前程无忧就业信息爬取及分析
前程无忧就业信息爬取及分析
一、选题背景
随着科技的不断发展,招聘的方式也越来越多样化,大部分人已经从过去 的依靠人才市场的传统的求职模式,转变为在网络上通过招聘网站寻找适合自 己的工作。网络招聘不但招聘范围广、招聘信息齐全,而且招聘方式更为便捷。它打破了时间和地域的限制,逐渐成为企业组织招聘的主流方式之一。更 适合时代的发展,也变相带动了更多相关经济的发展。但是,由于招聘网站上 信息量的繁多与复杂,导致求职者很难快速从中获取有效信息。网络爬虫技术的出现为上述繁多复杂的信息的处理提供了一条便捷的道路,利用网络爬虫技术可以将网站上的招聘信息轻松保存到本地,再通过数据分析筛选出有效信息。
二、爬虫设计方案
1.爬虫名称
前程无忧就业信息爬取
简述:利用selenium爬取前程无忧网站招聘信息数据,保存到MySQL数据库,并进行数据分析及数据可视化。
2.数据内容
爬取51job中招聘信息中的岗位名称、公司名称、工作地点、薪资、岗位具体职责、岗位关键字、岗位类别、学历要求等数据。存入数据库中,对应字段为job_name、company_name、company_address、job_salary、job_content、job_keyword、job_type、job_req。并对其进行数据分析。
3.设计方案
利用selenium对网站的310页数据发起请求,保存每页50条招聘信息详情页url到本地,方便后续获取详细的招聘信息,构造了一种“伪增量式”爬虫系统。由于网络条件和爬取时间等因素的限制,很难一次性爬取完所有的数据,故要进行多次爬取。目标url是从本地文件中读取,所以在下一次启动爬虫程序时需要判断哪些url是已经被爬取过的,对于这些url需要舍弃,不再进行爬取,避免造成数据重复和资源浪费。通过打开两个本地文件来判断url是否重复。一个文件存储目标url,通过对文件的读取获取目标url,如果目标url符合条件,则放入爬虫系统进行数据解析和数据采集,并且将已爬取的url存入到另一个已爬取url文件中,如果目标url不符合条件,则跳过。当下一次启动爬虫程序时,先读取已爬取url文件中的内容,存入一个列表中,后续读取目标url文件中的数据时,若该url存在于列表中,则表示该url已被爬取过,可直接跳过。由于文件的读取和写入都是顺序进行的,所以该方法可近似实现“伪增量式”功能,可以有效减少数据爬取的次数。
三、页面结构及特征分析
观察网站页面构造,发现该网站有分页,每页包含50条不同的就业信息,共有2000页招聘信息。对每一页招聘信息发起请求,获取其中所有的就业信息的详情页url,并保存到本地,方便后续对详情页发起请求,获取其中的目标数据。由于时间的关系,本次只获取310页招聘数据。
观察种子url发现,网站每更新一页,种子url中只有一个数字会变化,且该数字对应网站的页码数。通过python的for循环可轻易构造出310页网站的url,再对每个url发起请求,运用正则表达式匹配出其中每条就业信息的详情页url,并保存到本地。
构造网页代码:
1 chrome = openchrome() 2 with open('i.txt','r') as fp: 3 n = fp.read() 4 for i in range(int(n), 311): 5 url = f'https://search.51job.com/list/000000,000000,0000,01%252c37%252c38,9,99,+,2,{i}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=' 6 text = get_text(chrome, url) 7 get_url(text) 8 time.sleep(8)
9 closechrome(chrome)
匹配详情页url代码:
1 def get_url(text): 2 try: 3 url_list = re.findall('"job_href":"(.*?)","', text, re.S) # 获取详情页url 4 # print(url_list) 5 for url in url_list: 6 with open('详情页url.txt', 'a') as f: # 将详情页url保存到本地 7 f.write(url + '\n') 8 print(f'已保存第{i}页url...') 9 except Exception as e: 10 with open('i.txt','w') as f: 11 f.write(i)
详情页数据:
利用xpath定位关键信息位置,并保存到数据库。
