"""
我们可以试着查看源码
"""
1、语法结构
'''{{ 数据对象|过滤器名称:参数 }}'''
过滤器只能额外传一个参数
2、常见过滤器(django模板语法提供60+的顾虑器种类)
def index(request):
l1 = 'h e l l o 你 是 t w o 臂 吗'
n1 = 111
file_size = 7328
file_size1 = 43875380
b = False
from datetime import datetime
d = datetime.today()
l2 = '你 好 哇 窝 似 泥 叠 '
l3 = '枯|藤|老|树|昏|鸦'
tag1 = '<h1>这是一个h1标签</h1>'
scripts1 = '<script>alert(123)</script>'
from django.utils.safestring import mark_safe
ttt = '<a href="http://www.7k7k.com"> 小朋友快来玩啊</a>'
res = mark_safe(ttt)
return render(request, 'index.html', locals())
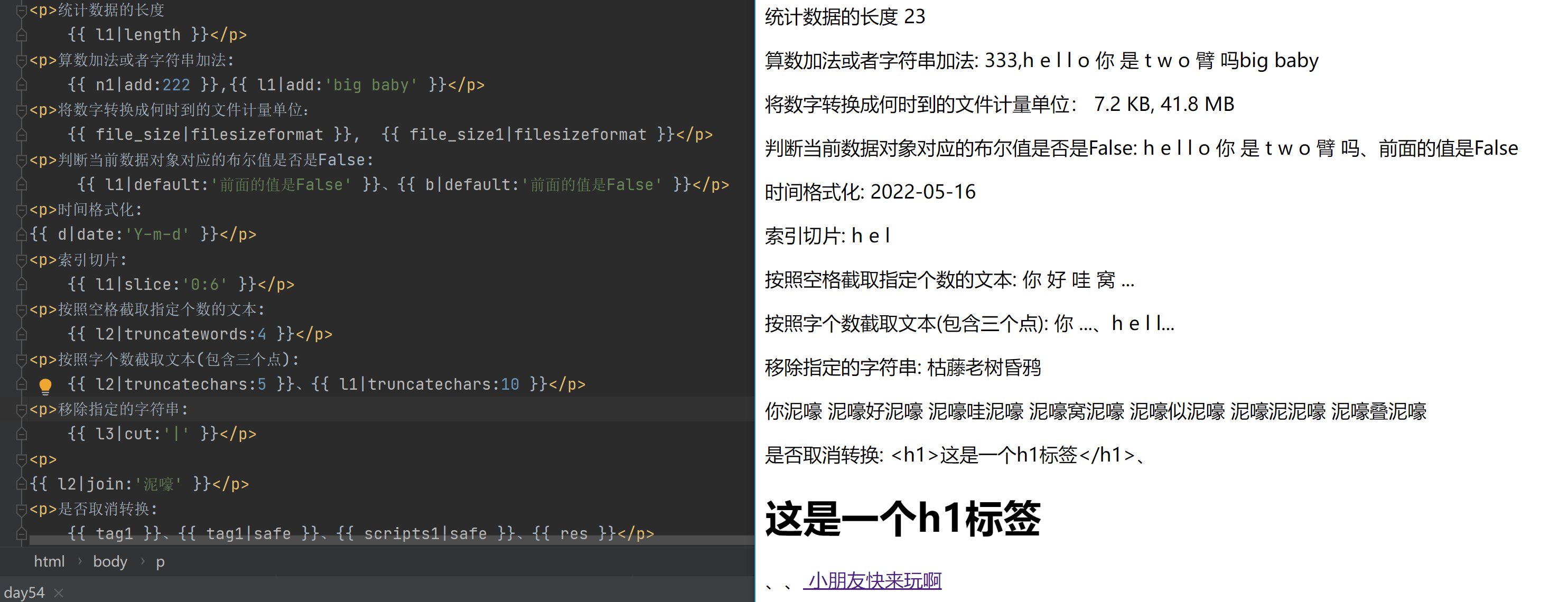
<p>统计数据的长度
{{ l1|length }}</p>
<p>算数加法或者字符串加法:
{{ n1|add:222 }},{{ l1|add:'big baby' }}</p>
<p>将数字转换成何时到的文件计量单位:
{{ file_size|filesizeformat }}, {{ file_size1|filesizeformat }}</p>
<p>判断当前数据对象对应的布尔值是否是False:
{{ l1|default:'前面的值是False' }}、{{ b|default:'前面的值是False' }}</p>
