
《机器学习(周志华)》笔记--模型的评估与选择(3)--衡量回归的性能指标:MSE、RMSE、MAE、R-Squared
四、衡量回归的性能指标
1、均方误差-MSE(Mean Squared Error)
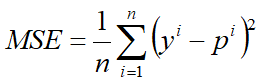
其中y^i表示第 i 个样本的真实标签,p^i表示模型对第 i 个样本的预测标签。
线性回归的目的就是让损失函数最小。那么模型训练出来了,我们在测试集上用损失函数来评估模型就行了。
2、均方根误差-RMSE(Root Mean Squard Error)
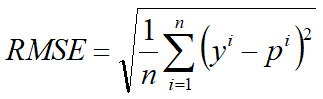
RMSE 其实就是 MSE 开个根号。有什么意义呢?其实实质是一样的。只不过用于数据更好的描述。
例如:要做房价预测,每平方是万元,我们预测结果也是万元。那么差值的平方单位应该是千万级别的。那我们不太好描述自己做的模型效果。怎么说呢?我们的模型误差是多少千万?于是干脆就开个根号就好了。我们误差的结果就跟我们数据是一个级别的了,在描述模型的时候就说,我们模型的误差是多少万元。
3、平均绝对误差-MAE
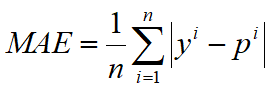
MAE 虽然不作为损失函数,确是一个非常直观的评估指标,它表示每个样本的预测标签值与真实标签值的 L1 距离。
MAE与MSE对比:MSE相当于L2范数,MAE相当于L1范数。次数越高,计算结果就越与较大的值有关,而忽略较小的值,所以这就是为什么MSE针对异常值更敏感的原因(即有一个预测值与真实值相差很大,那么MSE就会很大)
注:
L1范数和L2范数的区别(范数是具有“长度”概念的函数。在向量空间内,为所有的向量的赋予非零的增长度或者大小。不同的范数,所求的向量的长度或者大小是不同的。):
(1)L0范数是指向量中非0的元素的个数。(L0范数很难优化求解)
(2)L1范数是指向量中各个元素绝对值之和,可以进行特征选择,即让特征的系数变为0,L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。
(3)L2范数是指向量各元素的平方和然后求平方根,可以防止过拟合,提升模型的泛化能力,有助于处理 condition number不好下的矩阵(数据变化很小矩阵求解后结果变化很大),L2对大数,对outlier离群点更敏感!
(4)下降速度:最小化权值参数L1比L2变化的快
(5)模型空间的限制:L1会产生稀疏 L2不会。
(6)L1会趋向于产生少量的特征,而其他的特征都是0;而L2会选择更多的特征,这些特征都会接近于0。
4、R-Squared--决定系数-R2
上面的几种衡量标准针对不同的模型会有不同的值。比如说预测房价 那么误差单位就是万元。数子可能是 3,4 ,5 之类的。那么预测身高就可能是 0.1,0.6 之类的。没有什么可读性,到底多少才算好呢?不知道,那要根据模型的应用场景来。 看看分类算法的衡量标准就是正确率,而正确率又在 0~1 之间,最高百分之百,最低 0 。如果是负数,则考虑非线性相关。很直观,而且不同模型一样的。那么线性回归有没有这样的衡量标准呢?
R-Squared 就是这么一个指标,公式如下:
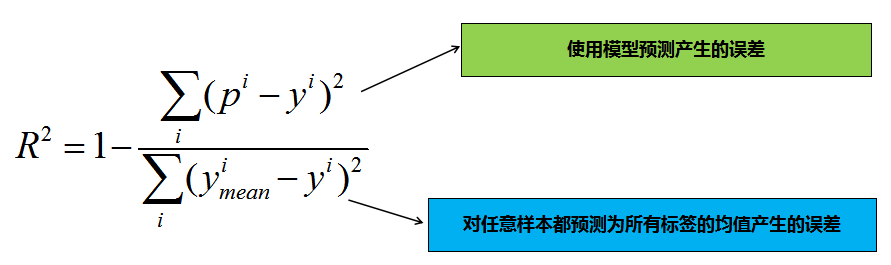
ymean即y的均值,表示所有测试样本标签值的均值。
分子:需要衡量的模型
分母:基准模型(将均值作为预测值)
注:基准模型:将y的均值作为预测值。分子对应的的是需要衡量的模型,分母对应的是基准模型。
(1)R2=1,模型对所有的数据预测准确,模型的性能最优;
(2)R2=0,模型的性能与基准模型相同;
(3)R2<0,模型的性能低于基准模型,可以考虑该数据不线性相关。