1 def get_source(chrome, url): # 获取页面源代码 2 chrome.get(url) 3 time.sleep(30) 4 if chrome.title == '滑动验证页面': 5 ring() 6 close_chrome(chrome) 7 time.sleep(8) 8 try: 9 global job_type 10 global job_keyword 11 job_name = chrome.find_element(By.XPATH, '//div[@class="cn"]/h1').text # 职位名称 12 job_salary = chrome.find_element(By.XPATH, '//div[@class="cn"]/strong').text # 薪资 13 company_name = chrome.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[4]/div[1]/div[1]/a/p').text # 公司名称 14 info_list = chrome.find_element(By.XPATH, '//p[@class="msg ltype"]').text.split("|") 15 # print(info_list) 16 if len(info_list) < 4: 17 job_req = '无学历要求' 18 else: 19 job_req = info_list[2] # 学历要求 20 company_address = info_list[0] # 公司地址 21 if '-' in company_address: 22 company_address = company_address.split('-')[0] 23 job_content = chrome.find_element(By.XPATH, '//div[@class="bmsg job_msg inbox"]').text # 职位信息 24 if '职能类别:' in job_content: 25 job_content = job_content.split('职能类别:')[0] 26 elif '关键字:' in job_content: 27 job_content = job_content.split('关键字:')[0] 28 else: 29 job_content = job_content.split('微信分享')[0] 30 31 label = chrome.find_elements(By.XPATH, '//div[@class="mt10"]/p/span') # 判断是职能类别还是关键字 32 if len(label) == 2: 33 job_type = chrome.find_element(By.XPATH, '//div[@class="mt10"]/p[1]/a').text # 职能类别 34 job_keyword = chrome.find_element(By.XPATH, '//div[@class="mt10"]/p[2]/a').text # 关键字 35 if len(label) == 1: 36 wd = chrome.find_element(By.XPATH, '//p[@class="fp"]/span').text 37 if wd == "职能类别:": 38 job_type = chrome.find_element(By.XPATH, '//div[@class="mt10"]/p[1]/a').text # 职能类别 39 job_keyword = 'NULL' # 关键字 40 if wd == "关键字:": 41 job_type = 'NULL' # 职能类别 42 job_keyword = chrome.find_element(By.XPATH, '//div[@class="mt10"]/p[1]/a').text # 关键字 43 # print(job_name, job_type, job_keyword) 44 data = User(job_name=job_name, company_name=company_name, company_address=company_address, 45 job_salary=job_salary, job_content=job_content, job_req=job_req, job_type=job_type, 46 job_keyword=job_keyword) # 写入数据 47 Session.add(data) # 将数据添加到表内 48 Session.commit() # 事务必须提交数据才会被存入表中 49 except Exception as e: 50 traceback.print_exc() 51 get_source(chrome, urls.__next__())
四、程序设计
1.数据爬取与采集
1.seleium_get_detail_url.py 获取所有详情页url并保存到本地。
2.get_job_info.py 创建数据表,获取详情页数据并存入数据库。
2数据预处理
对爬取到的数据进行预处理,这里只保存计算机领域相关的数据,方便后续做数据分析。
详见 3.数据读取及预处理.py文件。
3.数据分析及可视化
所需库:Pyecharts pandas wordcloud
对上述所爬取的数据可从工作地点,薪资待遇,学历要求,工作岗位,语言热度等方面进行数据分析,并将结果进行可视化展示。
各城市岗位数量分布图:
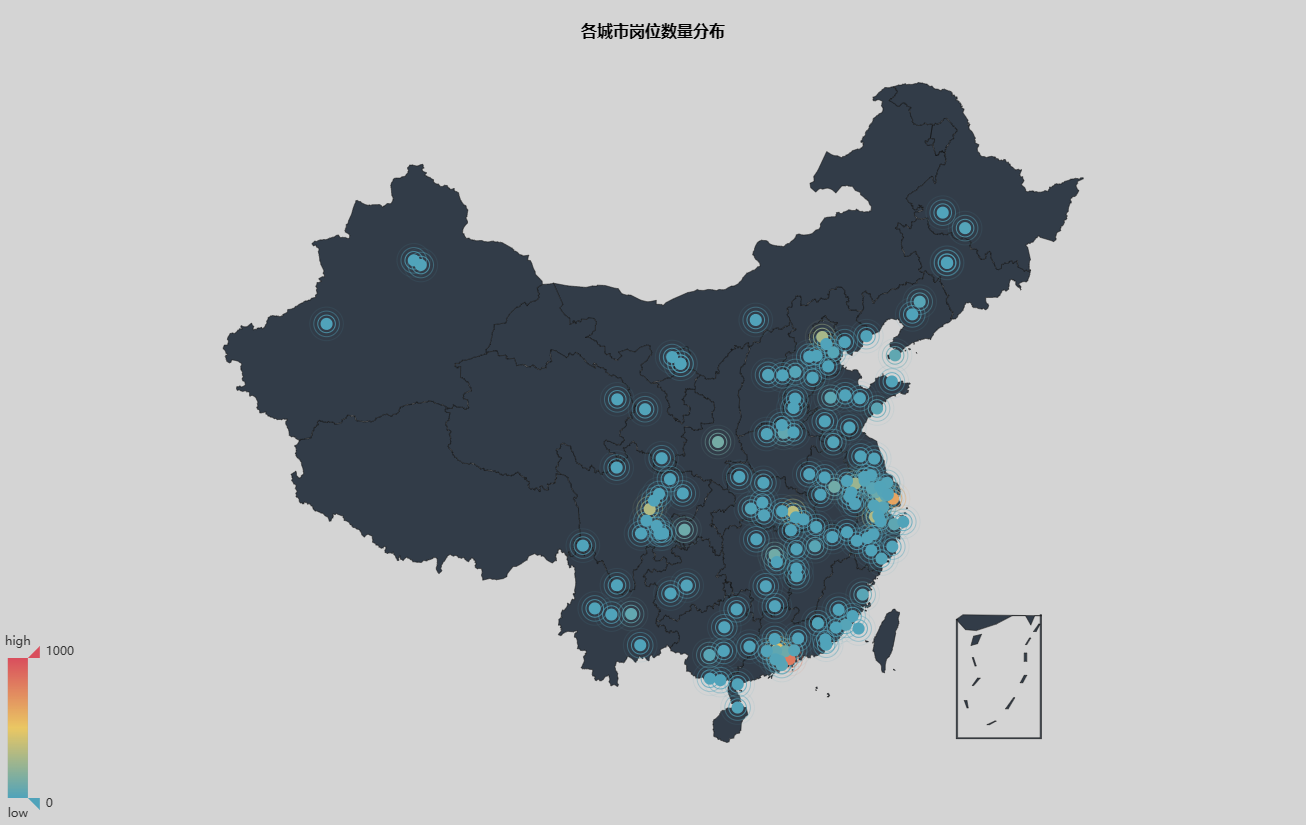
如图可知,我国计算机领域相关岗位主要分布在北上广深等一线城市和沿海地区,我国西部地区相关岗位需求较少。
各城市招聘数量比例图:
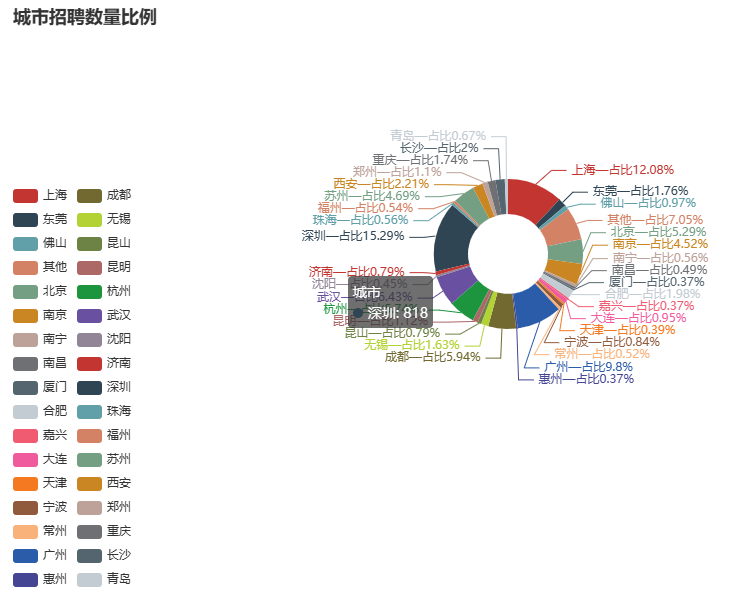
