Redis简介 & 与Memcache的区别
redis 是一个基于内存的高性能key-value数据库。
Reids的特点
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。
Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存多种数据结构,此外单个value的最大限制是1GB,不像 memcached只能保存1MB的数据,因此Redis可以用来实现很多有用的功能,比方说用他的List来做FIFO双向链表,实现一个轻量级的高性能消息队列服务,用他的Set可以做高性能的tag系统等等。另外Redis也可以对存入的Key-Value设置expire时间,因此也可以被当作一个功能加强版的memcached来用。
Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
Redis支持的数据类型
Redis通过Key-Value的单值不同类型来区分, 以下是支持的类型:
Strings
Lists
Sets 求交集、并集
Sorted Sethashes
具体的指令说明:http://code.google.com/p/redis/wiki/CommandReference
为什么redis需要把所有数据放到内存中?
Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以redis具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘I/O速度为严重影响redis的性能。在内存越来越便宜的今天,redis将会越来越受欢迎。
如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
另外讲讲内存中的数据如何同步到磁盘
redis在dump数据的时候,是fork子进程。redis的默认配置中,每60秒如果纪录更改数达到1万条就需要dump到硬盘中去,但实际上由于超过了这个数,我们的redis几乎不停地在dump数据到硬盘上;dump数据到硬盘时,我估计为了达到一个原子的效应,避免数据丢失,redis是先把数据dump到一个临时文件,然后重命名为你在配置文件设定的数据文件名.而前面说到,加载数据要1到2分钟,dump数据应该也在1分钟左右吧;dump出来的文件差不多1到2个G;这样,服务器几乎一直保持着每分钟写一个2G的文件的这种IO的负载,磁盘基本不闲着;
Redis是单进程单线程的
redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销
虚拟内存
当你的key很小而value很大时,使用VM的效果会比较好.因为这样节约的内存比较大.
当你的key不小时,可以考虑使用一些非常方法将很大的key变成很大的value,比如你可以考虑将key,value组合成一个新的value.
vm-max-threads这个参数,可以设置访问swap文件的线程数,设置最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的.可能会造成比较长时间的延迟,但是对数据完整性有很好的保证.
自己测试的时候发现用虚拟内存性能也不错。如果数据量很大,可以考虑分布式或者其他数据库
分布式
redis支持主从的模式。原则:Master会将数据同步到slave,而slave不会将数据同步到master。Slave启动时会连接master来同步数据。
这是一个典型的分布式读写分离模型。我们可以利用master来插入数据,slave提供检索服务。这样可以有效减少单个机器的并发访问数量
读写分离模型
通过增加Slave DB的数量,读的性能可以线性增长。为了避免Master DB的单点故障,集群一般都会采用两台Master DB做双机热备,所以整个集群的读和写的可用性都非常高。
读写分离架构的缺陷在于,不管是Master还是Slave,每个节点都必须保存完整的数据,如果在数据量很大的情况下,集群的扩展能力还是受限于单个节点的存储能力,而且对于Write-intensive类型的应用,读写分离架构并不适合。
数据分片模型
为了解决读写分离模型的缺陷,可以将数据分片模型应用进来。
可以将每个节点看成都是独立的master,然后通过业务实现数据分片。
结合上面两种模型,可以将每个master设计成由一个master和多个slave组成的模型。
