
《机器学习(周志华)》笔记--神经网络(6)--其他常见神经网络:深度学习模型、深度学习的兴起(历史)、卷积神经网络(CNN)、局部连接、权值共享、卷积操作(convolution)、池化操作(pooling)、随机失活(dropout)、Lenet-5
四、其他常见神经网络
1、深度学习模型
感知机只包括输入层和输出层,只能处理线性任务,为了处理非线性任务,在输入和输出之间加入了隐层,隐层的目的是对数据进行加工处理传递给输出层。
为了解决更为复杂的问题,我们需要提升模型的学习能力,这时要增加模型的复杂度,有两种策略:
(1)一种是隐层保持不变,增加隐层神经元数目
(2)一种是增加隐层的数目
事实证明,增加隐层数目比增加隐层神经元数目更有效,随着隐层数目不断增加,神经网络越来越复杂,这就是深度学习模型。
究竟多少层的神经网络算是深度神经网络模型,没有确切的定义。对于深层神经网络模型因为模型复杂度提升了,也带了一定的问题:参数增加,级连难度增加,需要更多的数据进行训练,层数增加,误差梯度在反向传播时有可能会出现梯度消失的现象,因此难以直接使用经典的BP算法训练,而且过拟合的风险加大。
典型的深度学习模型就是很深层的神经网络。

2、深度学习的兴起(历史)
• 2006年 , Hinton发表了深度学习的 Nature 文章。
• 2012年 , Hinton 组参加 ImageNet 竞赛 , 使用 CNN 模型以超过第二名10个百分点的成绩夺得当年竞赛的冠军。
• 伴随云计算、大数据时代的到来,计算能力的大幅提升,使得深度学习模型在计算机视觉、自然语言处理、语音识别等众多领域都取得了较大的成功。
可以说,深度学习模型是现如今主流的机器学习方法。
3.1、卷积神经网络(CNN)
CNN是人工神经网络的一种,CNN源于日本福岛于1980年提出的感受页模型,1998年,Lecun等人提出了Lenet-5卷积神经网络模型,用于手写字体识别。
现如今,CNN成为深度学习领域的热点,特别是在图像分类和模式识别方面。
CNN相较于其他神经网络的特殊性在于权值共享和局部连接两个方面。CNN用局部感知和权值共享大大减少了参数,同时还具备其它优点。它们与自然图像自身具有的特性:特征的局部性与重复性完美贴合。
局部连接:
(是什么)即网络部分连通,每个神经元只与上一层的部分神经元相连,只感知局部,而不是整幅图像。(滑窗实现)
(可行性)局部像素关系紧密,较远像素相关性弱。
因此只需要局部感知,在更高层将局部的信息综合起来就得到了全局的信息。
受启发于生物视觉系统:局部敏感;对外界认知从局部到全局。
权值共享:
(是什么)从一个局部区域学习到的信息,应用到图像的其它地方去。即用一个相同的卷积核去卷积整幅图像,相当于对图像做一个全图滤波。一个卷积核对应的特征比如是边缘,那么用该卷积核去对图像做全图滤波,即是将图像各个位置的边缘都滤出来。(帮助实现不变性)。不同的特征靠多个不同的卷积核实现。
(可行性)图像的局部统计特征在整幅图像上具有重复性(即位置无关性)。即如果图像中存在某个基本图形,该基本图形可能出现在任意位置,那么不同位置共享相同权值可实现在数据的不同位置检测相同的模式。比如我们在第一个窗口卷积后得到的特征是边缘,那么这个卷积核对应的就是边缘特征的提取方式,那么我们就可以用这个卷积核去提取其它区域的边缘特征。
简单卷积神经网络:
from keras.datasets import mnist import matplotlib.pyplot as plt from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense,Dropout,Flatten from keras.layers.convolutional import Conv2D,MaxPooling2D from keras import backend backend.set_image_data_format('channels_first') (X_train,y_train),(X_test,y_test)=mnist.load_data() X_train=X_train.reshape(-1,1,28,28).astype('float32') X_test = X_test.reshape(-1,1,28,28).astype('float32') #格式化数据0~1 X_train = X_train/255 X_test = X_test/255 #进行one-hot编码 y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) num_classes = y_test.shape[1] #构建模型 model = Sequential() model.add(Conv2D(32,(5,5),input_shape=(1,28,28),activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.2)) model.add(Flatten()) model.add(Dense(128,activation='relu')) model.add(Dense(10,activation='softmax')) model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy']) model.summary() model.fit(X_train,y_train,epochs=2,batch_size=200) scores = model.evaluate(X_test,y_test) print('acc:%.2f%%' % (scores[1]*100))
图象识别实例:
# -*- coding: utf-8 -*- import matplotlib.pyplot as plt from keras.applications.vgg16 import VGG16 from keras.preprocessing import image from keras.applications.vgg16 import preprocess_input, decode_predictions import numpy as np def percent(value): return '%.2f%%' % (value * 100) model = VGG16(weights='imagenet', include_top=True) # Input:要识别的图像 img_path = 'tiger.jpg' #img_path = 'tiger.jpg' 并转化为224*224的标准尺寸 img = image.load_img(img_path, target_size=(224, 224)) x = image.img_to_array(img) #转化为浮点型 x = np.expand_dims(x, axis=0)#转化为张量size为(1, 224, 224, 3) x = preprocess_input(x) # 预测,取得features,维度为 (1,1000) features = model.predict(x) # 取得前五个最可能的类别及概率 pred=decode_predictions(features, top=5)[0] #整理预测结果,value values = [] bar_label = [] for element in pred: values.append(element[2]) bar_label.append(element[1]) #绘图并保存 fig=plt.figure(u"Top-5 预测结果") ax = fig.add_subplot(111) ax.bar(range(len(values)), values, tick_label=bar_label, width=0.5, fc='g') ax.set_ylabel(u'probability') ax.set_title(u'Top-5') for a,b in zip(range(len(values)), values): ax.text(a, b+0.0005, percent(b), ha='center', va = 'bottom', fontsize=7) fig = plt.gcf() plt.show()
3.2、卷积神经网络(CNN)结构
