
实验一 感知器及其应用
| 博客班级 | 机器学习 |
|---|---|
| 作业要求 | 实验一 感知器及其应用 |
| 作业目标 | 1. 理解感知器算法原理,能实现感知器算法;2. 掌握机器学习算法的度量指标;3. 掌握最小二乘法进行参数估计基本原理;4. 针对特定应用场景及数据,能构建感知器模型并进行预测。 |
| 学号 | 3180701211 |
一.实验目的
1.理解感知器算法原理,能实现感知器算法;
2.掌握机器学习算法的度量指标;
3.掌握最小二乘法进行参数估计基本原理;
4.针对特定应用场景及数据,能构建感知器模型并进行预测。
二.实验内容
1.安装Pycharm,注册学生版。
2.安装常见的机器学习库,如Scipy、Numpy、Pandas、Matplotlib,sklearn等。
3.编程实现感知器算法。
4.熟悉iris数据集,并能使用感知器算法对该数据集构建模型并应用
三.实验过程和结果
1、代码注释:
#Pandas,是python的一个数据分析包,Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
#Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
#matplotlib是python的一个绘图库
%matplotlib inline
运行截图:

2、代码注释:
#load data
iris=load_iris()
#DataFrame是Python中Pandas库中的一种数据结构它类似excel,是一种二维表,单元格可以存放数值、字符串等。
#pd.DataFrame(data,index,columns):其中第一个参数是存放在DataFrame里的数据,第二个参数index是行名(行索引),第三个参数columns是列名(列索引);
df=pd.DataFrame(iris.data,columns=iris.feature_names)//将列名设置为特征
# 将iris.target的值赋给label列,target中的值只包含0/1/2
df['ladel']=iris.target//增加一列为类别标签
运行截图:

3、代码注释:
# 构建DataFrame中的列名
df.columns=['sepal length','sepal width','petal length','petal width','label']
# print(df.label.value_counts())
# 计算iris.target中0/1/2的数量,便于分类时选取数量,只取0/1,不取2,得到0/1/2各有50个
#value_counts():计算series里面相同数据出现的频率(次数);
df.label.value_counts()
运行截图:

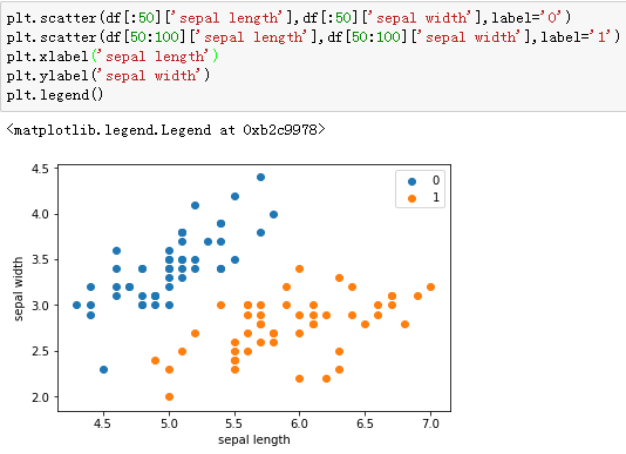
4、代码注释:
#Matplotlib中的scatter()函数
plt.scatter(df[:50]['sepal length'],df[:50]['sepal width'],label='0')//绘制散点图
plt.scatter(df[50:100]['sepal length'],df[50:100]['sepal width'],label='1')
plt.xlabel('sepal length')//给图加上图例
plt.ylabel('sepal width')
plt.legend()
运行截图:
5、代码注释:
data=np.array(df.iloc[:100,[0,1,-1]])//按行索引,取出第0,1,-1列
运行截图:
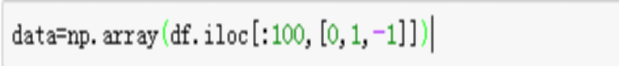
6、代码注释:
X, y = data[:,:-1], data[:,-1]//X为sepal length,sepal width y为标签
运行截图:

7、代码注释:
y = np.array([1 if i == 1 else -1 for i in y])//将两个类别设重新设置为+1 —1
运行截图:

8、代码注释:
%# 数据线性可分,二分类数据
%# 此处为一元一次线性方程
class Model:
def init(self)://将参数w1,w2置为1 b置为0 学习率为0.1
self.w = np.ones(len(data[0])-1, dtype=np.float32) //data[0]为第一行的数据len(data[0]=3)这里取两个w权重参数
self.b = 0
self.l_rate = 0.1
%# self.data = data
def sign(self, x, w, b):
y = np.dot(x, w) + b
return y
%# 随机梯度下降法
def fit(self, X_train, y_train)://拟合训练数据求w和b
is_wrong = False//判断是否误分类
while not is_wrong:
wrong_count = 0
for d in range(len(X_train))://取出样例,不断的迭代
X = X_train[d]
y = y_train[d]
if y * self.sign(X, self.w, self.b) <= 0://根据错误的样本点不断的更新和迭代w和b的值(根据相乘结果是否为负来判断是否出错,本题将0也归为错误)
self.w = self.w + self.l_ratenp.dot(y, X)
self.b = self.b + self.l_ratey
wrong_count += 1
if wrong_count == 0://直到误分类点为0 跳出循环
is_wrong = True
return 'Perceptron Model!'
def score(self):
pass
运行截图:

9、代码注释:
perceptron = Model()
#使用训练数据进行训练
perceptron.fit(X, y)//感知机模型
运行截图:

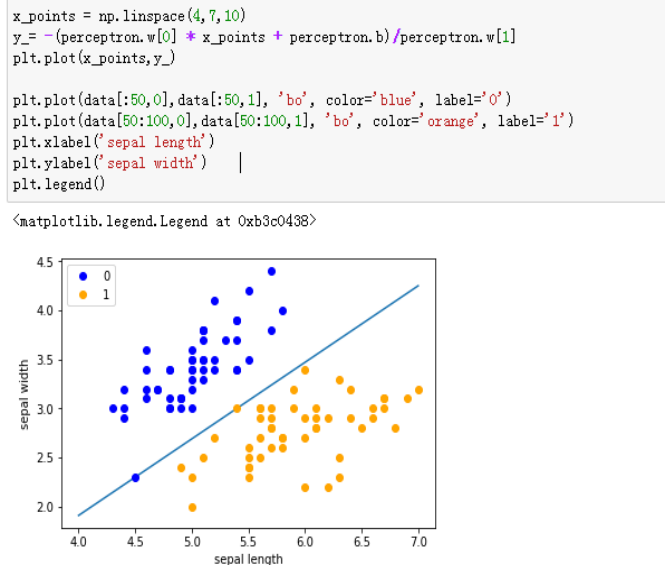
10、代码注释:
绘制模型图像,定义一些基本的信息
x_points = np.linspace(4, 7,10)//x轴的划分
y_ = -(perceptron.w[0]*x_points + perceptron.b)/perceptron.w[1]
plt.plot(x_points, y_)//绘制模型图像(数据、颜色、图例等信息)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
运行截图:
11、代码注释:
from sklearn.linear_model import Perceptron//定义感知机(下面将使用感知机)
运行截图:

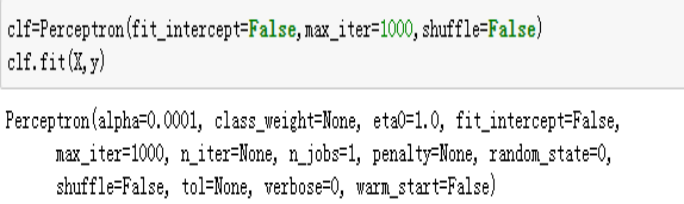
12、代码注释:
clf = Perceptron(fit_intercept=False, max_iter=1000, shuffle=False)
clf.fit(X, y)//使用训练数据拟合
运行截图:
13、代码注释:
%# Weights assigned to the features.
print(clf.coef_)//输出感知机模型参数
运行截图:

14、代码注释:
%# 截距 Constants in decision function.
print(clf.intercept_)//输出感知机模型参数
运行截图:

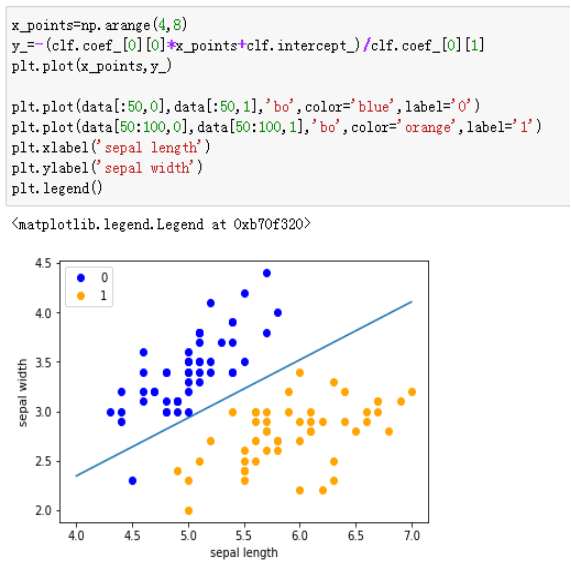
15、代码注释:
x_ponits = np.arange(4, 8)//确定x轴和y轴的值
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)//确定拟合的图像的具体信息(数据点,线,大小,粗细颜色等内容)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
运行截图:
四.实验小结
1.psp表格
| psp2.1 | 任务内容 | 计划完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 200 | 240 |
| Development | 开发 | 100 | 150 |
| Analysis | 需求分析(包括学习新技术) | 30 | 40 |
| Design Spec | 生成设计文档 | 30 | 50 |
| Design Review | 设计复审 | 5 | 15 |
| Coding Standard | 代码规范 | 3 | 10 |
| Design | 具体设计 | 10 | 15 |
| Coding | 具体编码 | 36 | 26 |
| Code Review | 代码复审 | 5 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 9 | 30 |
| Test Report | 测试报告 | 3 | 30 |
| Size Measurement | 计算工作量 | 2 | 10 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 5 | 10 |
2.心得和经验
通过这次实验我充分的初步了解了机器学习这门科目,对此有着深入地认识。理解了感知器的基本算法原理,明白了感知器算法是通过训练模式的迭代和学习算法,产生线性可分的模式判别函数,感知器算法就是通过对训练模式样本集的“学习”得出判别函数的系数解。此次实验我能实现基本的感知器算法,也掌握了最小二乘法进行参数估计基本原理,知道了最小二乘法所得出的多项式,即以拟合曲线的函数来描述自变量与预计应变量的变异数关系。

