having和where的功能是一样的,都是对数据进行判断和筛选
where 用在分组之前
having 用于分组之后的筛选
所以我们把where说成筛选,having说成过滤
eg:
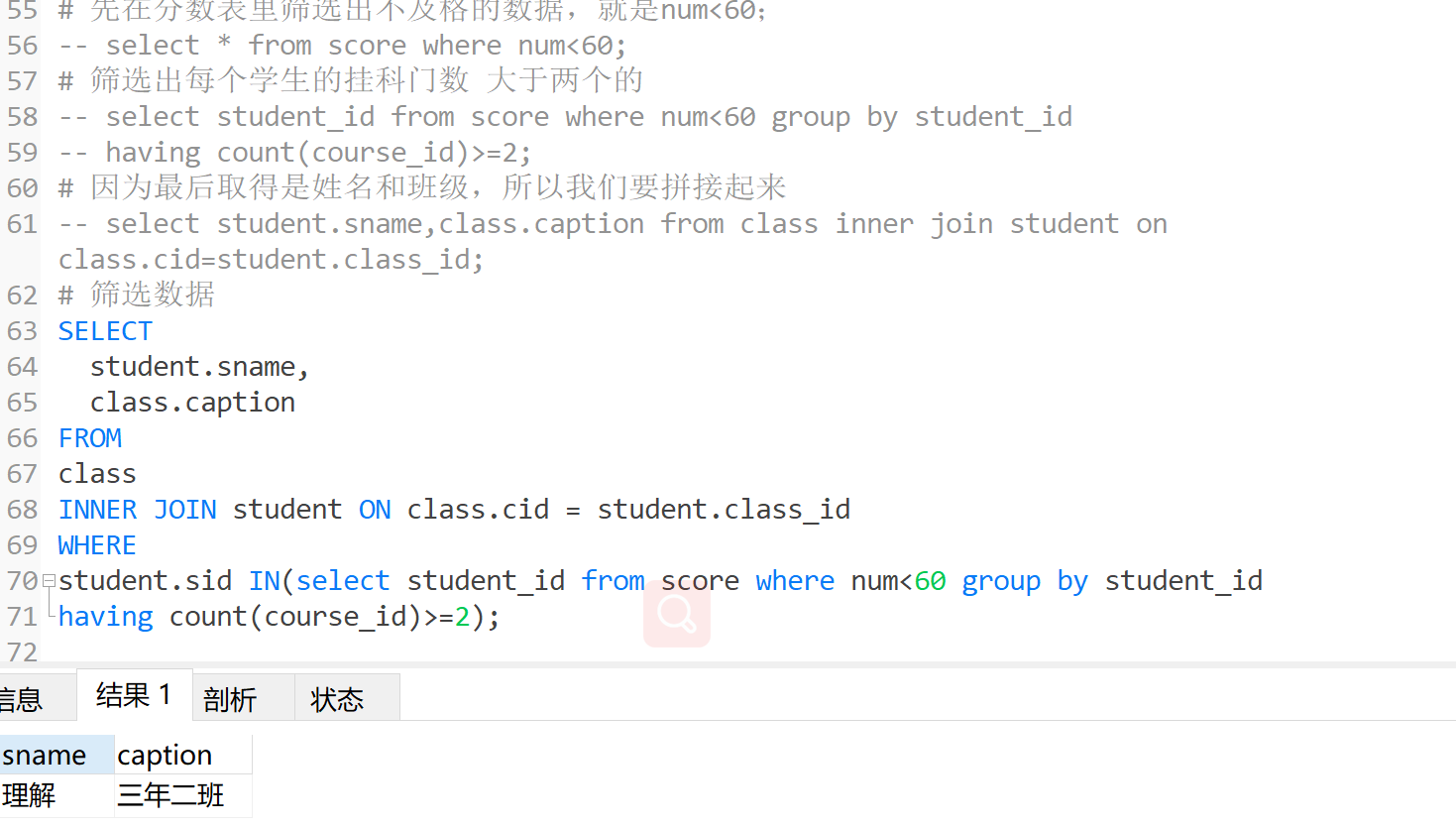
统计每个部门年龄在30岁以上的员工的平均薪资并且保留平均薪资大于10000的部门
# 1、先获取每个部门年龄在30岁以上的员工的平均薪资
select post,avg(salary) from gjz where age>30 group by post;
+---------+---------------+
| post | avg(salary) |
+---------+---------------+
| sale | 2500.240000 |
| teacher | 255450.077500 |
+---------+---------------+
# 2、在过滤出平均薪资大于10000的数据
分组之后,我们就要使用having
select post,avg(salary) from gjz
where age>30
group by post
having avg(salary) > 10000;
+---------+---------------+
| post | avg(salary) |
+---------+---------------+
| teacher | 255450.077500 |
+---------+---------------+
'''
针对聚合函数,如果还需要在其他地方作为条件使用,可以起别名
'''
select post,avg(salary) as avg_salary from gjz
where age>30
group by post
having avg_salary > 10000;
# 我们去重的前提,数据必须是一模一样的才可以(如果数据有主键那肯定是无法去重的)
select distinct age from ll;
# 排序关键字
order ... asc --- 升序(默认为升序,要升序就不用写)
order ... desc --- 降序(从大到小)
# 按照薪资的高低排序
# 升序
select * from gjz order by salary;
# 降序
select * from gjz order by salary desc;
# 先按照年升序排列,当年龄相同时,就按照薪资降序排序
select * from gjz order by age asc,
salary desc;
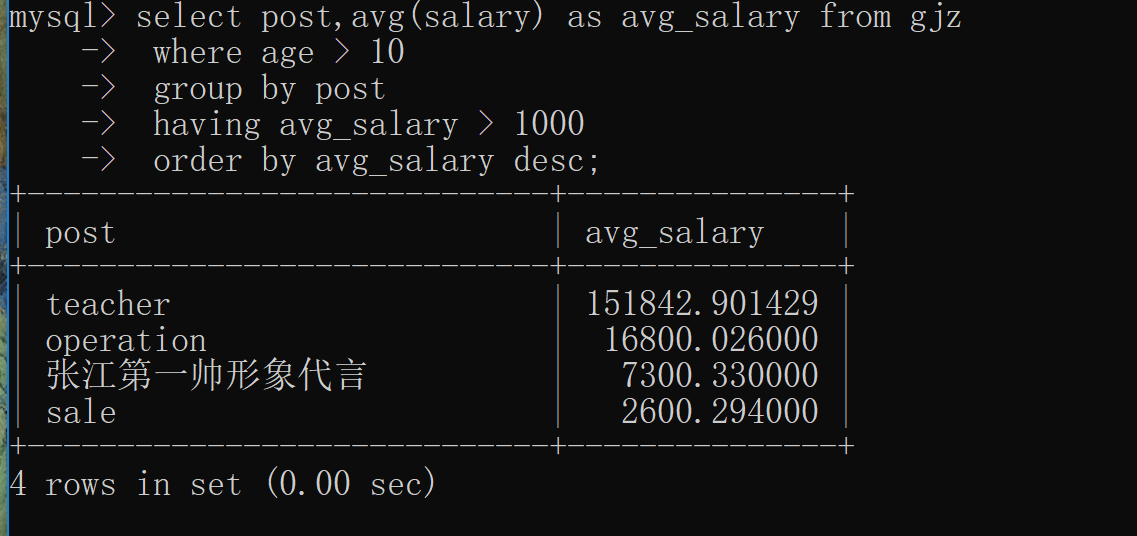
# 统计各部门年龄在10以上的员工的平均薪资,并且保留平均工资大有1000的部门并按照从降序排序
select post,avg(salary) as avg_salary from gjz
where age > 10
group by post
having avg_salary > 1000
order by avg_salary desc;
'''分页就是限制展示条数'''
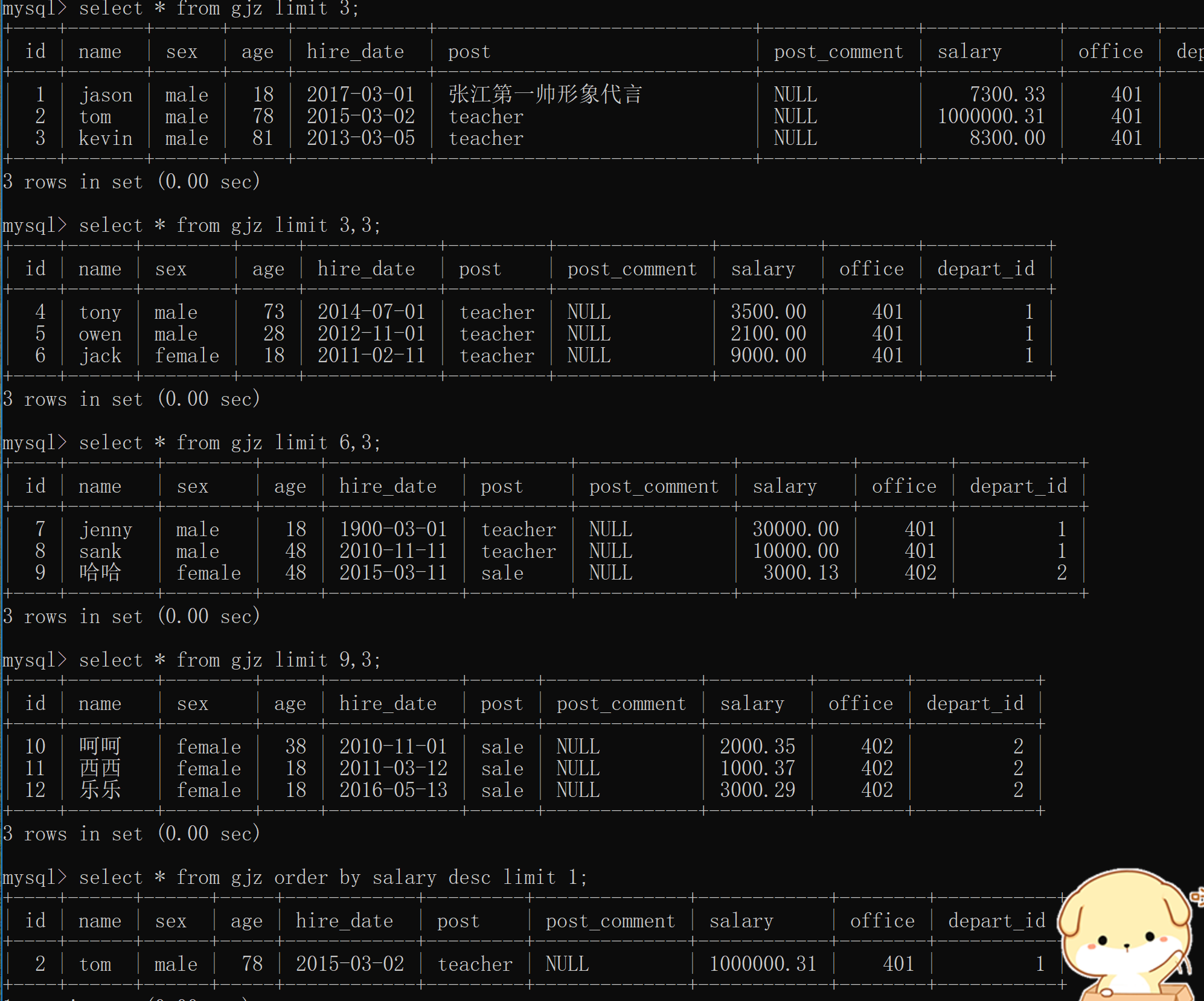
# 限制只显示三条数据
select * from gjz limit 3;
# 实现分页的效果,规定了一页展示三条数据
select * from gjz limit 3;
select * from gjz limit 3,3;
select * from gjz limit 6,3; # 起始位置就是两个数相加
select * from gjz limit 9,3;
# 查询工资最高的人的详情信息
select * from gjz order by salary desc limit 1;
# (查看最高值,先使用降序的方法,把最高的放到最上面,然后限制展示条数一个)
# 使用正则查找j开头,但结尾是n或y;
select * from gjz where name regexp '^j.*(n|y)$';

子查询就相当于是一层一层的解决问题
将一条sql语句的查询结果加括号当做到另外一条sql语句的查询条件
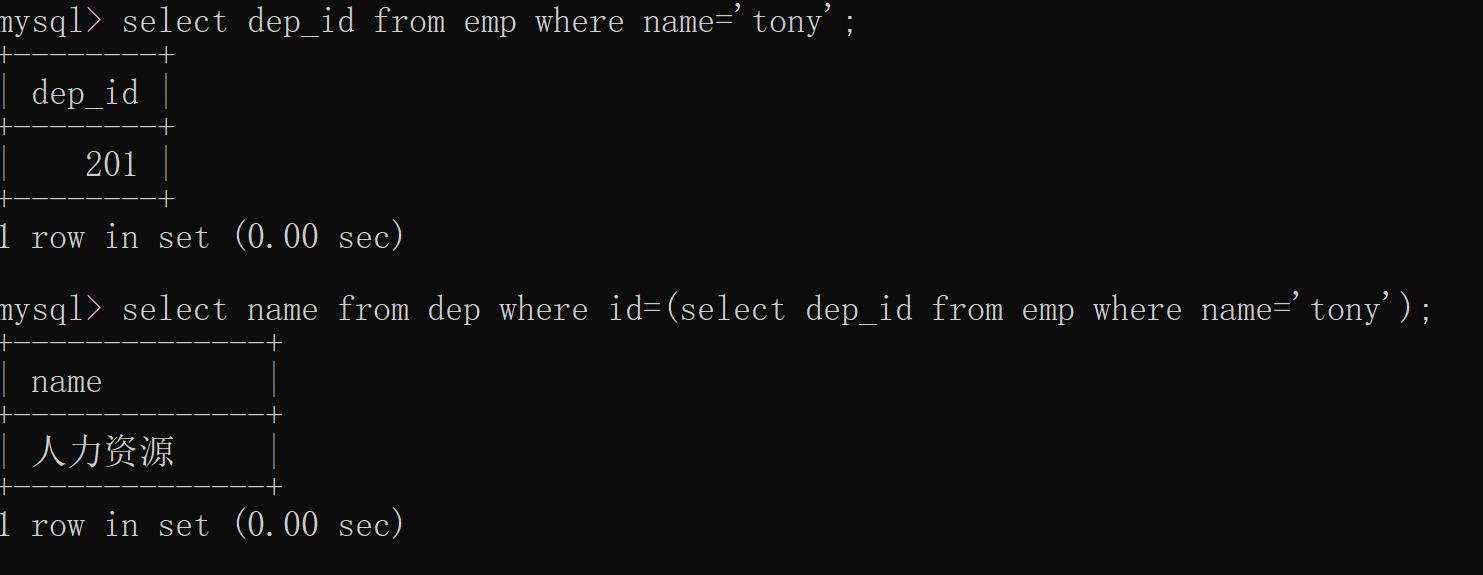
eg: 查询tony所在的部门名称