redis的性能
这是官方给出的数据:SET操作每秒钟 110000 次,GET操作每秒钟 81000 次。
实验中模拟了20个客户端对redis进行写操作。当数据库中的数据达到G数据级时,写速度会有明显的下降。
可能的原因: 1、redis需要将数据同步到磁盘,占用了大量的CPU和内存; 2、key数量增大,需要重新布局; 3、消息队列中还存在大量请求,致使请求阻塞。
redis应用
这里给出一个小例子,是一个基于redis的消息队列。
python源码:
- r = redis.Redis()
- class Queue(object):
- """An abstract FIFO queue"""
- def __init__(self):
- local_id = r.incr("queue_space")
- id_name = "queue:%s" %(local_id)
- self.id_name = id_name
- def push(self, element):
- """Push an element to the tail of the queue"""
- id_name = self.id_name
- push_element = redis.lpush(id_name, element)
- def pop(self):
- """Pop an element from the head of the queue"""
- id_name = self.id_name
- popped_element = redis.rpop(id_name)
- return popped_element
二.分布式缓存的架构设计
1.架构设计
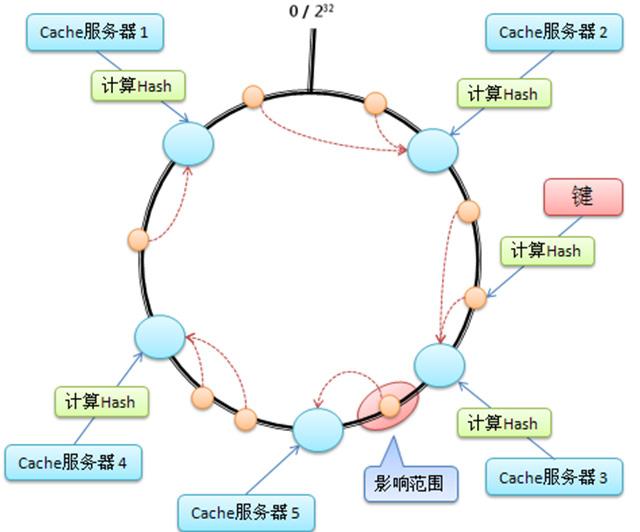
由于redis是单点,项目中需要使用,必须自己实现分布式。基本架构图如下所示:
1. Redis是什么
这个问题的结果影响了我们怎么用Redis。如果你认为Redis是一个key value store, 那可能会用它来代替MySQL;如果认为它是一个可以持久化的cache, 可能只是它保存一些频繁访问的临时数据。Redis是REmote DIctionary Server的缩写,在Redis在官方网站的的副标题是A persistent key-value database with built-in net interface written in ANSI-C for Posix systems,这个定义偏向key value store。还有一些看法则认为Redis是一个memory database,因为它的高性能都是基于内存操作的基础。另外一些人则认为Redis是一个data structure server,因为Redis支持复杂的数据特性,比如List, Set等。对Redis的作用的不同解读决定了你对Redis的使用方式。
互联网数据目前基本使用两种方式来存储,关系数据库或者key value。但是这些互联网业务本身并不属于这两种数据类型,比如用户在社会化平台中的关系,它是一个list,如果要用关系数据库存储就需要转换成一种多行记录的形式,这种形式存在很多冗余数据,每一行需要存储一些重复信息。如果用key value存储则修改和删除比较麻烦,需要将全部数据读出再写入。Redis在内存中设计了各种数据类型,让业务能够高速原子的访问这些数据结构,并且不需要关心持久存储的问题,从架构上解决了前面两种存储需要走一些弯路的问题。
2. Redis不可能比Memcache快
很多开发者都认为Redis不可能比Memcached快,Memcached完全基于内存,而Redis具有持久化保存特性,即使是异步的,Redis也不可能比Memcached快。但是测试结果基本是Redis占绝对优势。一直在思考这个原因,目前想到的原因有这几方面。
Libevent。和Memcached不同,Redis并没有选择libevent。Libevent为了迎合通用性造成代码庞大(目前Redis代码还不到libevent的1/3)及牺牲了在特定平台的不少性能。Redis用libevent中两个文件修改实现了自己的epoll event loop(4)。业界不少开发者也建议Redis使用另外一个libevent高性能替代libev,但是作者还是坚持Redis应该小巧并去依赖的思路。一个印象深刻的细节是编译Redis之前并不需要执行./configure。
