
《机器学习(周志华)》笔记--决策树(3)--剪枝处理:预剪枝、后剪枝、预剪枝与后剪枝优缺点比较
五、剪枝处理
过拟合:在决策树学习过程中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能会因训练样本学得太好,以致于把训练集自身的一些特点当作所有数据都具有的一般性质导致过拟合。
剪枝:对付过拟合的一种重要手段,通过主动去掉一些分支来降低过拟合的风险。
基本策略:预剪枝和后剪枝。
预剪枝:对每个结点划分前先进行估计,若当前结点的划分不能带来决策树的泛化性能的提升,则停止划分,并标记为叶结点。
后剪枝:现从训练集生成一棵完整的决策树,然后自底向上对非叶子结点进行考察,若该结点对应的子树用叶结点能带来决策树泛化性能的提升,则将该子树替换为叶结点。
如何评估:留出法,即预留一部分数据用作“验证集”以进行性能评估。
举例:
我们将西瓜数据集随机分成两部分,如图5.0.1所示:
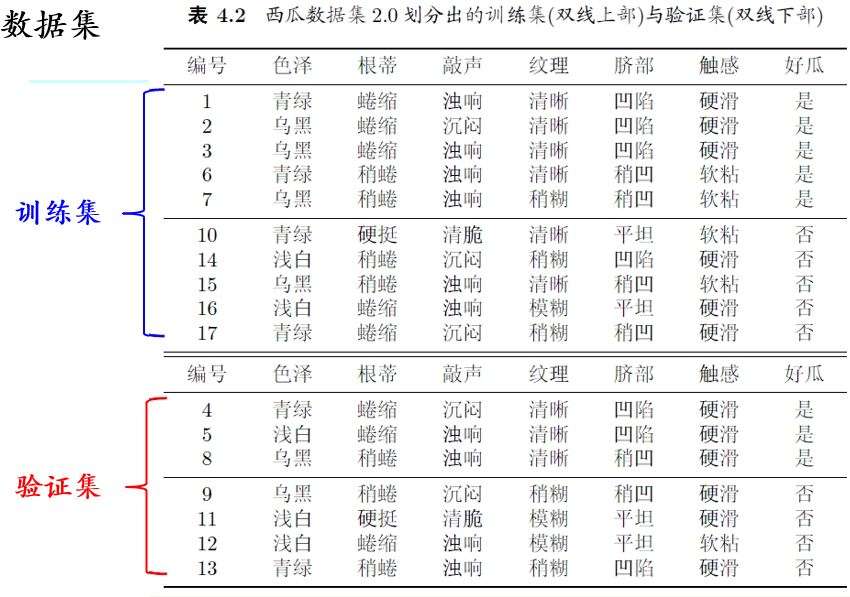
图 5.0.1
假设我们采用信息增益准则来进行划分属性选择,则从图5.0.1的训练集中会生成一个决策树,如图5.0.2.
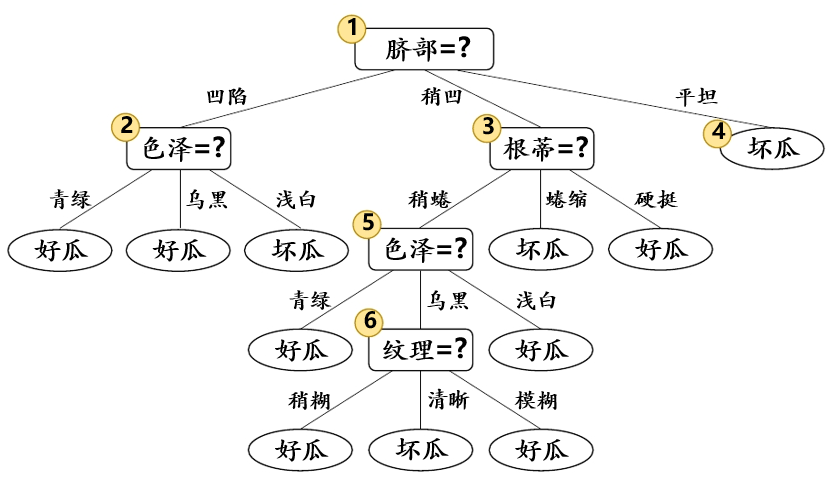
