内存吞金兽(Elasticsearch)的那些事儿 -- 架构&三高保证
系列目录
内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
内存吞金兽(Elasticsearch)的那些事儿 -- 数据结构及巧妙算法
内存吞金兽(Elasticsearch)的那些事儿 -- 架构&三高保证
内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理
内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
架构图
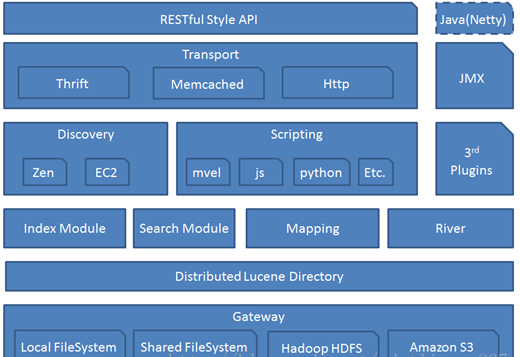
Gateway
代表ElasticSearch索引的持久化存储方式。
在Gateway中,ElasticSearch默认先把索引存储在内存中,然后当内存满的时候,再持久化到Gateway里。当ES集群关闭或重启的时候,它就会从Gateway里去读取索引数据。比如LocalFileSystem和HDFS、AS3等。
DistributedLucene Directory
是Lucene里的一些列索引文件组成的目录。它负责管理这些索引文件。包括数据的读取、写入,以及索引的添加和合并等。
River
代表是数据源。是以插件的形式存在于ElasticSearch中。
Mapping
映射的意思,非常类似于静态语言中的数据类型。比如我们声明一个int类型的变量,那以后这个变量只能存储int类型的数据。
eg:比如我们声明一个double类型的mapping字段,则只能存储double类型的数据。
Mapping不仅是告诉ElasticSearch,哪个字段是哪种类型。还能告诉ElasticSearch如何来索引数据,以及数据是否被索引到等。
Search Moudle
搜索模块
Index Moudle
索引模块
Disvcovery
主要是负责集群的master节点发现。比如某个节点突然离开或进来的情况,进行一个分片重新分片等。
(Zen)发现机制默认的实现方式是单播和多播的形式,同时也支持点对点的实现。以插件的形式存在EC2。
一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Scripting
脚本语言。包括很多。如mvel、js、python等。
定制化功能非常便捷,但有性能问题
Transport
代表ElasticSearch内部节点,代表跟集群的客户端交互。包括 Thrift、Memcached、Http等协议
RESTful Style API
通过RESTful方式来实现API编程。
3rd plugins
第三方插件,(想象一下idea或vscode的插件
Java(Netty)
开发框架。其内部使用netty实现
JMX
监控
部署节点
- master
- index node(也是coordinating node