<p>时间格式化:
{{ d|date:'Y-m-d' }}</p>
<p>索引切片:
{{ l1|slice:'0:6' }}</p>
<p>按照空格截取指定个数的文本:
{{ l2|truncatewords:4 }}</p>
<p>按照字个数截取文本(包含三个点):
{{ l2|truncatechars:5 }}、{{ l1|truncatechars:10 }}</p>
<p>移除指定的字符串:
{{ l3|cut:'|' }}</p>
<p>
{{ l2|join:'泥嚎' }}</p>
<p>是否取消转换:
{{ tag1 }}、{{ tag1|safe }}、{{ scripts1|safe }}、{{ res }}</p>
# 最后一个|safe启发 我们以后用Django开发全栈项目前端页面代码(主要是指HTML代码) 也可以在后端编写
"""
django模板语法中写标签的时候,只需要写关键字然后tab键就会自动补全
"""
1、语法结构
{% 名字 ... %}
{% end名字 %}
2、if 判断
{% if 条件1 %}
<p>泥嚎</p>
{% elif 条件2 %}
<p>窝不好</p>
{% else %}
<p>嘿嗨嘿</p>
{% endif %}
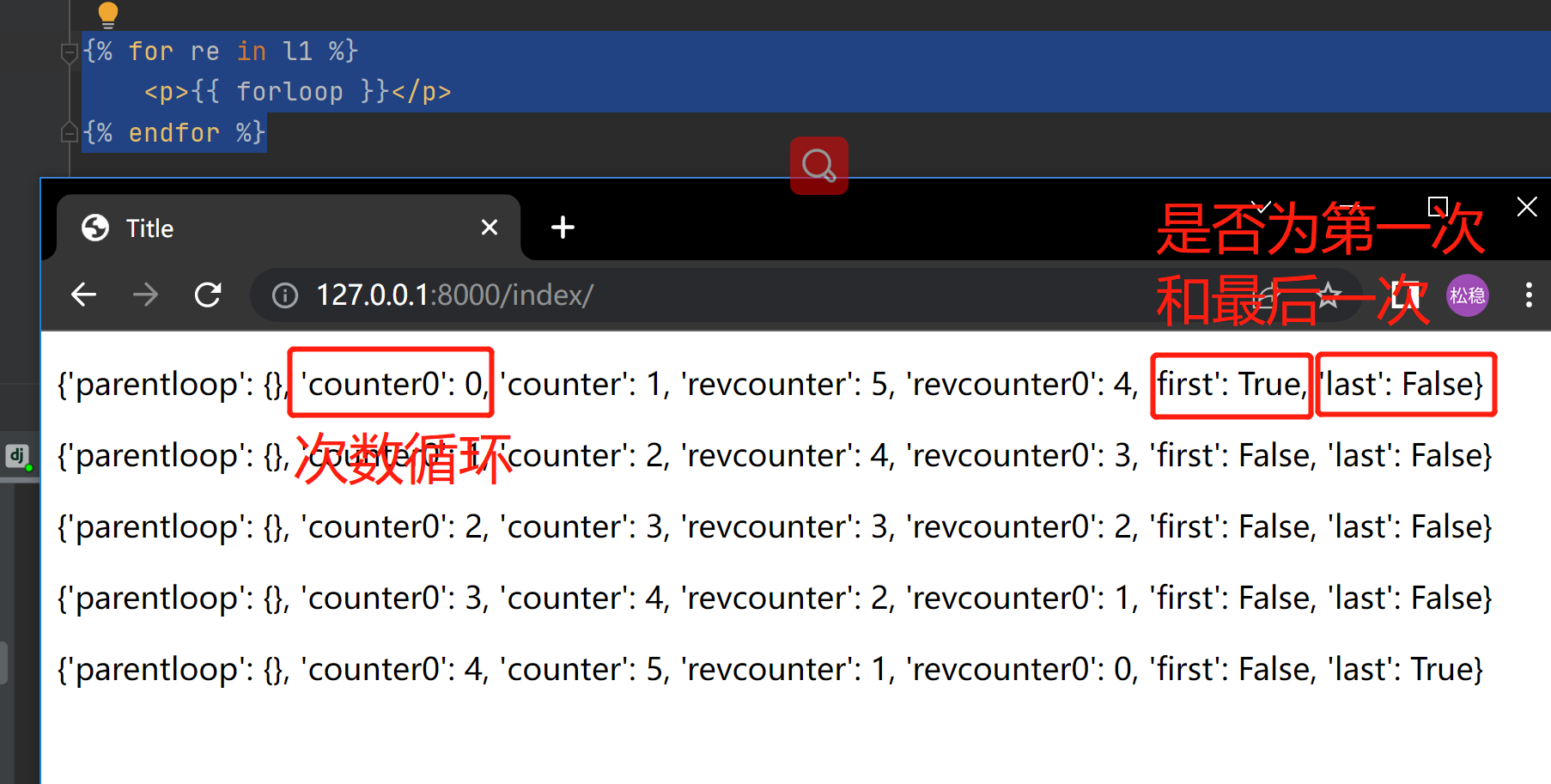
3、for循环
l1 = [11,22, 33, 44, 55]
{% for re in l1 %}
<p>{{ forloop }}</p>
{% endfor %}
# forloop对象
{'parentloop': {}, 'counter0': 0, 'counter': 1, 'revcounter': 4, 'revcounter0': 3, 'first': True, 'last': False}