CAS问题。CAS是Memcached中比较方便的一种防止竞争修改资源的方法。CAS实现需要为每个cache key设置一个隐藏的cas token,cas相当value版本号,每次set会token需要递增,因此带来CPU和内存的双重开销,虽然这些开销很小,但是到单机10G+ cache以及QPS上万之后这些开销就会给双方相对带来一些细微性能差别(5)。
3. 单台Redis的存放数据必须比物理内存小
Redis的数据全部放在内存带来了高速的性能,但是也带来一些不合理之处。比如一个中型网站有100万注册用户,如果这些资料要用Redis来存储,内存的容量必须能够容纳这100万用户。但是业务实际情况是100万用户只有5万活跃用户,1周来访问过1次的也只有15万用户,因此全部100万用户的数据都放在内存有不合理之处,RAM需要为冷数据买单。
这跟操作系统非常相似,操作系统所有应用访问的数据都在内存,但是如果物理内存容纳不下新的数据,操作系统会智能将部分长期没有访问的数据交换到磁盘,为新的应用留出空间。现代操作系统给应用提供的并不是物理内存,而是虚拟内存(Virtual Memory)的概念。
基于相同的考虑,Redis 2.0也增加了VM特性。让Redis数据容量突破了物理内存的限制。并实现了数据冷热分离。
4. Redis的VM实现是重复造轮子
Redis的VM依照之前的epoll实现思路依旧是自己实现。但是在前面操作系统的介绍提到OS也可以自动帮程序实现冷热数据分离,Redis只需要OS申请一块大内存,OS会自动将热数据放入物理内存,冷数据交换到硬盘,另外一个知名的“理解了现代操作系统(3)”的Varnish就是这样实现,也取得了非常成功的效果。
作者antirez在解释为什么要自己实现VM中提到几个原因(6)。主要OS的VM换入换出是基于Page概念,比如OS VM1个Page是4K, 4K中只要还有一个元素即使只有1个字节被访问,这个页也不会被SWAP, 换入也同样道理,读到一个字节可能会换入4K无用的内存。而Redis自己实现则可以达到控制换入的粒度。另外访问操作系统SWAP内存区域时block进程,也是导致Redis要自己实现VM原因之一。
5. 用get/set方式使用Redis
作为一个key value存在,很多开发者自然的使用set/get方式来使用Redis,实际上这并不是最优化的使用方法。尤其在未启用VM情况下,Redis全部数据需要放入内存,节约内存尤其重要。
假如一个key-value单元需要最小占用512字节,即使只存一个字节也占了512字节。这时候就有一个设计模式,可以把key复用,几个key-value放入一个key中,value再作为一个set存入,这样同样512字节就会存放10-100倍的容量。
这就是为了节约内存,建议使用hashset而不是set/get的方式来使用Redis,详细方法见参考文献(7)。
6. 使用aof代替snapshot
Redis有两种存储方式,默认是snapshot方式,实现方法是定时将内存的快照(snapshot)持久化到硬盘,这种方法缺点是持久化之后如果出现crash则会丢失一段数据。因此在完美主义者的推动下作者增加了aof方式。aof即append only mode,在写入内存数据的同时将操作命令保存到日志文件,在一个并发更改上万的系统中,命令日志是一个非常庞大的数据,管理维护成本非常高,恢复重建时间会非常长,这样导致失去aof高可用性本意。另外更重要的是Redis是一个内存数据结构模型,所有的优势都是建立在对内存复杂数据结构高效的原子操作上,这样就看出aof是一个非常不协调的部分。
其实aof目的主要是数据可靠性及高可用性,在Redis中有另外一种方法来达到目的:Replication。由于Redis的高性能,复制基本没有延迟。这样达到了防止单点故障及实现了高可用。
小结
要想成功使用一种产品,我们需要深入了解它的特性。Redis性能突出,如果能够熟练的驾驭,对国内很多大型应用具有很大帮助。
【Redis与Memcache的区别】
memcache官方定义
Free & open source, high-performance, distributed memory object caching system, generic in nature, but intended for use in speeding up dynamic web applications by alleviating database load.
