
TCP系列54—拥塞控制—17、AQM及ECN
一、概述
ECN的相关内容是在RFC3168中定义的,这里我简单描述一下RFC3168涉及的主要内容。
1、AQM和RED
目前TCP中多数的拥塞控制算法都是通过缓慢增加拥塞窗口直到检测到丢包来进行慢启动的,这就会导致数据包在路由器缓存队列堆积,当路由器没有复杂的调度和缓存管理策略的时候,路由器一般简单的按照先进先出(FIFO)方式处理数据包,并在缓存队列满的时候就会丢弃新数据包(drop tail),这种FIFO/drop tail的路由器称为passive路由器,会导致多个TCP流同时检测到丢包,削减拥塞窗口,并进行对应的数据包重传流程。而active的路由器则会有相对高级的调度和队列缓存策略,这种路由器用来管理缓存队列的方法就称为AQM(active queue management)机制。路由器的AQM机制则会在路由器队列满之前探测到拥塞,并提供一个拥塞指示。AQM可以使用丢包或者本文后面要介绍的IP头中的Congestion Experienced (CE) codepoint来指示拥塞,这样就削减了丢包重传的影响,降低了网络延迟。之所以把CE指示放到IP头中是因为多数路由器对IP头的处理效率要高于对IP选项的处理效率。
Random Early Detection (RED)则是AQM机制中用来探测拥塞和控制拥塞标记的一种方法。RED中有两个门限一个是minthresh,另外一个是maxthresh,当平均队列长度小于minthresh的时候,这个数据包总是会被接收处理,当平均队列长度超过maxthresh的时候,这个数据包总是会被用来指示拥塞(可能通过丢包或者设置CE来指示拥塞),当平均队列长度位于二者之间的时候,则会有一定的概率这个数据包被用来指示拥塞。RED算法是很多用在路由器和交换机中类似变种的基础,例如思科的WRED。
2、ECN
ECN(Explicit Congestion Notification)则是在AQM机制的基础上,路由器显式指示TCP发生拥塞的的一种机制,中文一般称呼为显式拥塞通告或者显式拥塞通知。之前我们介绍的TCP的拥塞控制的相关特性都是假设TCP端与端之间的链路为一个黑盒,使用丢包来作为网络拥塞的指示,在丢包后进行重传,并开始慢启动或者快速恢复等过程。但是有些交互式操作例如网页浏览或者音视频传输等应用对于丢包和时延很敏感,因此传统的基于丢包检测拥塞的方法会使得这类应用的体验变差。如果传输层也支持ECN功能,那么可以在IP报文头中设置一个ECT(ECN-Capable Transport)指示,当中间路由器的RED算法检测到某个数据包应该用来指示拥塞的时候,如果这个数据包的ECT指示有效,那么就可以把这个数据包标记为CE,接着当接收端TCP收到这个数据包的时候,如果发现CE标志有效,那么就可以在随后的ACK报文的TCP头中设置ECN-Echo标志位来拥塞指示,发送端接收到这个拥塞指示的时候就可以对网络拥塞作出对应的响应,并在随后的数据包中把TCP头中的CWR标志为置位,接收端收到CWR指示的时候就会知道发送端已经收到并处理ECN-Echo标志,随后的ACK报文则不再继续设置ECN-Echo标志(注意pure ACK是不可靠传输的,因此接收端需要一直发送ECN-Echo直到收到发送端的CWR指示)。TCP发送端在收到ECN-Echo指示后一般拥塞状态会切换到CWR,之前介绍过CWR是一个与Recovery状态类似的状态。
