NDGD团队(四)
分别按照工作分配 即 淘宝(刘) 京东(高) 苏宁(胡)开展工作
开始进展顺利 之后出现问题
淘宝 京东请求次数过多会触发反爬机制一时间陷入僵局

添加如上伪装头后解决问题
苏宁相对简单 但是一页商品120个 直接爬取html只能爬取30个 即HTML里只有30个商品信息
百度之后 发现可能是异步加载的问题
然后苏宁(胡)发现 selenium可以解决这个问题开始学习selenium
苏宁(胡)在奋斗之后
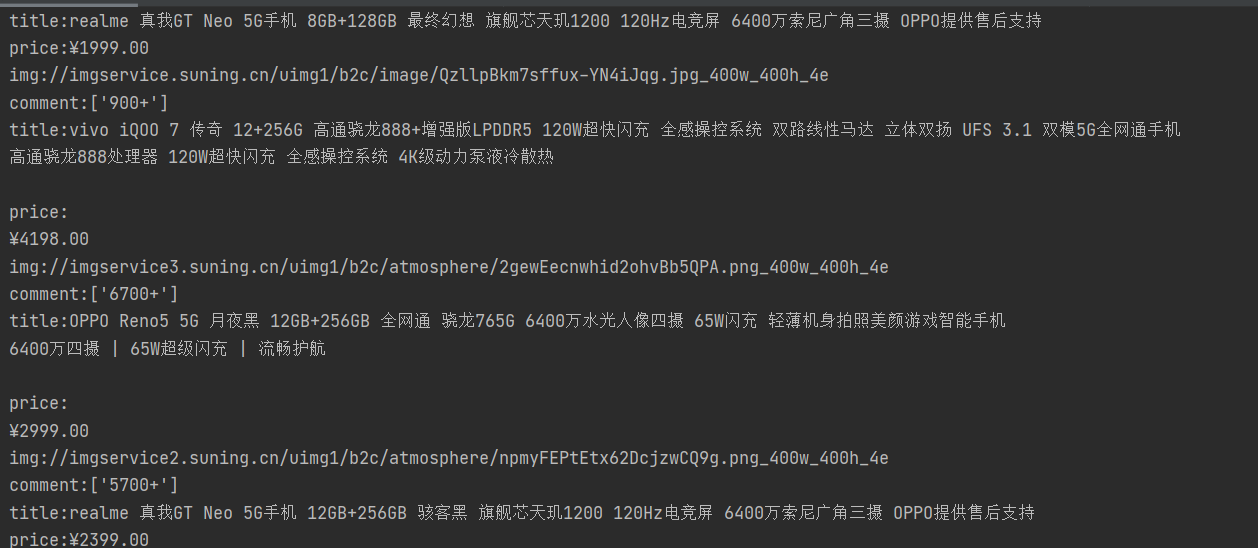
写出了代码
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import time
from lxml import etree
def wait_download(page, maxpage):
# wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'item-bg')))
js = 'window.scrollTo(0,document.body.scrollHeight)'
driver.execute_script(js)
time.sleep(5)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'item-bg')))
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'def-price')))
html = driver.page_source
if maxpage == 0:
spage = etree.HTML(html)
maxpage = int(spage.xpath('//div[@class="search-page page-fruits clearfix"]/a/@pagenum')[4])
print("最大页数为:"+str(maxpage))
parse_html(html)
page += 1
next_page(page, maxpage)
# 翻页
def next_page(num, maxpage):
if num <= maxpage:
page = wait.until(EC.presence_of_element_located((By.ID, 'bottomPage')))
page.send_keys(num)
time.sleep(3)
button = wait.until(EC.element_to_be_clickable((By.NAME, 'ssdsn_search_bottom_page')))
button.click()
wait_download(num, maxpage)
print("第"+str(num)+"完成")
def parse_html(reponse):
selector = etree.HTML(reponse)
items = selector.xpath('//div[@class="item-bg"]')
print("==================="+len(items)+"===================")
for item in items:
print('title:{}'.format(item.xpath('.//div[1]/div[2]/div[2]/a')[0].xpath('string(.)')))
print('price:{}'.format(item.xpath('.//div[1]/div[2]/div[1]/span')[0].xpath('string(.)')))
print('img:{}'.format(item.xpath('.//div[1]/div[1]/div[1]/a/img/@src')[0]))
print('comment:{}'.format(item.xpath('.//div[@class="info-evaluate"]/a/i/text()')))
def start_search(key):
# 定位输入框 输入数据 点击搜索
_input = wait.until(EC.presence_of_element_located((By.ID, 'searchKeywords')))
_input.send_keys(key)
submit = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'search-btn')))
submit.click()
# ma = driver.find_elements(By.NAME, '')
maxpage = 0
wait_download(48, maxpage)
if __name__ == '__main__':
driver = webdriver.Chrome(r'E:\chrome\chromedriver.exe') # r'E:\chrome\chromedriver.exe'
driver.maximize_window()
driver.get('http://www.suning.com/')
wait = WebDriverWait(driver, 20)
start_search("手机")