# 代码:
create table dep(
id int primary key auto_increment,
name varchar(32)
);
create table emp(
id int primary key auto_increment,
name varchar(32),
gender enum('male','female','others') default 'male',
age int,
dep_id int
);
insert into dep values(200,'技术'),(201,'人力资源'),(202,'销售'),(203,'运营'),(205,'安保');
insert into emp(name,age,dep_id) values('jason',18,200),('tony',28,201),('oscar',38,201),('jerry',29,202),('kevin',39,203),('jack',48,204);
# 1、先查tony所在的部门编号
select dep_id from emp where name='tony'
# 2、根据部门标号去部门表中查找部门名称
select name from dep where id=(select dep_id from emp where name='tony');
# 就是将你将要用到的表连接在一起,形成一个大表,然后用这个单表查询到你想要的数据
'''
笛卡尔积
select * from emp,dep; # 会讲所有的数据全部对应一遍
select * from emp,dep where emp.dep_id=dep.id; # 这个就是将数据对应起来把表连在一起
'''
# 连表关键字:
'''
inner join ———— 内连接(只连接两个表中有对应关系的数据)
eg:
select * from emp inner join dep on emp.dep_id=dep.id;
left join ———— 左连接(以左表为基础,展示左表所有的数据,没有对应项的则用NULL填充)
eg:
select * from emp left join dep on emp.dep_id=dep.id;
right join ———— 右连接(以右表为基础,展示右表所有的数据,没有的则用NULL填充)
select * from emp right join dep on emp.dep_id=dep.id;
union ———— 全连接(左右两表的数据全部展示,没有的则用NULL填充)
eg:
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
'''
# 查询 tony所在的部门名称
1、先将员工表和部门表连在一起
select * from emp inner join dep on emp.dep_id=dep.id;
2、基于单表查询
select * from emp inner join dep on emp.dep_id=dep.id
where emp.name='tony'
;
"""
将N多张表拼接到一起
思路:我们可以将两张表拼接之后的结果起别名当做一张表使用
然后再去跟另外一张表拼接 用join包起来,如果表里有相同的数据, 要在select后面声明出来
select * from emp inner join
(select emp.id as epd,emp.name,dep.id from emp inner join dep on emp.dep_id=dep.id) as t1
on emp.id=t1.epd;
"""
Navicat可以充当很多数据库软件的客户端 提供了图形化界面能够让我们更加快速的操作数据库
# 下载
navicat有很多版本 并且默认都是收费使用
正版可以免费体验14天
针对这种图形化软件 版本越新越好(不同版本图标颜色不一样 但是主题功能是一样的)
# 使用
内部封装了SQL语句 用户只需要鼠标点点点就可以快速操作
连接数据库 创建库和表 录入数据 操作数据
外键 SQL文件 逆向数据库到模型 查询(自己写SQL语句)
# 使用navicat编写SQL 如果自动补全语句 那么关键字都会变大写
SQL语句注释语法(快捷键与pycharm中的一致 ctrl+?)