因为一些向后兼容的问题,目前部分系统对ECN的设置是默认关闭的,因此RFC7514提出了一个新的显示拥塞指示机制——RECN(Really Explicit Congestion Notification),RECN通过ICMP报文来显式的指示拥塞。本系列以介绍TCP为主,RECN相关协议格式请参考RFC7514。
3、协议格式
IP头中有个ECN field,上文提到的CE和ECT的格式如下。

从上图可以看到ECT有两种场景,ECT(0)和ECT(1)都表示发送端传输层支持ECN,按照RFC3168协议section18.1.1和section20的描述,ECT(1)是一个nonce,可以用来检验路由器是否会擦出CE指示,ECT(1)也曾打算用作其他指示,但是综合对比后还是涉及用来作为nonce了。
而上文中提到的TCP头中的ECN-Echo标志位即为ECE标志位,TCP头中的ECE标志位和CWR标志位请参考前面介绍TCP头的相关文章。
4、linux相关
linux中的TCP只使用ECT(0)来指示传输层支持ECN。在/proc/sys/net/ipv4目录下有两个设置参数与ECN相关:
tcp_ecn:0表示关闭ECN功能,既不会初始化也不会接受ECN,1表示主动连接和被动连接时候都会尝试使能ECN,2表示主动连接时候不会使能ECN,被动连接的时候会尝试使能ECN
tcp_ecn_fallback:这个参数设置为非0时,如果内核侦测到ECN的错误行为,就会关闭ECN功能。 这个参数实际上是控制后向兼容的一个参数,TCP建立连接的时候需要进行ECN协商过程,SYN报文中需要同时设置CWR和ECE标志位,如果tcp_ecn_fallback设置为非0,那么重传SYN报文的时候就会取消CWR和ECE标志的设置。
关于Linux中ECN的实现还有几点需要说明
-
在IP路由表中也可以设置ECN的特性使能情况,我们后面会通过示例演示。
-
linux设置使用DCTCP拥塞控制算法的时候也会使能ECN功能。DCTCP是斯坦福和微软一起开发的一个使用RED和ECN的拥塞控制算法,可以有效的降低了缓存队列的占用。
-
协议要求一个发送窗口内(或者RTT内),发送端应该对ECE只响应一次,这个在linux中是通过high_seq状态变量实现的,当TCP进入CWR状态的时候,在次收到ECE标志,不会在重新削减ssthresh,当收到的报文中ack number大于high_seq时候,TCP退出CWR状态切换到Open状态。后面会有示例
-
协议要求发送端削减cwnd的时候(例如由于快速重传、RTO超时重传等原因),需要在接下来第一个新数据包中设置TCP头中的CWR标志。对于linux来说因为采用PRR的cwnd更新算法,因此实际上是相当于削减ssthresh后,需要在接下来第一个新数据包中设置TCP头中的CWR标志,请参考下面的示例
-
按照RFC3168 section6.1.1,如果要使用ECN功能,需要TCP在建立连接的时候进行协商,这里不做文件介绍了,直接通过后面的示例演示
-
SYN cookie场景下,Linux TCP需要通过SYN-ACK报文中TSopt选项的TSval中第5比特位保存是否使能ECN的信息,因此SYN cookie下如果没有协商成功TSopt选项也不会也不会使能ECN。
二、wireshark示例
RFC3168指定在TCP数据报文中支持ECN,但是在TCP控制报文(TCP SYN, TCP SYN/ACK, pure ACKs, Window probes)和重传报文中不支持ECN,对于RST和FIN报文,RFC3168并没有明确描述。预期后续将会进一步扩大ECN的使用范围,下面示例的描述是以Linux实现和RFC3168为基础的,使用的是Reno拥塞控制算法未考虑DCTCP这类特殊的拥塞控制算法。