redis官方定义
Redis is an open source, BSD licensed, advanced key-value store. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
版权相同
它们都是使用的bsd协议,使用它的项目可以用于商业用户,不必发布二次修改的代码,可以修改源代码。
数据类型
redis数据类型丰富,支持set liset等类型
memcache支持简单数据类型,需要客户端自己处理复杂对象
持久性
redis支持数据落地持久化存储
memcache不支持数据持久存储
分布式存储
redis支持master-slave复制模式
memcache可以使用一致性hash做分布式
value大小不同
memcache是一个内存缓存,key的长度小于250字符,单个item存储要小于1M,不适合虚拟机使用
数据一致性不同
redis使用的是单线程模型,保证了数据按顺序提交。
memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作。
cpu利用
redis单线程模型只能使用一个cpu,可以开启多个redis进程
为何Redis要比Memcached好用
【http://blog.csdn.net/renfufei/article/details/40598889】
副标题: Redis是新兴的通用存储系统,而Memcached仍有其适用领域
Memcached还是Redis? 在现代高性能Web应用中这一直是个争论不休的话题。 在基于关系型数据库的Web应用需要提高性能时,使用缓存是绝大多数架构师的第一选择,自然,Memcached和Redis通常是优先选择。
共同特征
- 都是 key-value 形式的内存数据库
- 都是NoSQL家族的数据管理解决方案
- 都基于同样的key-value 数据模型
- 所有数据全部放在内存中(这也是适用于缓存的原因)
- 性能得分不分伯仲,包括数据吞吐量和延迟等指标
- 都是成熟的、广受开源项目欢迎的 key-value存储系统
Memcached最初在2003年由 Brad Fitzpatrick 为 LiveJournal网站开发。然后又用C语言重写了一遍(初版为Perl实现),并开放给公众使用,从此成为现代Web系统开发的基石。 当前Memcached的发展方向是改进稳定性和性能优化,而不是添加新功能特性。
Redis于2009年由 Salvatore Sanfilippo 创建, 直到今天 Sanfilippo 依然是Redis的唯一开发者和代码维护者。 Redis也被称为 "Memcached增强版(Memcached on steroids)", 这一点也不令人惊讶, 因为 Redis 有一部分就是在 Memcached 的经验总结之上构建的的。 Redis比Memcached具有更多的功能特性,这使得它更灵活,更强大也更复杂。
Memcached和Redis被众多企业以及大量生产系统所采用, 支持各种语言开发的客户端,有丰富的SDK。 事实上, 在上点规模的互联网Web开发语言中,基本上没有不支持Memcached或Redis的。
为什么Memcached和Redis如此流行? 不仅是其具有超高的性能,还因为相对来说他们都非常简单。 对程序员来说上手使用Memcached或Redis相当容易。 安装和设置并集成到系统中可能只需要几分钟时间。 因此花费一点点时间和精力就能立刻大幅提升系统性能 —— 通常是提升一个数量级。 一个简洁的解决方案却能获得巨大的性能收益: 这酸爽简直超乎你的想象。
Memcached 适用场景
因为Redis是新兴解决方案,提供了更多的功能特性,比起Memcached来说, Redis一般都是更好的选择。 在两个特定场景下Memcached可能是更好的选择。
第一种是很细碎的静态数据,如HTML代码片段。 Memcached的内存管理不像Redis那么复杂,所以性能更高一些,原因是Memcached 的元数据metadata更小,相对来说额外开销就很少。 Memcached唯一支持的数据类型是字符串 String,非常适合缓存只读数据,因为字符串不需要额外的处理。