由于许多城市招聘数量极少,在绘制城市招聘数量比例图时为了图表数据的简洁和美观,将招聘数量少于20的城市统一称为“其他城市”。该图可直观看出哪些城市对计算机领域需求较高。
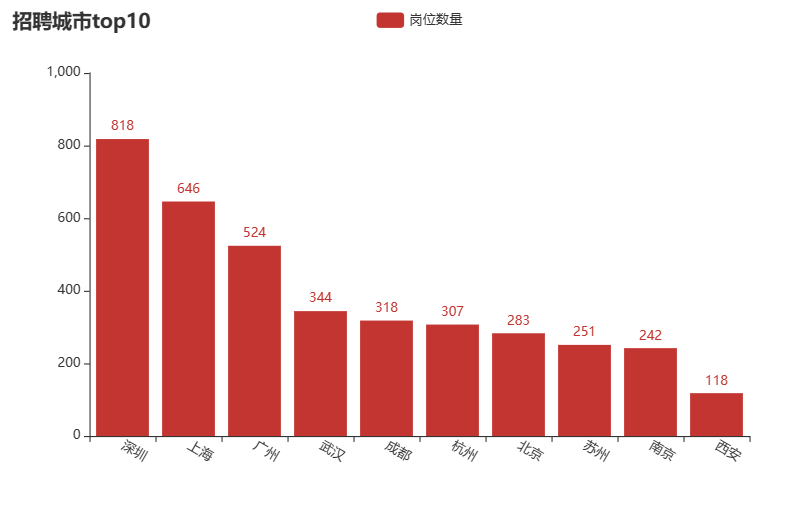
城市招聘数量前十榜:
学历占比:
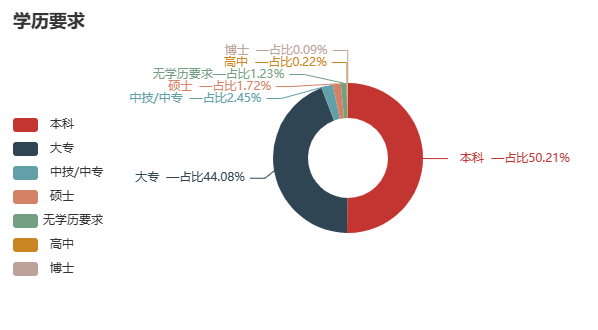
通过对招聘岗位所需学历的统计绘制饼状图,得到所需各学历占比,可以得出计算机领域岗位对从业人员学历的要求大多为本科及以上,该领域对学历要求相对来讲较高。
岗位薪资 :
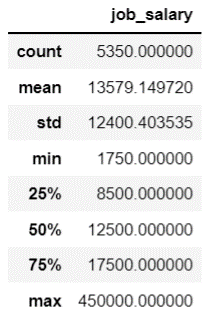
各城市平均薪资:
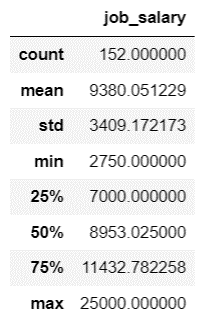
上图中count,mean,std,min分别表示样本总数,样本平均值,方差,最小值,25%,50%,75%代表相应的分位数。
薪资与学历关系:
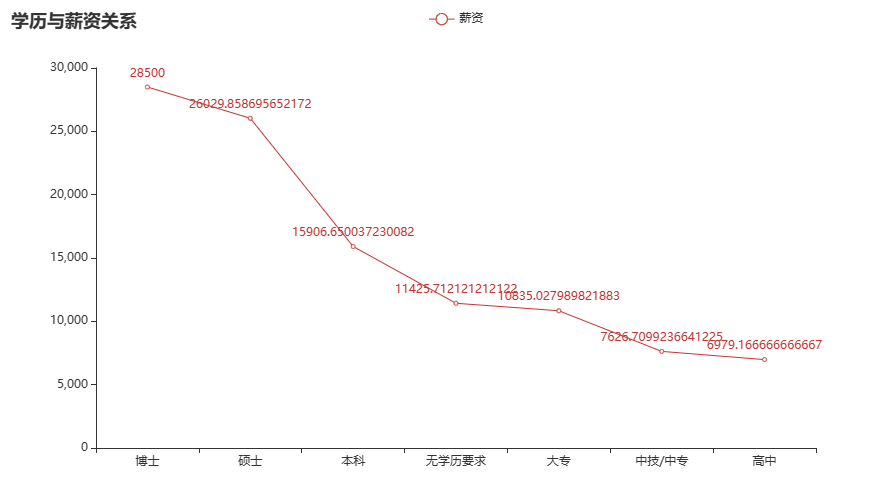
将薪资信息按照学历分组可得出薪资与学历的关系,可得出学历与薪资基本成正比关系,即学历越高,薪资越高,且高学历与低学历间薪资差距较大。
职位信息词云图:
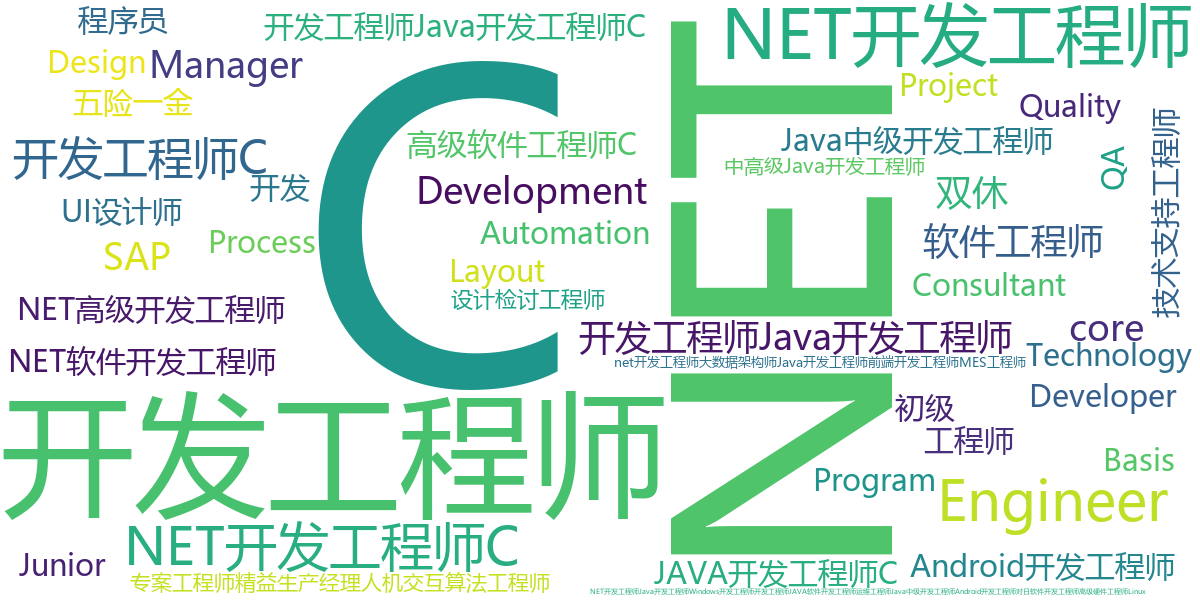
将职位信息和职位关键字信息统计后绘制成词云图,通过词云图可以明确直观的观察出热门岗位。
4.数据持久化
采用MySQL数据库存储招聘信息。
sqlalchemy是一个Python语言实现的的针对关系型数据库的ORM库。可用于连接大多数常见的数据库,比如MySQL、SQLite、Oracle等。通过ORM,开发者可以用面向对象的方式来操作数据库,不再需要编写原生的SQL语句。sqlalchemy从操作上来讲比pymysql更简单,且sqlalchemy的功能更加强大。在使用sqlalchemy之前要先安装pymysql。sqlalchemy可以通过自定义类来实现数据表的创建,并且支持创建索引等操作。sqlalchemy操作数据表的流程如下:
(1) 通过create_engine模块创建引擎,用于连接数据库。
(2) 实例化一个declarative_base类,根据这个ORM基类创建数据表(数据表所在的类继承于上述类)。
(3) 利用上述base类的create_all方法创建数据表(若要删除数据表,可用base的drop_all方法)。
(4) 创建session。在sqlalchemy中,数据库的增删改查操作都是通过session进行的,可通过sessionmaker创建session,方便后续对数据表的操作。
通过session.add()可实现对数据表的增添操作,通过session.delete()可以实现对已增添数据的删除功能,直接修改实例化对象数据的值即可实现数据表的修改操作。值得注意的是,数据表的增删改操作都需提交才会生效。session.commit()可实现数据的提交。数据的查找需要先指定数据表,用query指定查找的类,all可返回查找对象所有的数据,filter可实现按照指定条件查找。
创建数据表代码:
1 # 建表 2 # mysql+pymysql://用户名:密码@localhost:端口号/数据库名 3 engine = create_engine('mysql+pymysql://root:123456@localhost:3306/51job') # 数据库的连接 123456为数据库密码 4 Base = declarative_base() # 生成orm基类 5 6 # 初始化数据表(类似flask) 7 class User(Base): 8 __tablename__ = 'job_info' # table的名字 9 id = Column(Integer, primary_key=True, autoincrement=True, nullable=False, comment='id') # 创建id属性,自增 10 job_name = Column(VARCHAR(225), nullable=False, comment='职位名称') # 创建job_name属性 11 company_name = Column(VARCHAR(225), nullable=False, comment='公司名称') # 创建company_name属性 12 company_address = Column(VARCHAR(225), nullable=False, comment='公司地址') # 创建company_address属性 13 job_salary = Column(VARCHAR(225), comment='薪资') # 创建job_salary属性 14 job_content = Column(TEXT, comment='职位信息') # 创建job_content属性 15 job_keyword = Column(VARCHAR(225), comment='关键字') # 创建job_keyword属性 16 job_type = Column(VARCHAR(225), comment='职能类别') # 创建job_type属性 