
机器学习--朴素贝叶斯算法原理、方法及代码实现
一、朴素的贝叶斯算法原理
贝叶斯分类算法以样本可能属于某类的概率来作为分类依据,朴素贝叶斯分类算法是贝叶斯分类算法中最简单的一种,朴素的意思是条件概率独立性。
条件概率的三个重要公式:
(1)概率乘法公式:
P(AB)= P(B) P(A|B) = P(A) P(B|A) =P(BA)
(2)全概率公式:
![]()
(3)贝叶斯公式:
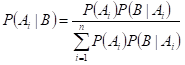
如果一个事物在一些属性条件发生的情况下,事物属于A的概率>属于B的概率,则判定事物属于A,这就是朴素贝叶斯的基本思想。
二、算法实现一般步骤
(1)分解各类先验样本数据中的特征。
(2)计算各类数据中,各特征的条件概率(比如:特征1出现的情况下,属于A类的概率p(A|特征1),属于B类的概率p(B|特征1),属于C类的概率p(C|特征1)......)。
(3)分解待分类数据中的特征(特征1、特征2、特征3、特征4......)。
(4)计算各特征的各条件概率的乘积,如下所示:
判断为A类的概率:p(A|特征1)*p(A|特征2)*p(A|特征3)*p(A|特征4).....
判断为B类的概率:p(B|特征1)*p(B|特征2)*p(B|特征3)*p(B|特征4).....
判断为C类的概率:p(C|特征1)*p(C|特征2)*p(C|特征3)*p(C|特征4).....
......
(5)结果中的最大值就是该样本所属的类别。
三、应用举例
二分类问题:大众点评、淘宝等电商上都会有大量的用户评论,有差评(1),有好评(0),现需要使用朴素贝叶斯分类算法来自动分类用户评论。
四、实际问题代码实现
from numpy import * #贝叶斯算法 def loadDataSet(): trainData=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] labels=[0, 1, 0, 1, 0, 1] #1表示侮辱性言论,0表示正常言论 return trainData, labels #生成词汇表 def createVocabList(trainData): VocabList = set([]) for item in trainData: VocabList = VocabList|set(item) #取两个集合的并集 return sorted(list(VocabList)) #对结果排序后返回 #对训练数据生成只包含0和1的向量集 def createWordSet(VocabList, trainData): VocabList_len = len(VocabList) #词汇集的长度 trainData_len = len(trainData) #训练数据的长度 WordSet = zeros((trainData_len,VocabList_len)) #生成行长度为训练数据的长度 列长度为词汇集的长度的列表 for index in range(0,trainData_len): for word in trainData[index]: if word in VocabList: #其实也就是,训练数据包含的单词对应的位置为1其他为0 WordSet[index][VocabList.index(word)] = 1 return WordSet #计算向量集每个的概率 def opreationProbability(WordSet, labels): WordSet_col = len(WordSet[0]) labels_len = len(labels) WordSet_labels_0 = zeros(WordSet_col) WordSet_labels_1 = zeros(WordSet_col) num_labels_0 = 0 num_labels_1 = 0 for index in range(0,labels_len): if labels[index] == 0: WordSet_labels_0 += WordSet[index] #向量相加 num_labels_0 += 1 #计数 else: WordSet_labels_1 += WordSet[index] #向量相加 num_labels_1 += 1 #计数 p0 = WordSet_labels_0 * num_labels_0 / labels_len p1 = WordSet_labels_1 * num_labels_1 / labels_len return p0, p1 trainData, labels = loadDataSet() VocabList = createVocabList(trainData) train_WordSet = createWordSet(VocabList,trainData) p0, p1 = opreationProbability(train_WordSet, labels) #到此就算是训练完成
#开始测试 testData = [['not', 'take', 'ate', 'my', 'stupid']] #测试数据 test_WordSet = createWordSet(VocabList, testData) #测试数据的向量集 res_test_0 = [] res_test_1 = [] for index in range(0,len(p0)): print(p0[index]) if test_WordSet[0][index] == 0: res_test_0.append((1-p0[index]) * test_WordSet[0][index]) res_test_1.append((1-p1[index]) * test_WordSet[0][index]) else: res_test_0.append(p0[index] * test_WordSet[0][index]) res_test_1.append(p1[index] * test_WordSet[0][index]) if sum(res_test_0) > sum(res_test_1): print("属于0类别") else: print("属于1类别")
运行结果:

