
机器学习理论基础--常用算法思想要点
一、什么是机器学习?简述机器学习的一般过程。
机器学习是通过算法使得机器从大量历史数据中学习规律,从而对新样本做分类或者预测。
一个机器学习过程主要分为三个阶段:
(1)训练阶段,训练阶段的主要工作是根据训练数据建立模型。
(2)测试阶段,测试阶段的主要工作是利用验证集对模型评估与选择
(3)工作阶段,工作阶段的主要工作是利用建立好的模型对新的数据进行预测与分类。
二、简述 K 折交叉验证与留一法的基本思想及其特点。
基本思想:
K 折交叉验证:将数据 D 划分为 k 个大小相等的互斥子集;然后用其中的 k-1 个子集作为训练集,余下的那个子集作为测试集;这样就可以得到 k 组训练集/测试集,这样就可以进行 k 次训练和测试,最终返回的是这 k 个测试结果的平均值。
留一法:k 折交叉验证的一种特例,每次取一个样本作为测试集,其余的样本组成的集合作为训练集,训练和测试的次数等于样本的个数。
特点:
K 折交叉验证:其稳定性和保真性在很大程度上取决于 k 的取值。
留一法:留一法的评估结果往往被认为是比较准确的,其最大的缺陷是当数据集较大时,模型的开销非常大。
三、简述什么是欠拟合和过拟合、产生的原因以及如何解决。
欠拟合:模型在训练集上的误差较高。原因:模型过于简单,没有很好的捕捉到数据特征,不能很好的拟合数据。解决方法:模型复杂化、增加更多的特征,使输入数据具有更强的表达能力等。
过拟合:在训练集上误差低,测试集上误差高。原因:模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,模型泛化能力太差。解决方法:降维、增加训练数据、正则约束等。
四、简述线性回归与逻辑回归的区别。
1)任务不同:回归模型是对连续的量进行预测;分类模型是对离散值/类别进行;
2)输出不同:回归模型的输出是一个连续的量,范围在[-∞,+∞],分类模型的输出是数据属于某种类别的概率,范围在[0,1]之间;
3)参数估计方法不同:线性回归中使用的是最小化平方误差损失函数,对偏离真实值越远的数据惩罚越严重;逻辑回归使用对数似然函数进行参数估计,使用交叉熵作为损失函数,对预测错误的惩罚是随着输出的增大,逐渐逼近一个常数。
五、简述剪枝的目的以及常用的两种剪枝方式的基本过程。
目的:剪枝是决策树学习算法对付“过拟合”的主要手段,通过主动去掉一些分支来降低过拟合的风险。决策树剪枝的基本策略有“预剪枝”和“后剪枝”。
“预剪枝”对每个结点划分前先进行估计,若当前结点的划分不能带来决策树的泛化性能的提升,则停止划分,并标记为叶结点。
“后剪枝”:先从训练集生成一棵完整的决策树,然后自底向上对非叶子结点进行考察,若该结点对应的子树用叶结点能带来决策树泛化性能的提升,则将该子树替换为叶结点
六、简述 K 均值聚类算法的流程。
假设有 m 条数据,n 个特性,则 K 均值聚类算法的流程如下:
1)随机选取 k 个点作为起始中心(k 行 n 列的矩阵,每个特征都有自己的中心;
2)遍历数据集中的每一条数据,计算它与每个中心的距离;
3)将数据分配到距离最近的中心所在的簇;
4)使用每个簇中的数据的均值作为新的簇中心;
5)如果簇的组成点发生变化,则跳转执行第 2 步;否则,结束聚类。
七、简述什么是降维以及 PCA 算法的流程。
降维是通过某种数学变换将原始高维属性空间转变为一个低维子空间,保留重要性比较高的特征维度,去除冗余的特征。
主元成分分析 PCA 使用最广泛的数据降维算法,其一般流程如下:
(1)样本零均值化;
(2)计算数据的协方差矩阵;
(3)计算协方差矩阵的特征值与特征向量;
(4)按照特征值,将特征向量从大到小进行排序;
(5)选取前 k 个特征向量作为转换矩阵;
(6)零均值化后的数据与转换矩阵做矩阵乘法获得降维后的数据。
八、简述贝叶斯网的组成,贝叶斯网中结点的三种连接方式,并分析它们的独立性。
一个贝叶斯网 B 由结构 G 和参数Ɵ组成。
G是一个有向无环图,其中每个结点对应于一个属性,若两个属性由直接依赖关系,则它们由一条边连接起来。
参数Ɵ包含了每个属性的条件概率表,定量描述这种依赖关系。
(1)同父结构,c已知的情况下,a,b独立。
(2)V型结构,c未知情况下,a,b独立。
(3)顺序结构,c已知情况下,a,b独立。

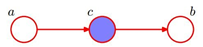
(1) (2) (3)
九、简述卷积神经网络与传统的神经网络的区别。
传统的神经网络是一种层级结构,由输入层,隐藏层,输出层构成,每层神经元与下层神经元完全互连,神经元之间不存在同层连接,也不存在跨层连接。
卷积神经网络相较于传统神经网络的特殊性在于权值共享和局部连接两个方面:
(1)局部连接:每个神经元只与上一层的部分神经元相连,只感知局部, 而不是整幅图像.;
(2)权值共享:每一个神经元都可以看作一个滤波器,同一个神经元使用一个固定的卷积核去卷积整个图像, 可以认为一个神经元只关注一个特征. 而不同的神经元关注多个不同的特征。
十、简述基于核函数的非线性支持向量机的基本思想。
核函数不显示定义映射函数,在原始样本空间中通过计算核函数的值来代替特征空间中的内积。基于核函数的非线性支持向量机的基本思想就是通过非线性变换将输入空间对应到一个特征空间上,使得输入空间中的超曲面模型对应于特征空间上的一个超平面模型也就是支持向量机,问题转化为在特征空间中求解支持向量机。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号