第二个场景,是Memcached比Redis更容易水平扩展。 原因在于它的设计和和功能很简单,Memcached更容易扩展。 消息显示, Redis在即将到来的3.0版(阅读CA版本发布笔记)将内置可靠的集群支持[但一直在跳票]。
Redis 用武之地
除非受环境制约(如遗留系统),或者业务符合上面的2种情况,否则你应该优先选择Redis。 使用Redis作为缓存,通过调优缓存内容,系统效率能获得极其提升。
很明显Redis的优势在于缓存管理。 缓存通过某种数据回收机制(data eviction mechanism)在必要时将旧数据从内存中删除,为新数据腾出空间。 Memcached的数据回收机制使用LRU(Least Recently Used,最近最少使用)算法,同时优先清除与新数据大小差不多的旧数据块。 相比之下,Redis允许细粒度控制过期缓存,有6种不同的策略可供选择。 Redis还采用了一些更复杂的内存管理方法和回收策略。
Redis对缓存的对象提供更大的灵活性。 而Memcached限制 key 为250字节,限制 value 为1 MB,且只能通过纯文本String通信. Redis的 key 和 value 大小限制都是512 MB,是二进制安全的【即不丢数据,与编码无关】。 Redis提供6种数据类型,使缓存以及管理缓存变得更加智能和方便,为应用程序开发者打开了一个无限可能的世界。
相比将对象序列化后通过字符串存储, Redis 通过 Hash来存储一个对象的字段和值,并可以通过单个key来管理它们。
看看用Memcached更新一个对象需要干什么:
- 获取整个字符串
- 反序列化为对象
- 修改其中的值
- 再次序列化该对象
- 在缓存中将整个字符串替换为新字符串
并且每次更新都要干这些破事。
而使用Redis Hash的方式, 可以大幅度降低资源消耗并提高性能。 Redis的其他数据类型,如List 或者 Set,可用来实现更复杂的缓存管理模式。
Redis的另一个重大优点是其存储的数据是不透明的,这意味着在服务器端可以直接操纵这些数据。 160多个命令中的大部分都可以用来进行数据操作, 所以通过服务端脚本调用进行数据处理成为现实。 这些内置命令和用户脚本可以让你直接灵活地处理数据任务,而无需通过网络将数据传输给另一个系统进行处理。
Redis提供了可选/可调整的数据持久化, 目的是为了在 崩溃/重启后可以快速加载缓存。 虽然我们一般认为缓存中的数据是不稳定,瞬时的, 但在缓存系统中将数据持久化到磁盘还是很有价值的。 在重启后立即加载预热的方式耗时很短, 而且减轻了主数据库系统的开销。
最后, Redis提供主从复制(replication)。 Replication 可用于实现高可用的cache系统,允许某些服务器宕机的情况下也能提供不间断的服务。 假设要求在某台缓存服务器崩溃时, 只有少部分用户和程序在短时间内受影响, 大多数情况下就需要有一个行之有效的解决方案,来保证缓存内容和服务的可用性。
当今开源软件一直在提供最佳的实用技术方案。 需要使用缓存来提高应用系统性能时,Redis和Memcached是最佳的产品级解决方案。 但考虑到其丰富的功能和先进的设计,绝大多数时候Redis都应该是你的第一选择。
作者简介: Itamar Haber (@itamarhaber) 是 Redis Labs的首席开发人员, 该企业为开发人员提供完全托管的Memcached和Redis云服务。 具有多年软件产品研发经验,曾在 Xeround, Etagon, Amicada, and M.N.S Ltd.担任管理和领导职位. Itamar 获得 Northwestern and Tel-Aviv Universitiesd 的Kellogg-Recanati工商管理硕士, 以及 Science in Computer Science 学士。
相关阅读:
- 用Memcached提升Java企业应用性能,Part 1:体系结构和配置
- 用Memcached提升Java企业应用性能,Part 2:基于数据库的webApp
- Cache之争: Azure和AWS升级缓存服务
原文链接: Why Redis beats Memcached for caching
原文日期: 2014-10-15
翻译日期: 2014-10-23
翻译人员: 铁锚

 浙公网安备 33010602011771号
浙公网安备 33010602011771号