#
--
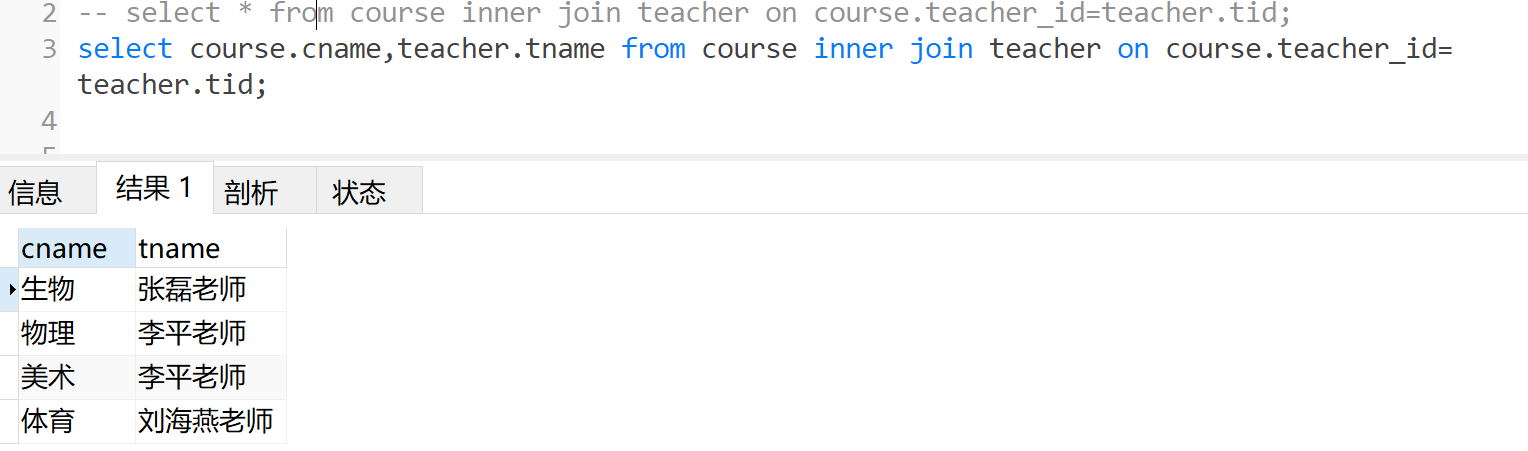
# 1、查询所有的课程的名称以及对应的任课老师姓名
# 这里我们判断需要课程表和教师表
-- select * from course inner join teacher on course.teacher_id=teacher.tid;
select course.cname,teacher.tname from course inner join teacher on course.teacher_id=teacher.tid;
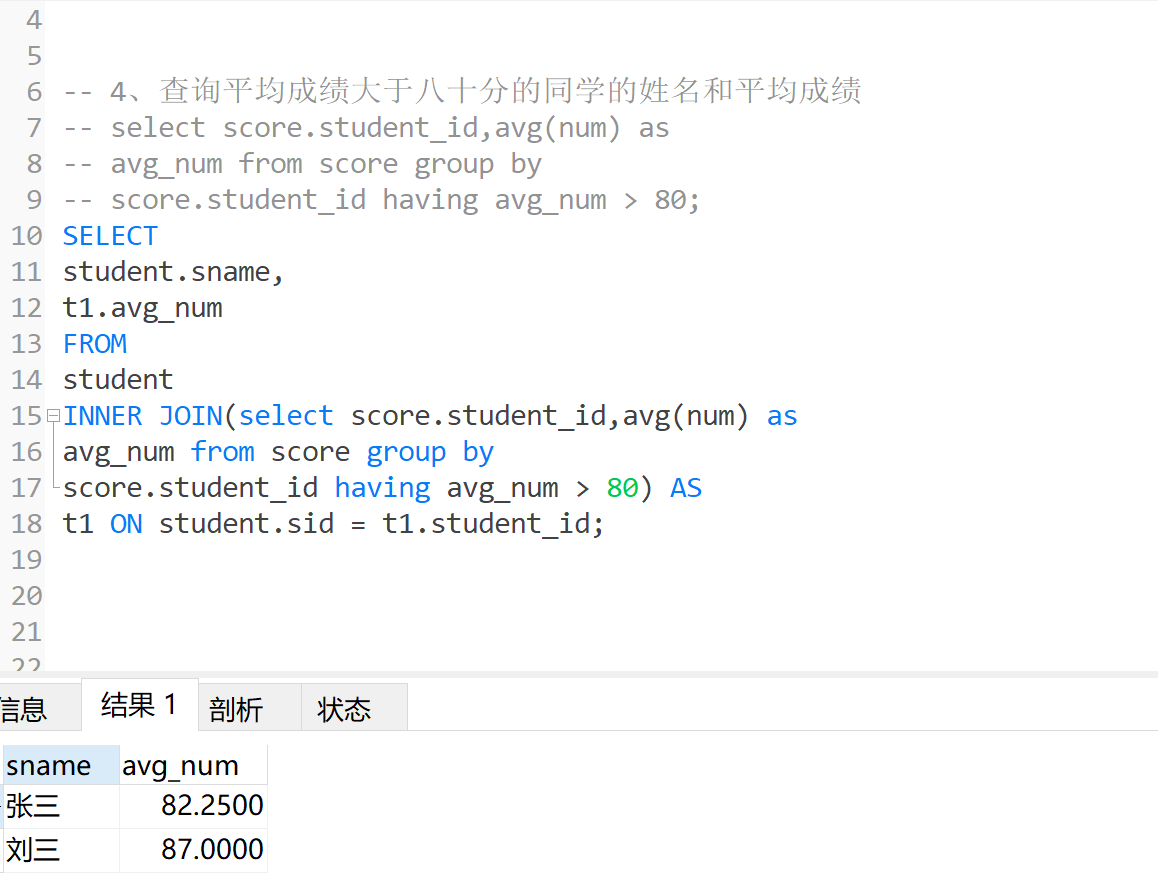
查询平均成绩大于八十分的同学的姓名和平均成绩
# 需要学生表和成绩表
# 我们可以先获取平均分大于八十分的学生信息
select score.student_id,avg(num) as
avg_num from score group by
score.student_id having avg_num > 80;
# 然后再去查看学生姓名和成绩
SELECT
student.sname,
t1.avg_num
FROM
student
INNER JOIN(select score.student_id,avg(num) as
avg_num from score group by
score.student_id having avg_num > 80) AS
