
4月4日刷面经
每天刷三篇面经
Hadoop
- 简单介绍一下Hadoop
- shuffle过程
- 数据倾斜问题处理方法
- 6.HDFS的读数据流程(深究) DataNode之间传输Packet一个过程 balabala
- HDFS支不支持多个客户端写同一个数据文件
C++
- 面向对象的特性?说一下三大特性的具体含义?
Python
- 你用python比较多的话,Python的垃圾回收是怎么做的。
JAVA
- java的回收机制,内存模型
- java8中lambda表达式
- 面向对象的特性?说一下三大特性的具体含义?
Spark
- spark和hadoop的区别
- spark怎么实现shffle的。答了基于hash的方式
- spark比较早的版本是基于hash实现shuffle的,新的版本是怎么实现shuffle的。
Mysql
-
mysql存储过程
存储过程是一个数据库对象,可以封装SQL语句集,可以用于比较复杂的业务,然后说说为什么用存储过程,如何使用存储过程,检查存储过程
-
Mysql窗口函数
窗口函数是mysql8.0的新特性,也称分析函数,类似与分组函数,但是不同的是,每一行都会生成一个结果.
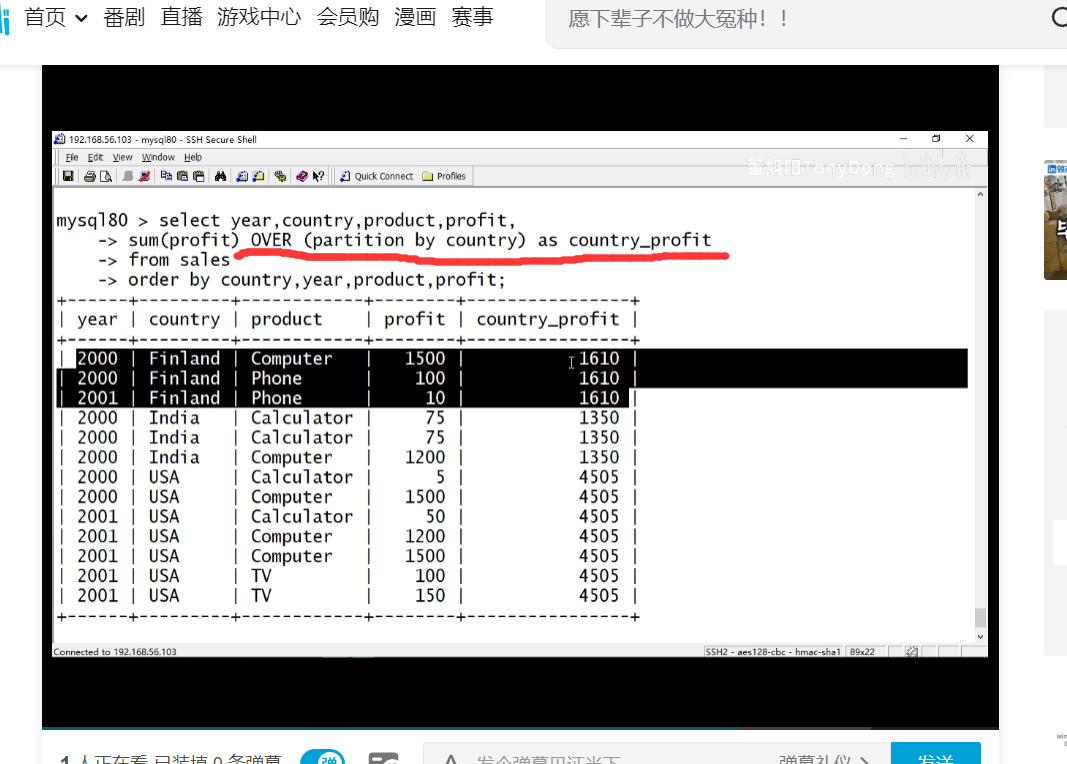
专用窗口函数
-
了解哪一种数据库,我说mysql
-
说一下mysql,我说了索引的相关知识,索引的类型,索引的优化,索引失效场景
一种帮助mysql提高查询效率的数据结构
-
非关系型和关系型数据库的区别
-
问MySQL为什么采用B+树佐索引
Kafka
- Kafka的partition存储具体细节
- Kafka中索引和真实数据的具体查询机制(.index和.log,二分查找)
- Kafka消费者组中如果一个消费者挂掉,会发生什么?(怎么保证后续消费的正常?) 补:涉及协议
Hive
算法题
- 算法题数组中的第 k 大的数字
- 给定一个 排序好 的数组 arr ,两个整数 k 和 x ,从数组中找到最靠近 x (两数之差最小)的 k 个数。返回的结果必须要是按升序排好的。
- 阿里3.14笔试
算法1,输入:16进制字符串,返回2进制中1的个数,思路,针对0~f,直接map,然后便利累加
算法2,输入:给一个只包含0、1的二维数组,设置result,如果数组元素为0,上下左右四个方向只要有1存在,则result加1. 思路,三维dp,然后上下左右做四次循环,更新dp。最后累加
数据结构
- 写一个归并排序
- 堆排序的具体流程、时间复杂度、为什么是O(nlogn)
数据建模
- 问大数据建模了解不

 浙公网安备 33010602011771号
浙公网安备 33010602011771号