
PHP 爬虫——QueryList
前言:
来了个任务说要做个电影网站,要写个壳,数据直接从别人那扒。行吧!那就要学习下PHP爬虫了。占个博客,以后补充。http://study.querylist.cc/archives/6/
之前开发抓取网页上的东西,无非就是curl+正则。用curl去请求所要扒取的页面,然后通过正则匹配去提取你所需要的内容。
但是查了下现在PHP爬虫可以通过使用QueryList来实现。可以通过CSS的DOM选择器来实现。
特性:
- 拥有与jQuery完全相同的CSS3 DOM选择器
- 拥有与jQuery完全相同的DOM操作API
- 拥有通用的列表采集方案
- 拥有强大的HTTP请求套件,轻松实现如:模拟登陆、伪造浏览器、HTTP代理等意复杂的网络请求
- 拥有乱码解决方案
- 拥有强大的内容过滤功能,可使用jQuey选择器来过滤内容
- 拥有高度的模块化设计,扩展性强
- 拥有富有表现力的API
- 拥有高质量文档
- 拥有丰富的插件
- 拥有专业的问答社区和交流群
内容:
因为要做一个电影网站,所以这次利用QueryList来爬取电影网资源,这次爬取的是——玩的嗨TV, 网址:http://tv.wandhi.com/movielist/all/3.html。
首先,选取这网站主要是它是个解析站,去破解各大网站的电影资源供给观看,建站也比较简易,没有啥限制防盗链啥的。当然所能爬取到的资源也比较少,也主要是电影播放资源丰富吧。
主要爬取....(采集好像比较好听点)。本次主要采集了玩的嗨TV的电影列表页面和电影播放页面。
安装:
安装QueryList相当的简单,打开项目目录,运行compose命令进行安装
composer require jaeger/guerylist
(注意点 PHP版本需要在7.0以上)
在控制器中引入相应的类就可以开始使用了
use QL\QueryList;
使用:
先贴个小代码
/** * 采集电影首页 */ public function film_list($page = 1){ $path = '/movielist/all/'.$page.'.html'; $rules = [ 'link' => ['.lazy', 'href'], 'img' => ['.title>h5>a', 'src'], 'name' => ['.lazy', 'title'], 'score' => ['.score', 'html'], 'actor' => ['.subtitle', 'html'], ]; $data = QueryList::Query($this->url . $path, $rules)->data; return $data; }
从代码中可以很清楚的看出,使用QueryList的Query方法,参数为采集地址和采集规则。
采集地址就是你所要采集页面的网址。
采集规则是一个数组,结构“名字”=>[“css DOM选择器”,‘DOM属性’];
这样就可以采集到页面数据。
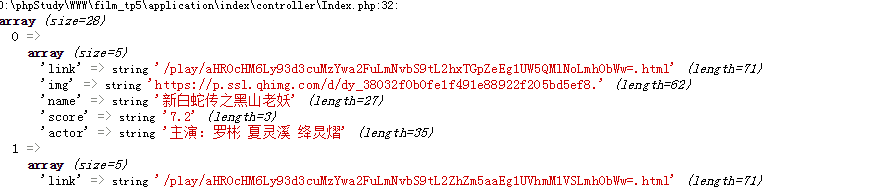
1、电影列表页面
页面结构如下:

爬取结果:
2、电影播放页面
页面结构:

主要采集这两个数据进行拼接就能获得视频的播放地址。
采集结果:

对数据进行拼接就可以获得视频播放地址。
总结:这次采集相对简单。QueryList还有提供了许多深层的方法,后面可以在进行测试使用。主要是进行了简易的采集,获取了所需的数据,电影网也足够了
结语:离职的最后一天,你会做些什么?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号