t1 ON student.sid = t1.student_id;
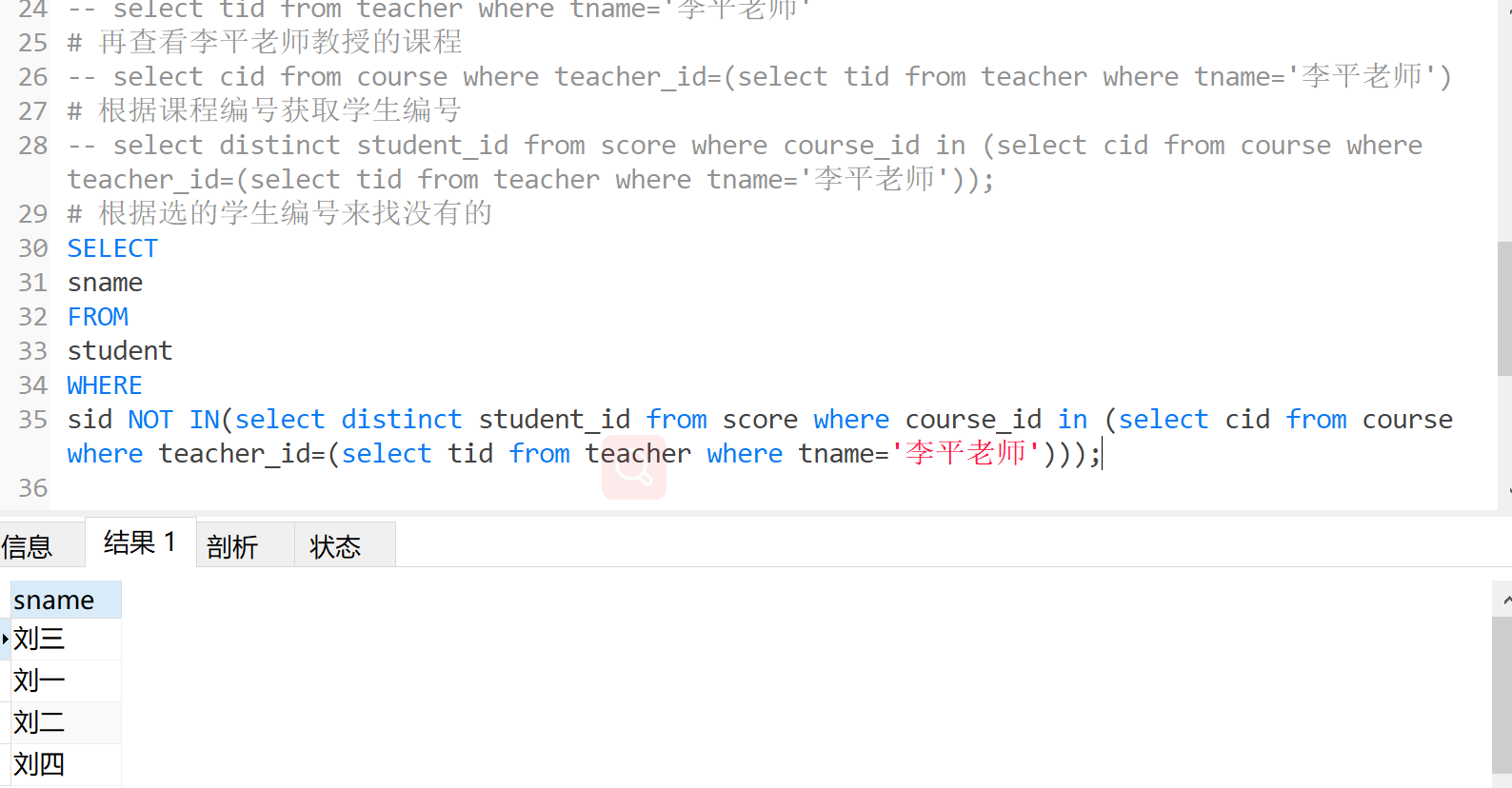
查询没有报李平老师课的学生姓名
# 我们可以使用逆向思维,先取报了李平老师课的学生,然后取反
# 获取李平老师的编号
-- select tid from teacher where tname='李平老师'
# 再查看李平老师教授的课程
-- select cid from course where teacher_id=(select tid from teacher where tname='李平老师')
# 根据课程编号获取学生编号
-- select distinct student_id from score where course_id in (select cid from course where teacher_id=(select tid from teacher where tname='李平老师'));
# 根据选的学生编号来找没有的
SELECT
sname
FROM
student
WHERE
sid NOT IN(select distinct student_id from score where course_id in (select cid from course where teacher_id=(select tid from teacher where tname='李平老师')));