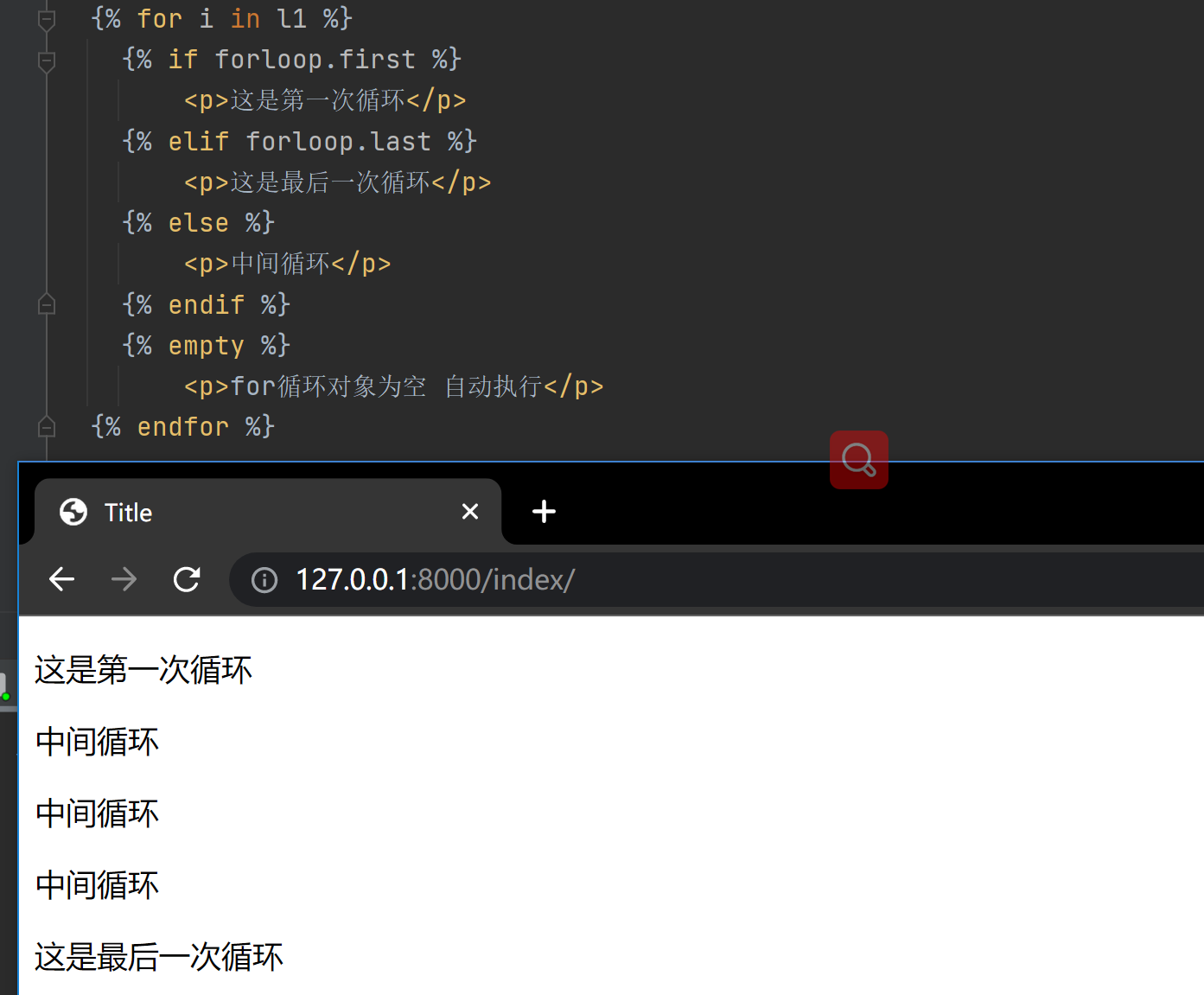
4、for + if 使用
{% for i in l1 %}
{% if forloop.first %}
<p>这是第一次循环</p>
{% elif forloop.last %}
<p>这是最后一次循环</p>
{% else %}
<p>中间循环</p>
{% endif %}
{% empty %}
<p>for循环对象为空 自动执行</p>
{% endfor %}
"""
1、在应用下需要创建一个名为templatetags的文件夹
2、在该文件夹内创建一个任意名称的py文件
3、在该py文件内需要先提前编写两行固定的代码
from django import template
register = template.Library()
"""
# 自定义过滤器 只能接收两个参数
@register.filter(is_safe=True)
def index(a, b):
return a + b
# 自定义简单标签:接收任意的参数
@register.simple_tag(name='my_tag')
def func1(a, b, c, d):
return a + b + c + d
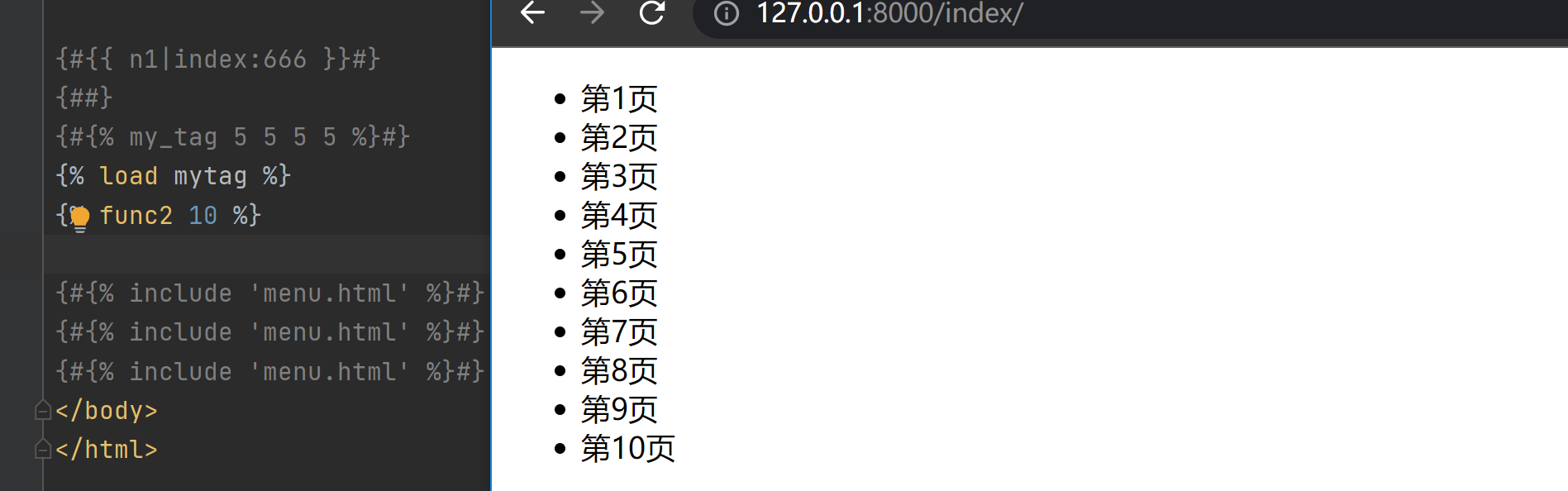
# 自定义inclusion_tag
@register.inclusion_tag('left.html')
def func2(n):
l1 = []
for i in range(1, n + 1):
l1.append(f'第{i}页')
return locals()
# left 页面
<ul>
{% for foo in l1 %}
<li>{{ foo }}</li>
{% endfor %}
