
利用爬虫爬取京东商品的评论信息
在之前利用爬虫爬取网页的时候只是用到了html解析,但要获得大量的评论内容时,只从html页面解析并不能满足要求,那么只能直接获取相关数据
进入京东商品界面,F12打开开发人员工具,打开network
刷新页面,会发现大量内容出现
点击评论,查看评论信息,开发人员工具也会随着增加内容,新增加的内容会在工具中的时间轴动态的出现
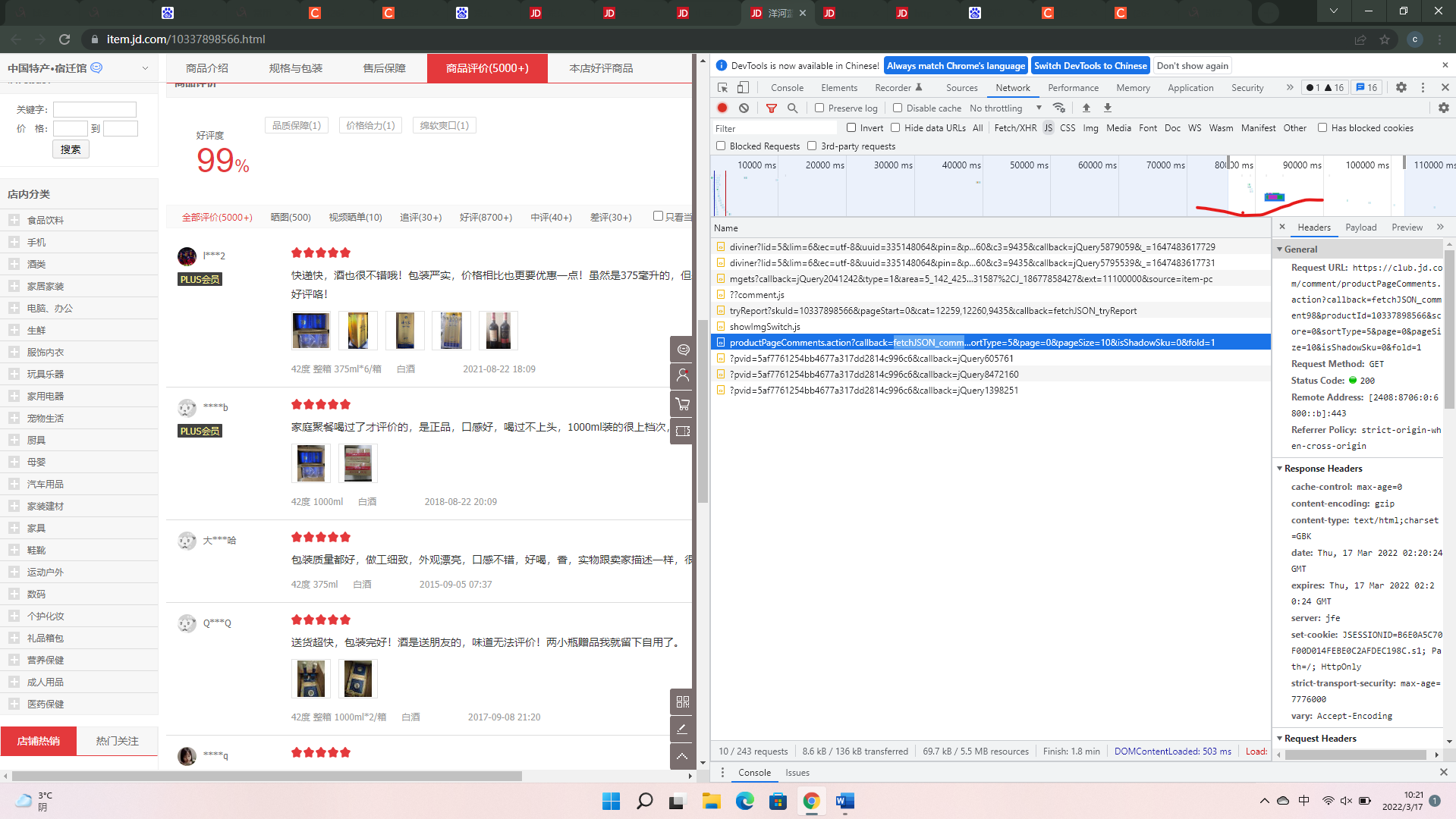
可以如上图在时间轴上划定范围,减少要查看的内容。
记下来查看内容,选择符合要求的如
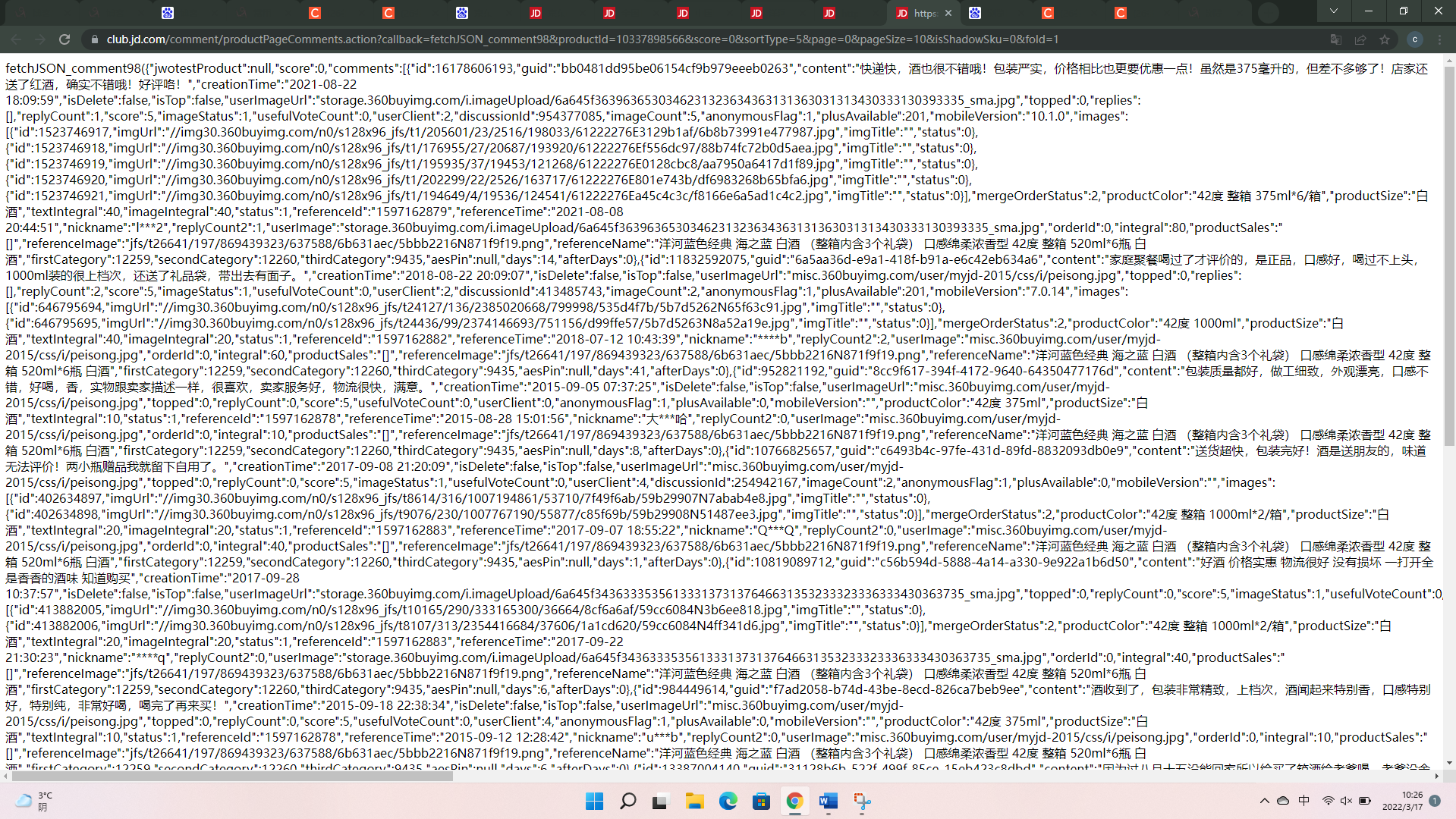
内容的url地址是有一定的规律的:如上面内容的地址
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=10337898566&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1其中score表示用户评论的分类,0是全部分类,1是差评分类;page代表内容的页数,等同于页面上的一页评论。page最多为99,因为京东页面前端最多提供100页的评论,爬虫能爬取大量的内容是通过修改该参数进行的
接下来就是用爬虫对内容进行相关的爬取和解析了
from bs4 import BeautifulSoup
import requests
Headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
def getData(page):
#内容url
url='https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100014352539&score=1&sortType=5&page='+str(page)+'&pageSize=10&isShadowSku=0&fold=1'
response=requests.get(url=url,headers=Headers,timeout=10)
soup=BeautifulSoup(response.text,'lxml')
#对获得的页面字符进行处理,并转成字典
context=eval(soup.find("p").text.replace("fetchJSON_comment98(","").replace(");","").replace("null","None").replace("false","False").replace("true","True"))
print(type(context))
print(context)
if __name__=='__main__':
for i in range(0,100):
getData(i)
n=random.randint(1,5)
time.sleep(n)
代码中有将程序循环延时1-5秒的操作是因为京东的反爬,没有时间延时的话很快就会被封

 浙公网安备 33010602011771号
浙公网安备 33010602011771号