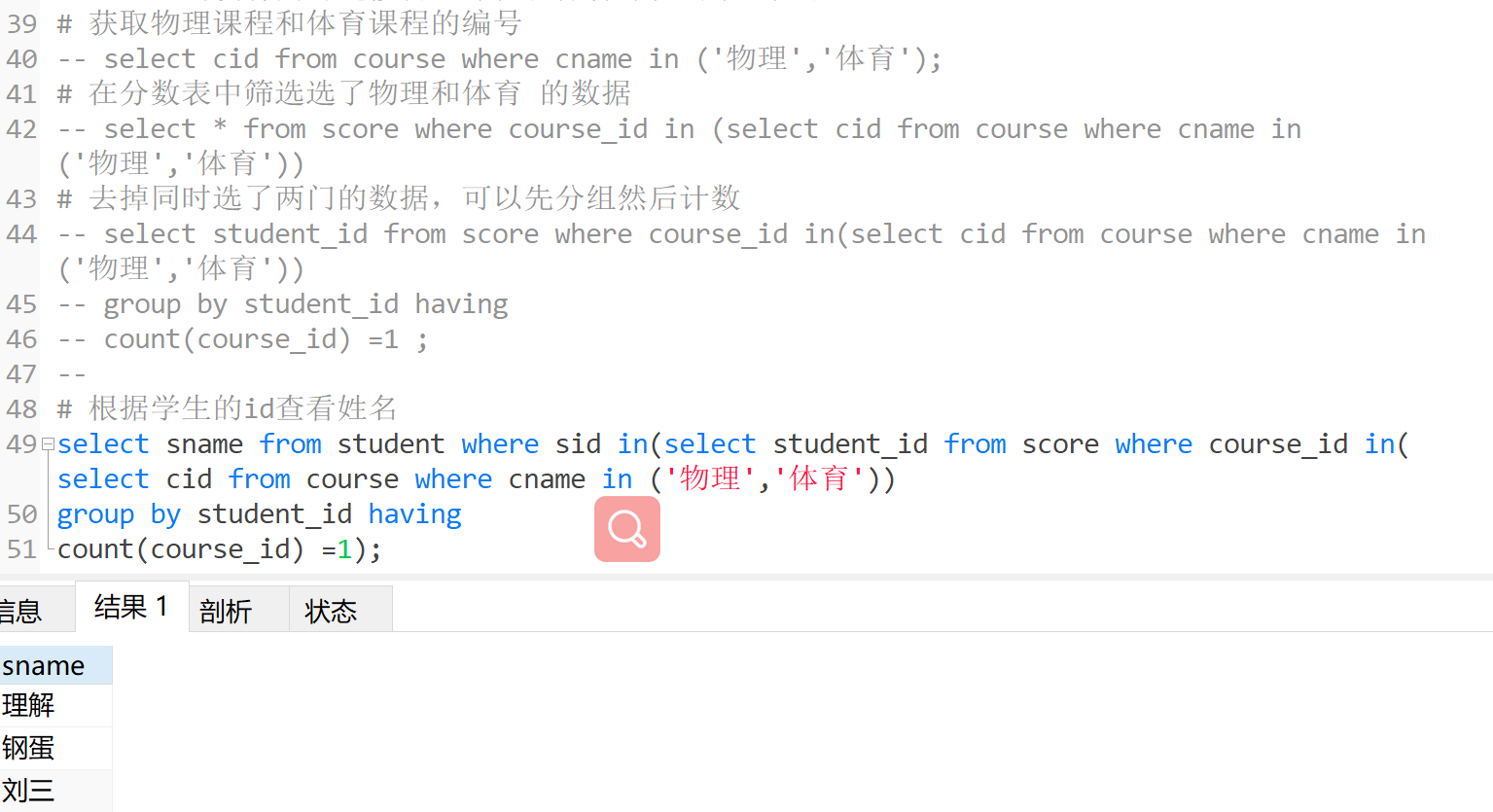
查询没有同时选修物理课程和体育课程的学生姓名(两门都选了和一门都没选的 都不要 只要选了一门)
# 获取物理课程和体育课程的编号
-- select cid from course where cname in ('物理','体育');
# 在分数表中筛选选了物理和体育 的数据
-- select * from score where course_id in (select cid from course where cname in ('物理','体育'))
# 去掉同时选了两门的数据,可以先分组然后计数
-- select student_id from score where course_id in(select cid from course where cname in ('物理','体育'))
-- group by student_id having
-- count(course_id) =1 ;
--
# 根据学生的id查看姓名
select sname from student where sid in(select student_id from score where course_id in(select cid from course where cname in ('物理','体育'))
group by student_id having
count(course_id) =1);
查询挂科超过两门(包括两门)的学生姓名和班级
# 先在分数表里筛选出不及格的数据,就是num<60;
-- select * from score where num<60;
# 筛选出每个学生的挂科门数 大于两个的
-- select student_id from score where num<60 group by student_id
-- having count(course_id)>=2;
# 因为最后取得是姓名和班级,所以我们要拼接起来
-- select student.sname,class.caption from class inner join student on class.cid=student.class_id;
# 筛选数据
SELECT
student.sname,
class.caption
FROM
class
INNER JOIN student ON class.cid = student.class_id
WHERE
student.sid IN(select student_id from score where num<60 group by student_id
having count(course_id)>=2);