内存缓冲区中。这里的内存缓冲区大小比Map阶段要灵活很多,它基于JVM的heap size设置,因为Shuffle阶段Reduce Task并不运行。
合并阶段根据要出处理的数据量不同,也可能会有分隔到磁盘的过程。
3)Reduce Task输入:
不断合并后,最后会生产一个最终结果,可能在内存也可能在磁盘。至此Reduce Task输入准备完毕
对于join 语句, Shuffle过程主要是Partition,根据其join的列进行数据的重新分布和分发过程。join语句partition列就是join时的列。
6) Reduce阶段
Reduce Task只需调用reduce函数逻辑将他们汇总即可
7) 输出文件
Hadoop合并Reduce Task任务的输出文件到输出目录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号