17 job_req = Column(VARCHAR(225), comment='学历要求') # 创建job_req属性 18 19 def __repr__(self): # 用于进行查找时的数据返回 20 return '%d job_name :%s\n company_name:%s\n company_address:%s\n job_salary:%s\n job_content:%s\n job_keyword:%s\n job_type:%s\n job_req:%s\n' \ 21 % (self.id, self.job_name, self.company_name, self.company_address, self.job_salary, self.job_content, 22 self.job_keyword, self.job_type, self.job_req) 23 24 Session_class = sessionmaker(bind=engine) # 进行数据库的连接 25 Session = Session_class() # 生成session 实例 26 Base.metadata.create_all(engine) # 建表
数据存储详见2.get_job_info.py
五、总结
计算机领域作为推动科技发展的“主力军”,岗位主要分布在沿海地区,省会等经济发达地区。由此可见,经济的发展离不开高新技术的发展与创新。作为高新技术领域,该领域对从业者的要求较高,学历大部分为本科及以上,且薪资普遍较高。此次课程设计存在的不足之处:本次数据爬取的数量较少,从某种程度上来讲不足以反映数据的规律。且数据爬取的速度较慢,数据的利用率较低,仍有许多有价值的数据待挖掘分析。
部分代码运行截图:
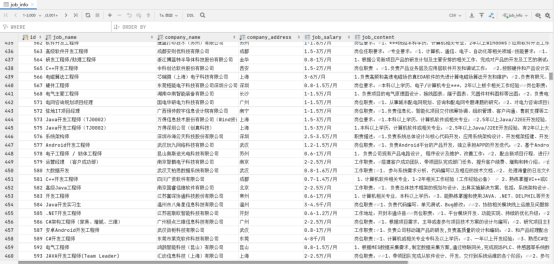
数据库部分截图:
完整代码:
1.seleium_get_detail_url.py
1 from selenium import webdriver 2 import re 3 import time 4 5 6 def getDriver(): 7 options = webdriver.ChromeOptions() 8 options.add_argument("--disable-extensions") 9 options.add_argument("--disable-gpu") 10 # options.add_argument("--no-sandbox") # linux only 11 options.add_experimental_option("excludeSwitches", ["enable-automation"]) 12 options.add_experimental_option("useAutomationExtension", False) 13 driver = webdriver.Chrome(options=options) 14 driver.execute_cdp_cmd("Network.enable", {}) 15 driver.execute_cdp_cmd("Network.setExtraHTTPHeaders", {"headers": {"User-Agent": "browserClientA"}}) 16 driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { 17 "source": """ 18 Object.defineProperty(navigator, 'webdriver', { 19 get: () => undefined 20 }) 21 """ 22 }) 23 return driver 24 25 26 def openchrome(): # 打开chrome浏览器 27 chrome = getDriver() 28 return chrome 29 30 31 def get_text(chrome, url): # 获取页面源代码 32 chrome.get(url) 33 time.sleep(30) # 手动登录 34 page_source = chrome.page_source 35 # print(page_source) 36 if page_source.title() == '滑动验证页面': 37 print('\a') 38 time.sleep(10) 39 return page_source 40 41 42 def get_url(text): 43 try: 44 url_list = re.findall('"job_href":"(.