图5.0.2
划分前:5个正例,5个负例,拥有样本数最对的类别。根据前面讲到的信息增益准则,得到了一个决策树。进行了5次划分
1、预剪枝
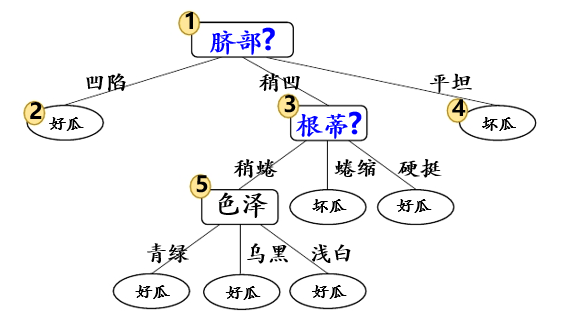
基于信息增益准则,我们会选取属性“脐部”来对测试集进行划分,并产生三个分支。然而,是否应该进行这个划分呢?预剪枝要对划分前后的泛化性能进行估计。
划分之前,所有样例集中在根结点,如图5.1.1
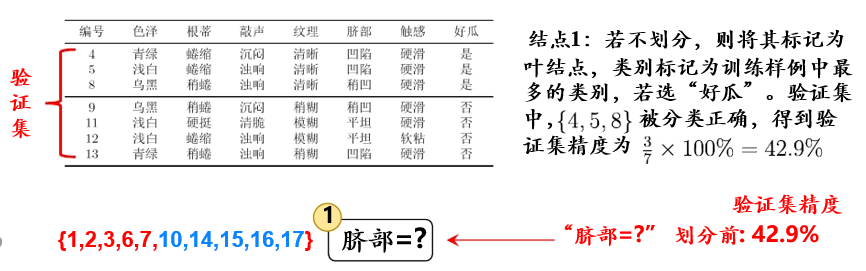
图5.1.1
在用属性“脐部”划分之后,如图5.1.2
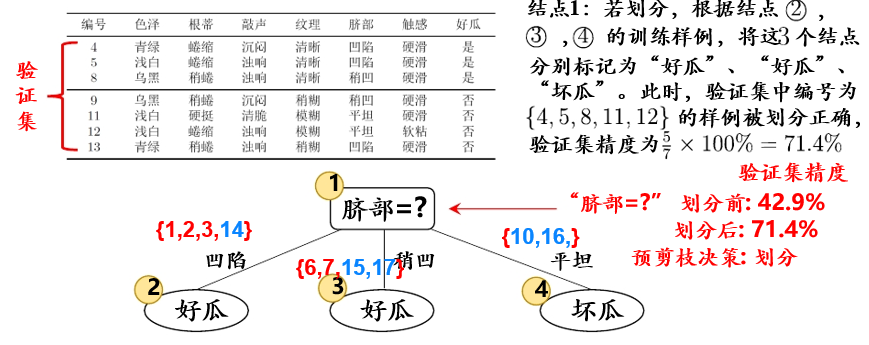
图5.1.2
基于预剪枝策略从表5.0.1数据所生成的决策树如图5.1.3
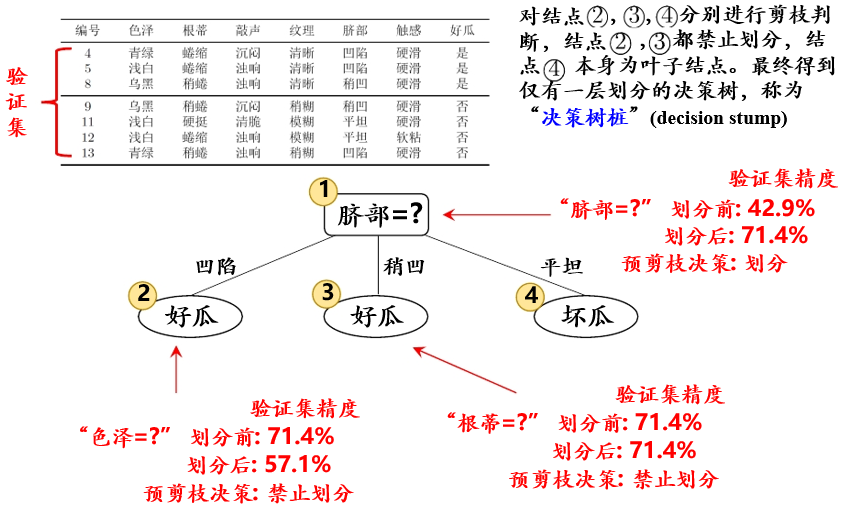
图5.1.3
2、后剪枝
后剪枝先从训练集中生成一棵完整的决策树,其验证集精度测得为 42.9%。
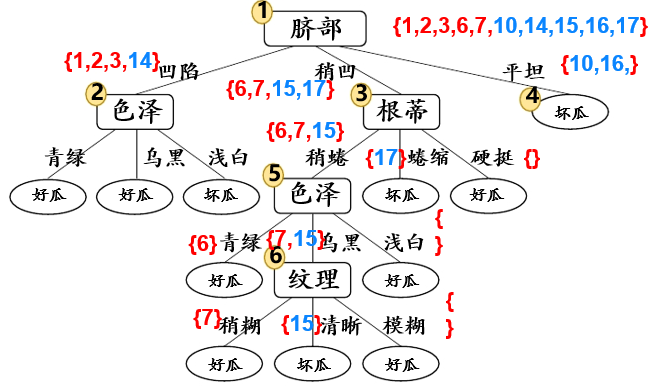
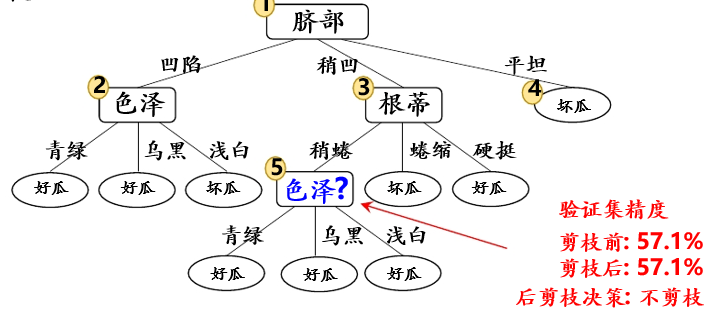