</ul>
# index页面
{% load mytag %}
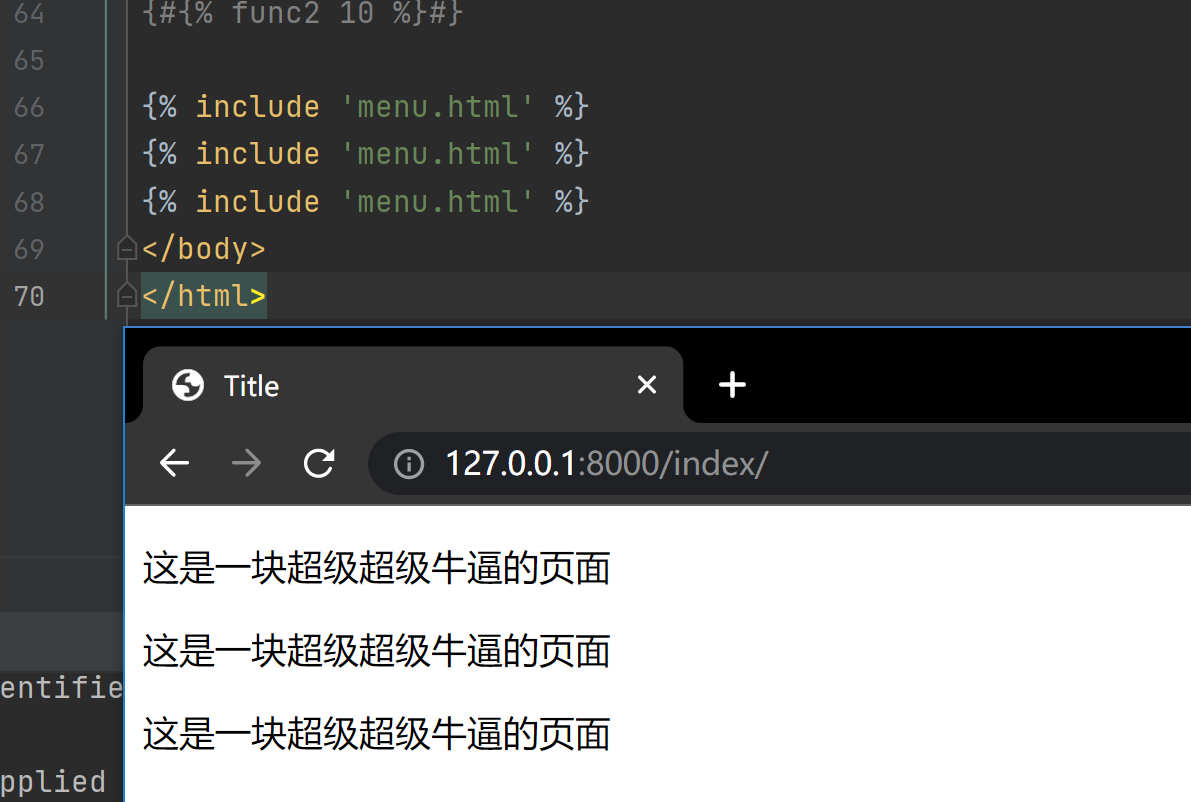
{% func2 10 %}
'''该方法需要先作用于一个局部html页面 之后将渲染的结果放到调用的位置'''
# 类似于将html页面上的局部页面做成模块的形式 哪个地方想要直接导入即可展示
方法一: 直接拷贝
方法二: 模板的导入
使用方式
{% include 'menu.html' %}
{##} 是django模板语法的注释
"""
HTML的注释可以在前端浏览器页面上直接查看到
模板语法的注释只能在后端查看 前端浏览器查看不了
"""
# 类似于面向对象的继承:继承了某个页面就可以使用该页面上所有的资源
1.先在模板中通过block划定将来可以被修改的区域
{% block content %}
<h1>主页内容</h1>
{% endblock %}
2.子板继承模板
{% extends 'home.html' %}
3.修改划定的区域
{% block content %}
<h1>登录内容</h1>
{% endblock %}
4.子页面还可以重复使用父页面的内容
{{ block.super }}
"""
模板上最少应该有三个区域
css区域、内容区域、js区域
子页面就可以有自己独立的css、js、内容
"""
"""
django自带的sqlite3数据库 功能很少 并且针对日期类型不精确
1.数据库正向迁移命令(将类操作映射到表中)
python3 manage.py makemigrations
python3 manage.py migrate
2.数据库反向迁移命令(将表映射成类)
python3 manage.py inspectdb
"""
1、搭建专门的测试环境
import os