*?)","', text, re.S) # 获取详情页url 45 # print(url_list) 46 for url in url_list: 47 with open('详情页url.txt', 'a') as f: # 将详情页url保存到本地 48 f.write(url + '\n') 49 print(f'已保存第{i}页url...') 50 except Exception as e: 51 with open('i.txt','w') as f: 52 f.write(i) 53 54 def closechrome(chrome): # 关闭浏览器 55 chrome.quit() 56 57 58 if __name__ == '__main__': 59 chrome = openchrome() 60 with open('i.txt','r') as fp: 61 n = fp.read() 62 for i in range(int(n), 311): 63 url = f'https://search.51job.com/list/000000,000000,0000,01%252c37%252c38,9,99,+,2,{i}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=' 64 text = get_text(chrome, url) 65 get_url(text) 66 time.sleep(8) 67 closechrome(chrome)
2.get_job_info.py
1 ''' 2 !!!!!!!! 3 运行代码后需要点击右上角的登录按钮手动登录 4 ''' 5 import re 6 import traceback 7 import winsound 8 from selenium import webdriver 9 import time 10 from selenium.webdriver.common.by import By 11 from sqlalchemy import create_engine 12 from sqlalchemy.ext.declarative import declarative_base 13 from sqlalchemy import Column, Integer, TEXT, VARCHAR 14 from sqlalchemy.orm import sessionmaker 15 16 # 建表 17 # mysql+pymysql://用户名:密码@localhost:端口号/数据库名 18 engine = create_engine('mysql+pymysql://root:15826774884@localhost:3306/51job') # 数据库的连接 123456为数据库密码 19 Base = declarative_base() # 生成orm基类 20 21 22 # 初始化数据表(类似flask) 23 class User(Base): 24 __tablename__ = 'job_info' # table的名字 25 id = Column(Integer, primary_key=True, autoincrement=True, nullable=False, comment='id') # 创建id属性,自增 26 job_name = Column(VARCHAR(225), nullable=False, comment='职位名称') # 创建job_name属性 27 company_name = Column(VARCHAR(225), nullable=False, comment='公司名称') # 创建company_name属性 28 company_address = Column(VARCHAR(225), nullable=False, comment='公司地址') # 创建company_address属性 29 job_salary = Column(VARCHAR(225), comment='薪资') # 创建job_salary属性 30 job_content = Column(TEXT, comment='职位信息') # 创建job_content属性 31 job_keyword = Column(VARCHAR(225), comment='关键字') # 创建job_keyword属性 32 job_type = Column(VARCHAR(225), comment='职能类别') # 创建job_type属性 33 job_req = Column(VARCHAR(225), comment='学历要求') # 创建job_req属性 34 35 def __repr__(self): # 用于进行查找时的数据返回 36 return '%d job_name :%s\n company_name:%s\n company_address:%s\n job_salary:%s\n job_content:%s\n job_keyword:%s\n job_type:%s\n job_req:%s\n' \ 37 % (self.id, self.job_name, self.company_name, self.company_address, self.job_salary, self.job_content, 38 self.job_keyword, self.job_type, self.job_req) 39 40 41 Session_class = sessionmaker(bind=engine) # 进行数据库的连接 42 Session = Session_class() # 生成session 实例 43 Base.metadata.create_all(engine) # 建表 44 45 def getDriver(): 46 options = webdriver.ChromeOptions() 47 options.add_argument("--disable-extensions") 48 options.add_argument("--disable-gpu") 49 #options.add_argument("--no-sandbox") # linux only 50 options.add_experimental_option("excludeSwitches", ["enable-automation"]) 51 options.add_experimental_option("useAutomationExtension", False) 52 driver = webdriver.Chrome(options=options) 53 driver.execute_cdp_cmd("Network.enable", {}) 54 driver.execute_cdp_cmd("Network.setExtraHTTPHeaders", {"headers": {"User-Agent": "browserClientA"}}) 55 driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { 56 "source": """ 57 Object.defineProperty(navigator, 'webdriver', { 58 get: () => undefined 59 }) 60 """ 61 }) 62 return driver 63 64 65 def ring(): # 蜂鸣器报警 66 duration = 1000 # millisecond 持续时间 单位是毫秒 67 freq = 440 # Hz 68 winsound.Beep(freq, duration) # 报警 提示需要滑动验证码 69 70 71 def open_chrome(): # 打开chrome浏览器 72 chrome = getDriver() 73 return chrome 74 75 76 def get_source(chrome, url): # 获取页面源代码 77 chrome.get(url) 78 time.sleep(30) 79 if chrome.title == '滑动验证页面': 80 ring() 81 close_chrome(chrome) 82 time.sleep(8) 83 try: 84 global job_type 85 global job_keyword 86 job_name = chrome.find_element(By.XPATH, '//div[@class="cn"]/h1').text # 职位名称 87 job_salary = chrome.find_element(By.XPATH, '//div[@class="cn"]/strong').text # 薪资 88 company_name = chrome.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[4]/div[1]/div[1]/a/p').text # 公司名称 89 info_list = chrome.find_element(By.XPATH, '//p[@class="msg ltype"]').text.split("|") 90 # print(info_list) 91 if len(info_list) < 4: 92 job_req = '无学历要求' 93 else: 94 job_req = info_list[2] # 学历要求 95 company_address = info_list[0] # 公司地址 96 if '-' in company_address: 97 company_address = company_address.split('-')[0] 98 job_content = chrome.find_element(By.XPATH, '//div[@class="bmsg job_msg inbox"]').text # 职位信息 99 if '职能类别:' in job_content: 100 job_content = job_content.split('职能类别:')[0] 101 elif '关键字:' in job_content: 102 job_content = job_content.split('关键字:')[0] 103 else: 104 job_content = job_content.split('微信分享')[0] 105 106 label = chrome.find_elements(By.XPATH, '//div[@class="mt10"]/p/span') # 判断是职能类别还是关键字 107 if len(label) == 2: 108 job_type = chrome.find_element(By.XPATH, '//div[@class="mt10"]/p[1]/a').text # 职能类别 109 job_keyword = chrome.find_element(By.XPATH, '//div[@class="mt10"]/p[2]/a').text # 关键字 110 if len(label) == 1: 111 wd = chrome.find_element(By.XPATH, '//p[@class="fp"]/span').text 112 if wd == "职能类别:": 113 job_type = chrome.find_element(By.XPATH, '//div[@class="mt10"]/p[1]/a').text # 职能类别 114 job_keyword = 'NULL' # 关键字 115 if wd == "关键字:": 116 job_type = 'NULL' # 职能类别 117 job_keyword = chrome.find_element(By.XPATH, '//div[@class="mt10"]/p[1]/a').text # 关键字 118 # print(job_name, job_type, job_keyword) 119 data = User(job_name=job_name, company_name=company_name, company_address=company_address, 120 job_salary=job_salary, job_content=job_content, job_req=job_req, job_type=job_type, 121 job_keyword=job_keyword) # 写入数据 122 Session.add(data) # 将数据添加到表内 123 Session.commit() # 事务必须提交数据才会被存入表中 124 except Exception as e: 125 traceback.print_exc() 126 get_source(chrome, urls.__next__()) 127 128 129 def close_chrome(chrome): # 关闭浏览器 130 chrome.quit() 131 132 133 if __name__ == '__main__': 134 chrome = open_chrome() 135 i = 1 136 file = open('./newfile.txt', 'r') # 新建一个文件判断该页面是否已被爬取 137 url_list = [] 138 for line in file: 139 line = line.strip() # 去掉换行符 140 url_list.append(line) 141 with open('./详情页urlaaaa.txt', 'r') as f: 142 urls = f.readlines() 143 urls = iter(urls) 144 for url in urls: 145 if 'jobs' not in url: 146 continue 147 url = url.strip() 148 url = url.replace('\\', '') 149 if url in url_list: # 如果该url被爬取则跳过 150 continue 151 get_source(chrome, url) 152 print('已成功存入{}条信息...'.format(i)) 153 with open('newfile.txt', 'a') as fp: # 将爬过的url存入新的文件中 154 fp.write(url + '\n') 155 i += 1 156 close_chrome(chrome) 157 file.close()
3.数据读取及预处理.py
1 import pandas as pd 2 import pymysql 3 4 # 连接MySQL 5 conn = pymysql.connect( 6 host='localhost', 7 user='root', 8 passwd='123456', 9 db='51job', 10 port=3306, 11 charset='utf8' 12 ) 13 14 cursor = conn.cursor() # 创建游标 15 16 # 数据预处理,剔除掉不需要的数据 17 18 # 剔除掉不需要的数据 19 # 将 销售、普工、采购、业务员等与计算机领域无关的数据删除 20 21 del_sql = 'delete from job_info where job_name like "%普工%"' 22 del_sql1 = 'delete from job_info where job_type like "%普工%"' 23 del_sql2 = 'delete from job_info where job_name like "%长白班%"' 24 del_sql3 = 'delete from job_info where job_name like "%销售%"' 25 del_sql4 = 'delete