大数据基础--互联网大数据处理(刘鹏《大数据》课后习题答案)
1.简述互联网信息抓取的方式。
互联网信息自动抓取,最常见且有效的方式是使用网络爬虫。
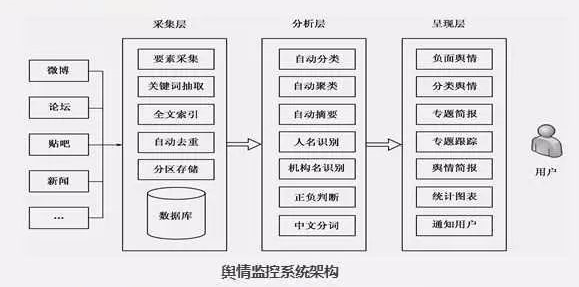
2.简述舆情系统的组成架构。
用户终端->采集层->分析层->呈现层->用户
3.中文分词算法可以分为哪几类?
(1)基于字符串匹配的分词方法,它是待处理的中文字符串与一个“尽可能全面”的词典中的词条按照一定的规则进行匹配,若某字符串存在于词典中,则认为该字符串匹配成功。
(2)基于统计的分词方法,由于词是特定的字组合方式,那么在上下文中,相邻的单字共同出现的频率越高,则在该种字组合方式下就越有可能构成了一个词。
(3)基于理解的分词方法,该方法通过语义信息和语句信息来解决歧义分词问题,并且在分词的同时进行语义和句法分析。
4.常用的文本分词工具有哪些?
(1)MMSEG分词工具
(2)斯坦福NLTK分词工具
5.简述倒排索引的原理。
倒排索引(Inverted Index),也称为“反向索引”或“反向文件”,是一种索引数据结构。倒排索引在“内容”(例如,单词、数字)和存放内容的“位置”(例如,数据库、文件、一组文件)之间建立映射,其目的在于快速全文检索和使用最小处理代价将新文件添加进数据库。通过倒排索引,可以快速地根据“内容”找到包含它的文件。
6.简述倒排索引的更新策略。

7.简述倒排索引的实现。

8.常用的网页排序算法有哪些?
(1)基于访问量的排序算法。此算法,越重要的网页,访问量越大。
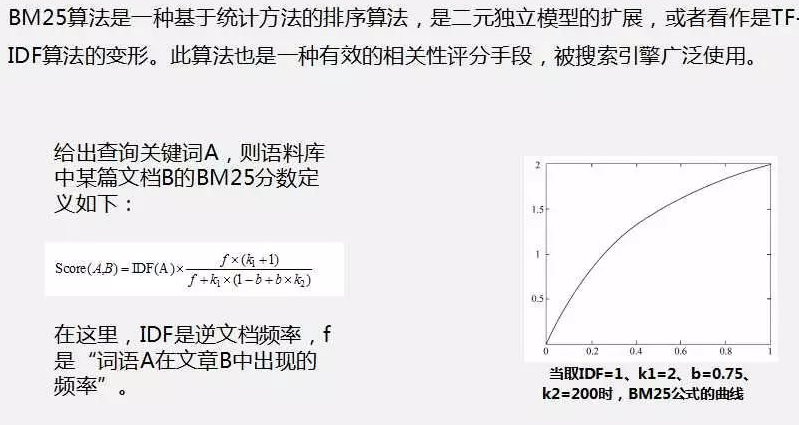
(2)基于词频统计和词语位置加权的排序算法,例如TF-IDF算法、BM25算法。
(3)基于链接分析的排序算法,例如PageRank算法、Reputation算法。
(4)基于智能化的排序算法。
9.简述TD-IDF算法主要思想。

10.简述BM算法主要思想。
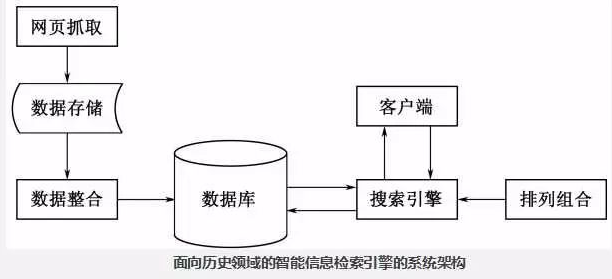
11.简述历史信息检索的系统架构。
面向历史领域的智能信息检索引擎,从互联网上抓取重大历史事件的网站内容,经过数据汇聚和整合从而在数据库中建立专门的数据库。通过在数据库中检索与用户查询条件匹配的相关记录,然后将查询结果进行优化,并按照一定的排序方式将最终结果返回给用户。