CNN结构:输入层,卷积层(convolution)、池化层(pooling)、随机失活(dropout),全连接层、输出层。

3.3、卷积操作(convolution)

我们用一个filter,往我们的图片上“盖”,覆盖一块跟filter一样大的区域之后,对应元素相乘,然后求和。计算一个区域之后,就向其他区域挪动,接着计算,直到把原图片的每一个角落都覆盖到了为止。这个过程就是 “卷积”。
卷积核与输入项的点积运算,卷积的结果称为特征图。CNN主要就是通过一个个的卷积核,不断地提取特征,从局部的特征到总体的特征,从而进行图像识别等等功能。
我们要学习的就是各个卷积核中的参数。
3.4、池化操作(pooling)
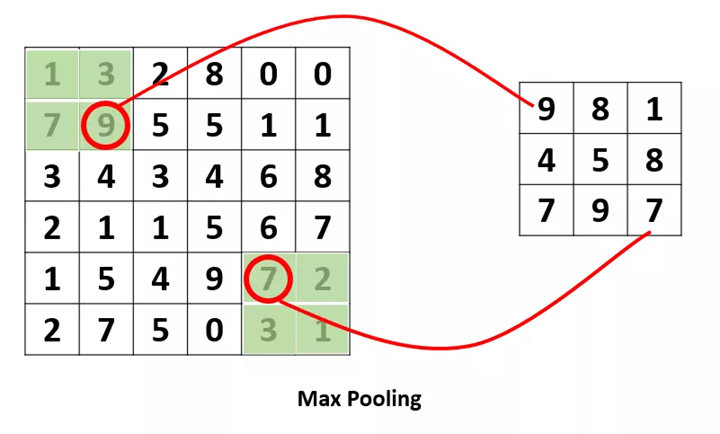
池化(下采样):是为了提取一定区域的主要特征,并减少参数数量,防止模型过拟合。
两种常用的方式:平均池化,最大池化。
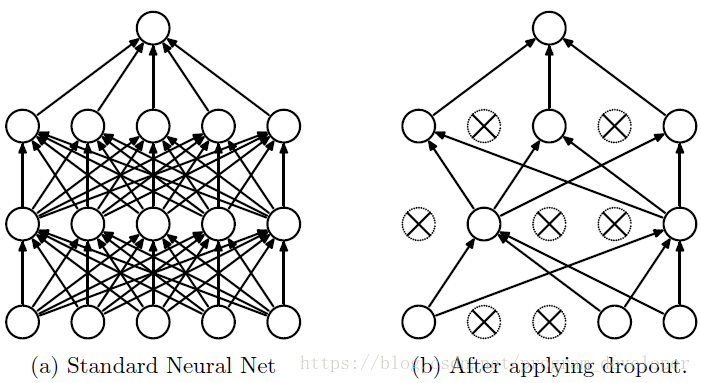
3.5、随机失活(dropout)
在训练的过程随机忽略部分神经元,对于处于失活状态的神经,它的不会对下层的神经元有任何影响,同时在反向传播误差时,与其相连的权值也不会进行任何修改,但这样可以使模型泛化性更强。
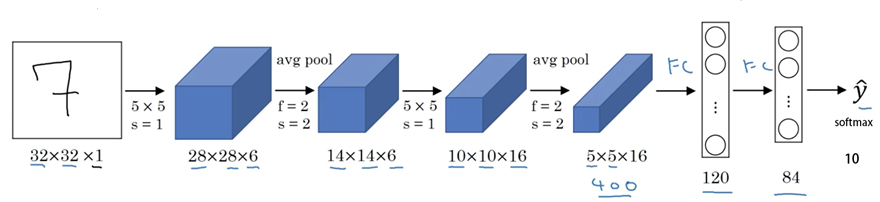
4、Lenet-5
wide = (wide + 2 * padding - kernel_size) / stride + 1
height = (height + 2 * padding - kernel_size) / stride + 1
#Lenet-5 from keras.models import Sequential from keras.layers import Dense,Flatten from keras.layers.convolutional import Conv2D,MaxPooling2D from keras import backend backend.set_image_data_format('channels_first') model = Sequential() model.add(Conv2D(filters=6,kernel_size=(5,5),input_shape=(1,32,32))) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Conv2D(filters=16,kernel_size=(5,5))) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Flatten()) model.add(Dense(120,activation='relu')) model.add(Dense(84,activation='relu')) model.add(Dense(10,activation='softmax')) model.summary()
5、AlexNet
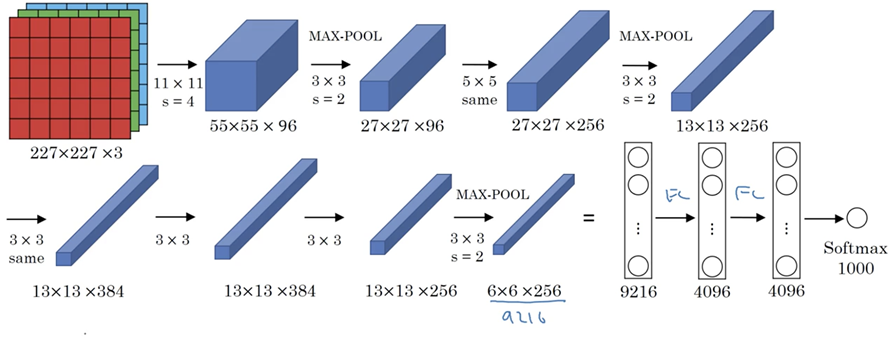
AlexNet与lenet5类似,但比lenet5更为复杂,利用了两块GPU进行计算,大大提高了运算效率,并且在ILSVRC-2012( ImageNet Large Scale Visual Recognition Challenge)竞赛中获得了top-5测试的15.3%error rate, 获得第二名的方法error rate 是 26.2%。
6、VGG16
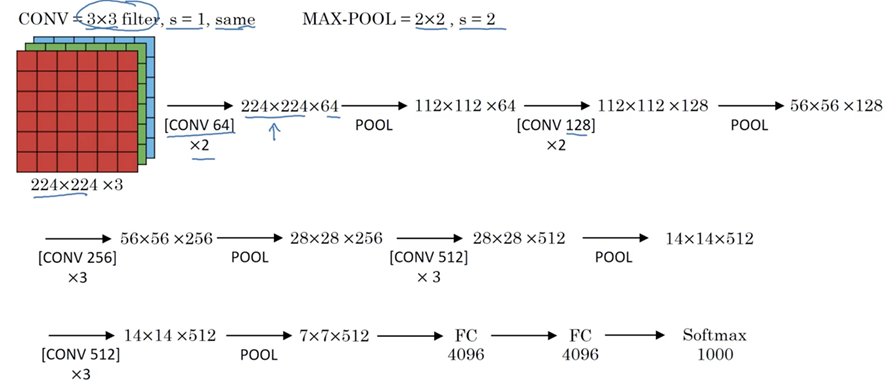
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号