from job_info where job_name like "%采购%"' 26 del_sql5 = 'delete from job_info where job_name like "%业务%"' 27 del_sql6 = 'delete from job_info where job_type like "%质量%"' 28 del_sql7 = 'delete from job_info where job_type like "%质检%"' 29 del_sql8 = 'delete from job_info where job_name like "%店长%"' 30 del_sql9 = 'delete from job_info where job_name like "%客服%"' 31 del_sql10 = 'delete from job_info where job_type like "%销售%"' 32 del_sql11 = "delete from job_info where job_type like '%其他'and job_req like '%中%'" 33 del_sql12 = "delete from job_info where job_type like '%物料%'" 34 del_sql13 = "delete from job_info where job_type like '%市场%'" 35 del_sql14 = "delete from job_info where job_type like '%生产主管%'" 36 del_sql15 = "delete from job_info where job_type like '%工长%'" 37 del_sql16 = "delete from job_info where job_req like '%初中及以下%'" 38 del_sql17 = "delete from job_info where job_type like '%核酸%'" 39 del_sql18 = "delete from job_info where job_salary=''" 40 del_sql19 = "delete from job_info where job_salary like '%1.5千%'" 41 del_sql20 = "delete from job_info where job_req like '%招%'" 42 # del_sql21 = "delete from job_info where job_req like '%高中%' and job_keyword not in ('java','C#','php','erp实施','游戏ui','测试','Helpdesk','CAD','运维','%工程师','小程序测试')" 43 # del_sql22 = "delete from job_info where job_req like '%无%' and job_type not in ('%工程师%','%设计师%','项目经理','Web前端开发','运维开发','%ERP%','%Helpdesk%','%IT%','%产品经理%')" 44 45 cursor.execute(del_sql) 46 cursor.execute(del_sql1) 47 cursor.execute(del_sql2) 48 cursor.execute(del_sql3) 49 cursor.execute(del_sql4) 50 cursor.execute(del_sql5) 51 cursor.execute(del_sql6) 52 cursor.execute(del_sql7) 53 cursor.execute(del_sql8) 54 cursor.execute(del_sql9) 55 cursor.execute(del_sql10) 56 cursor.execute(del_sql11) 57 cursor.execute(del_sql12) 58 cursor.execute(del_sql13) 59 cursor.execute(del_sql14) 60 cursor.execute(del_sql15) 61 cursor.execute(del_sql16) 62 cursor.execute(del_sql17) 63 cursor.execute(del_sql18) 64 cursor.execute(del_sql19) 65 cursor.execute(del_sql20) 66 # cursor.execute(del_sql21) 67 # cursor.execute(del_sql22) 68 # conn.rollback() 69 conn.commit() 70 71 cursor.close() # 关闭游标 72 73 # 查看数据 74 df = pd.read_sql('select * from job_info', conn) 75 print(df.sum)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号