首先考虑结点⑥,若将其替换为叶结点,根据落在其上的训练样例{7,15},将其标记为“好瓜”,测得验证集精度提高至 57.1%,于是决定剪枝:


然后考虑结点⑤,若将其替换为叶结点,根据落在其上的训练样例{6,7,15},将其标记为“好瓜”,测得验证集精度仍为 57.1%,可以不剪枝:
对结点②,若将其替换为叶结点,根据落在其上的训练样例{1,2,3,14},将其标记为“好瓜”,测得验证集精度提升至 71.4%,决定剪枝:
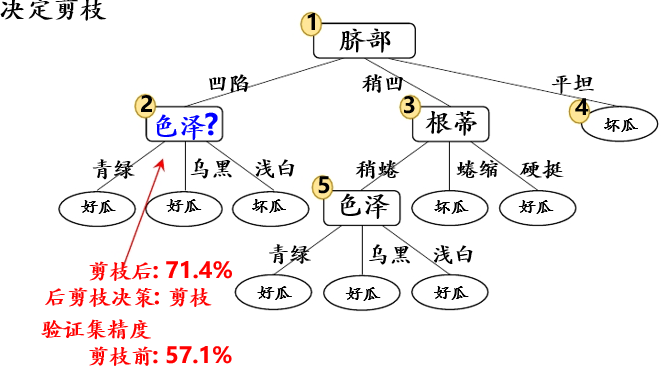
对结点③和①,先后替换为叶结点,均未测得验证集精度提升,于是不剪枝:
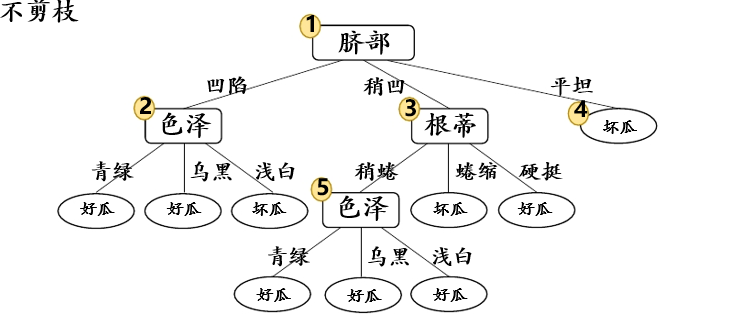
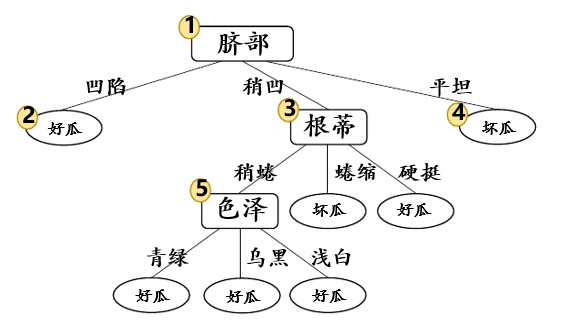
最终,后剪枝得到的决策树:
3、预剪枝与后剪枝优缺点比较
(1)时间开销
• 预剪枝:训练时间开销降低,测试时间开销降低
• 后剪枝:训练时间开销增加,测试时间开销降低
(2)过/欠拟合风险
• 预剪枝:过拟合风险降低,欠拟合风险增加
• 后剪枝:过拟合风险降低,欠拟合风险基本不变
(3)泛化性能:后剪枝通常优于预剪枝


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界