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day54.settings")
import django
django.setup()
# 还有一种pycharm提供的
最下面的:Python console
all()
查看所有的数据
filter()
括号不写条件相当于all(),写了相当于where
filter(pk=1)
使通过主键筛选数据,写pk会自动定位当前的主键字段
models.User.objects.filter().filter().filter().filter()
只要是QuerySet对象 就可以一直点 链式操作
res = models.User.objects.all()
# 查询所有的数据 可以看成列表套对象 [<User: User object>, <User: User object>...]
res = models.User.objects.filter()
# 括号内填写筛选条件,不写相当于all [<User: 对象:owen>, <User: 对象:gavin>, <User: 对象:oscar>]
res = models.User.objects.filter(pk=1)
# 使通过主键筛选数据,写pk会自动定位当前的主键字段
res = models.User.objects.filter(pk=1).first()
# .first() 第一个对象 推荐使用
res = models.User.objects.filter(pk=1, name='gavin').first()
# 不存在返回None 可以写多个条件,并且默认为and关系
res=models.User.objects.filter().filter().filter()
# 只要是QuerySet对象,就可以一直点,链式操作
res = models.User.objects.filter().last()
# 结果集中最后一个对象
res = models.User.objects.all().values('name')
# QuerySet对象 列表套字典 指定字段,all可以不用写
res = models.User.objects.all().values_list('name') # 结果列表套元组 获取对象的name
res = models.User.objects.all().distinct()
# 去重操作distinct(), 数据如果包含主键,不能去重
res = models.User.objects.values('name').distinct()
# 因为去重要求数据全部一模一样,所以用名字来去重
res = models.User.objects.order_by('age')
# 通过年龄排序,默认升序order_by
res = models.User.objects.order_by('-age')
# 可以改为降序
res = models.User.objects.order_by('age','pk')
# 支持多个字段
res = models.User.objects.exclude(name='gavin')
# 取反操作exclude
res = models.User.objects.reverse()
# reverse 不起作用,只能在order_by 排序之后使用
res = models.User.objects.count()
# .count() 统计结果集的个数 7
res = models.User.objects.get(pk=1)
# 直接获取对象
res = models.User.objects.get(pk=120) # 对象不存在则报错 so不推荐使用,直接filter


