
机器学习--线性回归算法的原理及优缺点
一、线性回归算法的原理
回归是基于已有数据对新的数据进行预测,比如预测股票走势。这里我们主要讲简单线性回归。基于标准的线性回归,可以扩展出更多的线性回归算法。
线性回归就是能够用一个直线较为精确地描述数据之间的关系,这样当出现新的数据的时候,就能够预测出一个简单的值。
线性回归的模型形如:
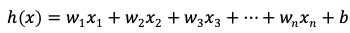
线性回归得出的模型不一定是一条直线:
(1)在只有一个变量的时候,模型是平面中的一条直线;
(2)有两个变量的时候,模型是空间中的一个平面;
(3)有更多变量时,模型将是更高维的。
线性回归模型有很好的可解释性,可以从权重W直接看出每个特征对结果的影响程度。线性回归适用于X和y之间存在线性关系的数据集,可以使用计算机辅助画出散点图来观察是否存在线性关系。我们尝试使用一条直线来拟合数据,使所有点到直线的距离之和最小。
实际上,线性回归中通常使用残差平方和,即点到直线的平行于y轴的距离而不用垂线距离,残差平方和除以样本量n就是均方误差。均方误差作为线性回归模型的损失函数(cost function)。使所有点到直线的距离之和最小,就是使均方误差最小化,这个方法叫做最小二乘法。
损失函数公式:
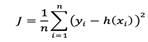 因为
因为 ![]()
最后通过求解,得到w及b的计算公式分别如下:
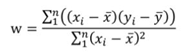 ,
, ![]()
推理过程:

假设我们找到了最佳拟合的直线方程 : ![]() ,
,
则对每一个样本点 ![]() ,根据我们的直线方程,预测值为:
,根据我们的直线方程,预测值为:![]() ,其对应的真值为
,其对应的真值为 ![]() 。
。
我们希望 ![]() 和
和 ![]() 的差距尽量小,这里我们用
的差距尽量小,这里我们用 ![]() 表达
表达 ![]() 和
和 ![]() 的距离,
的距离,
考虑所有样本则为:![]()
我们的目标是使 ![]() 尽可能小,而
尽可能小,而 ![]() ,所以我们要找到 a 、b ,使得
,所以我们要找到 a 、b ,使得 ![]() 尽可能小。
尽可能小。
![]() 被称为损失函数或效用函数。
被称为损失函数或效用函数。
通过分析问题,确定问题的损失函数或效用函数,通过最优化损失函数或者效用函数,获得机器学习的模型,这是参数学习算法的一般套路。
求损失函数可转化为典型的最小二乘法问题: 最小化误差的平方。
最小二乘法的求解过程:
目标:找到 a 、b ,使得 ![]() 尽可能小。
尽可能小。
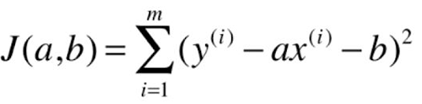

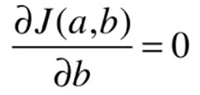
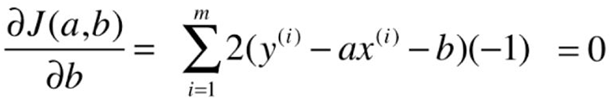
![]()

![]()
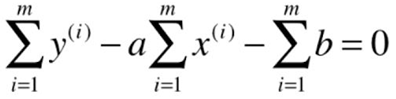
![]()

![]()

![]()
![]()
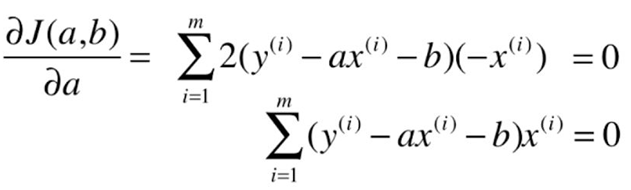
![]()
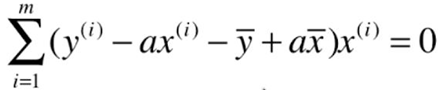
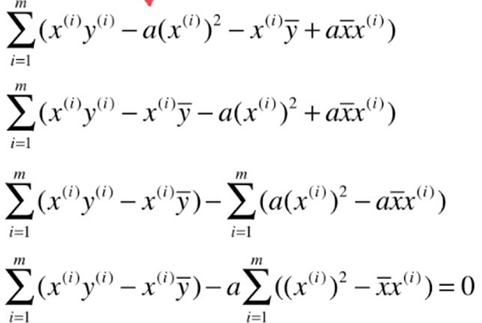
![]()
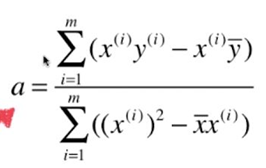
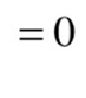

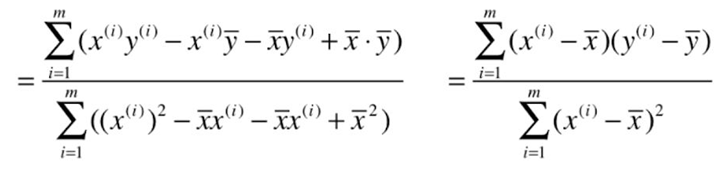
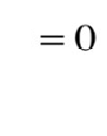
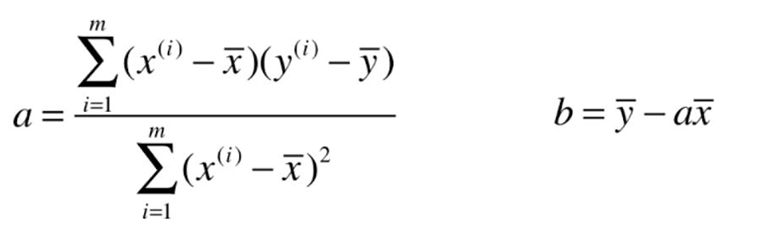
一般过程:
其中第
线性模型通过建立线性组合进行预测。我们的假设函数为:
其中
令
损失函数为均方误差,即
最小二乘法求解参数,损失函数
令

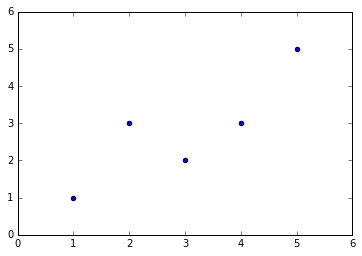
import numpy as np import matplotlib.pyplot as plt x=np.array([1,2,3,4,5],dtype=np.float) y=np.array([1,3.0,2,3,5]) plt.scatter(x,y) x_mean=np.mean(x) y_mean=np.mean(y) num=0.0 d=0.0 for x_i,y_i in zip(x,y): num+=(x_i-x_mean)*(y_i-y_mean) d+=(x_i-x_mean)**2 a=num/d b=y_mean-a*x_mean y_hat=a*x+b plt.figure(2) plt.scatter(x,y) plt.plot(x,y_hat,c='r') x_predict=4.8 y_predict=a*x_predict+b print(y_predict) plt.scatter(x_predict,y_predict,c='b',marker='+')
输出结果:
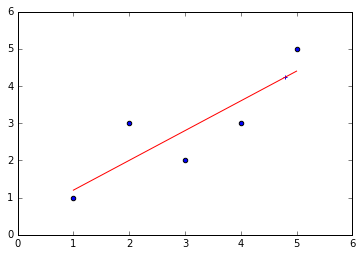
2.基于sklearn的简单线性回归
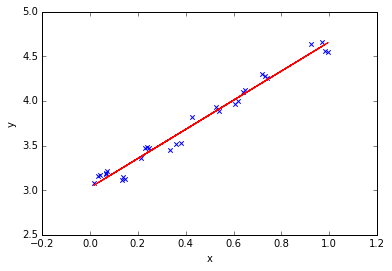
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression # 线性回归 # 样本数据集,第一列为x,第二列为y,在x和y之间建立回归模型 data=[ [0.067732,3.176513],[0.427810,3.816464],[0.995731,4.550095],[0.738336,4.256571],[0.981083,4.560815], [0.526171,3.929515],[0.378887,3.526170],[0.033859,3.156393],[0.132791,3.110301],[0.138306,3.149813], [0.247809,3.476346],[0.648270,4.119688],[0.731209,4.282233],[0.236833,3.486582],[0.969788,4.655492], [0.607492,3.965162],[0.358622,3.514900],[0.147846,3.125947],[0.637820,4.094115],[0.230372,3.476039], [0.070237,3.210610],[0.067154,3.190612],[0.925577,4.631504],[0.717733,4.295890],[0.015371,3.085028], [0.335070,3.448080],[0.040486,3.167440],[0.212575,3.364266],[0.617218,3.993482],[0.541196,3.891471] ] #生成X和y矩阵 dataMat = np.array(data) X = dataMat[:,0:1] # 变量x y = dataMat[:,1] #变量y # ========线性回归======== model = LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False) model.fit(X, y) # 线性回归建模 print('系数矩阵:\n',model.coef_) print('线性回归模型:\n',model) # 使用模型预测 predicted = model.predict(X) plt.scatter(X, y, marker='x') plt.plot(X, predicted,c='r') plt.xlabel("x") plt.ylabel("y")
输出结果:
系数矩阵:
[ 1.6314263]
线性回归模型:
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界