- coordinating node
三高保证
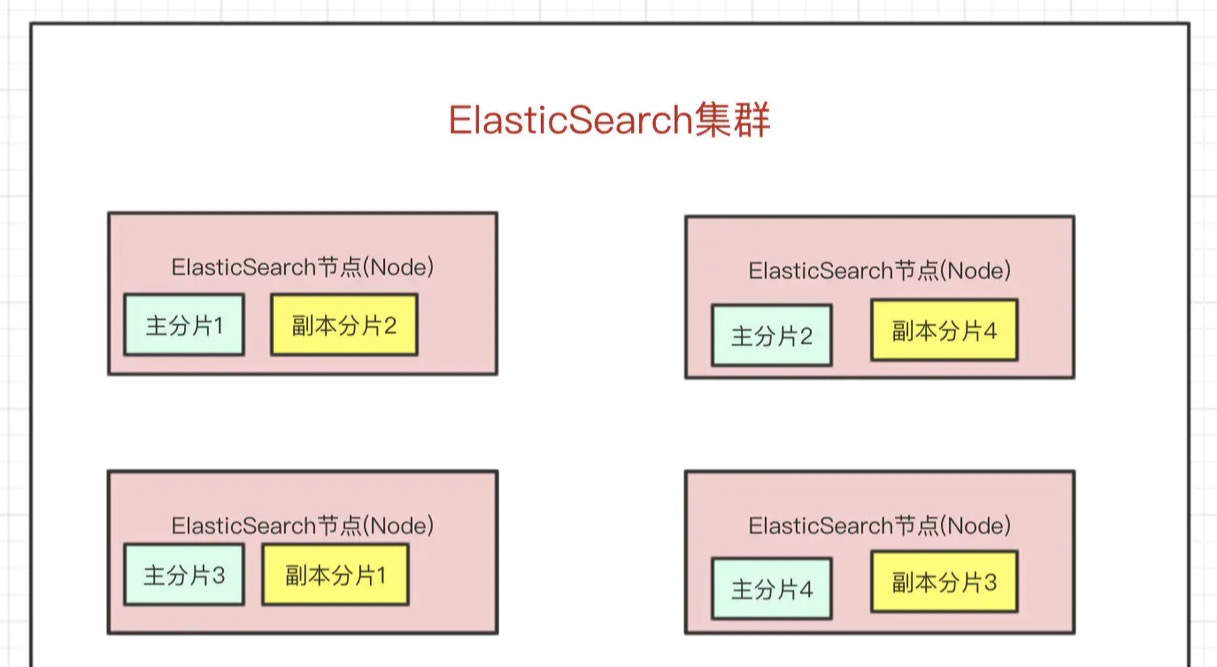
- 一个es集群会有多个es节点
- 在众多的节点中,其中会有一个
Master Node,主要负责维护索引元数据、负责切换主分片和副本分片身份等工作,如果主节点挂了,会选举出一个新的主节点- 如果某个节点挂了,
Master Node就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢。
- 如果某个节点挂了,
- es最外层的是Index(相当于数据库 表的概念);一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片。
- 比如现在我集群里边有4个节点,我现在有一个Index,想将这个Index在4个节点上存储,那我们可以设置为4个分片。这4个分片的数据合起来就是Index的数据
- 分片会有主分片和副本分片之分(防止某个节点宕机,保证高可用)
-
Index需要分为多少个分片和副本分片都是可以通过配置设置的
为什么需要分片?
- 如果一个Index的数据量太大,只有一个分片,那只会在一个节点上存储,随着数据量的增长,一个节点未必能把一个Index存储下来。
- 多个分片,在写入或查询的时候就可以并行操作(从各个节点中读写数据,提高吞吐量)
分词器:
在分词前我们要先明确字段是否需要分词,不需要分词的字段将type设置为keyword,可以节省空间和提高写性能。
1)es的内置分词器
常用的三种分词:Standard Analyzer、Simple Analyzer、whitespace Analyzer
standard 是默认的分析器,英文会按照空格切分,同时大写转小写,中文会按照每个词切分
simple 先按照空格分词,英文大写转小写,不是英文不再分词
Whitespace Analyzer 先按照空格分词,不是英文不再分词,英文不再转小写
2)第三方分词器
es内置很多分词器,但是对中文分词并不友好,例如使用standard分词器对一句中文话进行分词,会分成一个字一个字的。这时可以使用第三方的Analyzer插件,分别是HanLP,IK,Pinyin分词器三种;
- HanLP-面向生产环境的自然语言处理工具包,支持有多重分词配置
两个官网分词例子测试效果,分词效果较内置的分词有很大明显,可以支持中文的词语分词;


- IK分词器:
可以根据粒度拆分
ik_smart: 会做最粗粒度的拆分
ik_max_word: 会将文本做最细粒度的拆分
如果是最细粒度,我是中国人,会被分词为我,是,中国人,中国,国人,相对于Hanlp的分词更加准确和多样;
- PinYin
会对特定的信息进行分词,对用户搜索有更好的体验,该分词会对汉字的首字母进行分词,例如刘德华,会被分词为ldh,张学友,会被分词为zxy,用户根据拼音首字母就可以搜索出对应的特定信息。