1、ECN协商成功
设置tcp_ecn=1,使得主动连接和被动连接都会尝试使用ECN,建立连接并发送数据后,TCP交互如下面wireshark所示

其中No1报文的IP头如下所示,ECN列显示的内容就是就对应下面IP头中高亮的部分

No1报文的TCP头如下所示,其中CWR列和ECN-Echo列即对应下图TCP头红色框中的两个标志位。注意No1数据包的Info列中显示的ECN标志实际上是指TCP头中的ECN-Echo标志位,即ECE标志位。
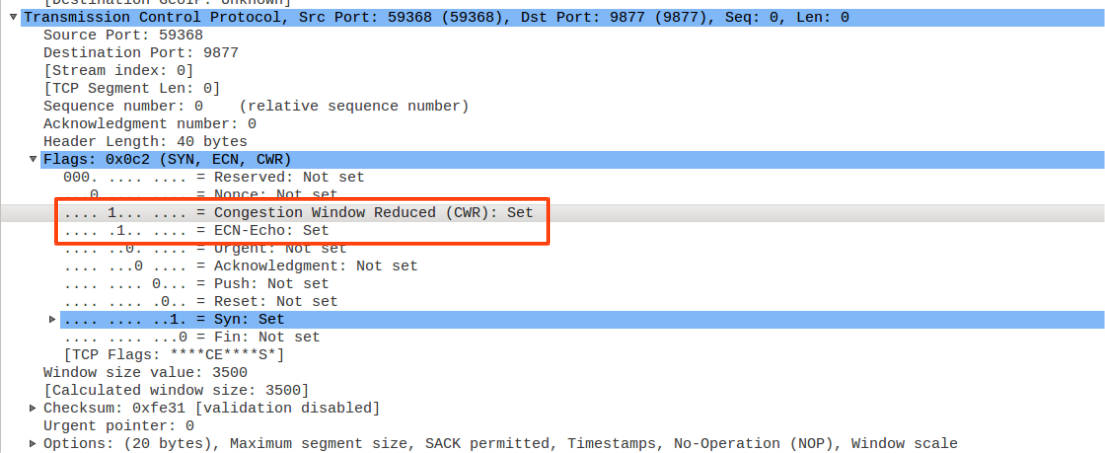
接着我们说一下ECN的协商过程,在No1这个SYN报文中,需要设置CWR和ECE标志位有效,这种类型的SYN报文协议称为ECN-setup SYN packet,其他类型的SYN报文称为non-ECN-setup SYN packet。在SYN-ACK报文中需要设置ECE标志为有效,并把CWR标志位设置为0,这种类似的SYN-ACK报文,协议称为ECN-setup SYN-ACK packet,其他类型的SYN-ACK报文称为non-ECN-setup SYN-ACK packet。ECN-setup SYN packet和ECN-setup SYN-ACK packet报文进行三次握手即表示ECN协商成功。协商成功后,随后的TCP数据报文才可以设置ECT。
同时注意上面TCP包系列中,在SYN报文、SYN-ACK报文、pure ACK报文中ECN列都是Not-ECT表示对应的数据包不支持ECN功能。而在No4和No6这两个实际传输了数据包的报文中ECN列都是ECT(0),表示传输层支持ECN功能,并且这个数据包可以使用ECN功能。
2、ECN协商失败
下面演示一下路由表设置使能ECN特性,并演示一下ECN协商失败的处理,同样在执行上面的示例前如下设置相关参数
#设置与127.0.0.1的主动连接和被动连接都尝试使用ECN功能root@Inspiron:/proc/sys/net/ipv4# ip route change local 127.0.0.1 dev lo feature ecn congctl reno#查询路由表中127.0.0.1和127.0.0.2的相关设置root@Inspiron:/proc/sys/net/ipv4# ip route show table local 127.0.0.1local127.0.0.1 dev lo scope host features ecn congctl renoroot@Inspiron:/proc/sys/net/ipv4# ip route show table local 127.0.0.2local127.0.0.2 dev lo scope host initcwnd 3 congctl reno#全局关闭ECN功能 但是由于路由表的设置与127.0.0.1协商ECN的时候还会尝试使能ECNroot@Inspiron:/proc/sys/net/ipv4# echo 0 > tcp_ecn

No1:虽然全局设置tcp_ecn=0关闭了ECN功能,但是路由表中设置了与127.0.0.1的连接都会尝试协商使能ECN,因此No1中设置了CWR和ECE标志位,是一个ECN-setup SYN packet报文。
No2:全局关闭了ECN功能,而且路由表中127.0.0.2的路由并没有设置使能ECN,因此SYN-ACK中并不会设置ECE,No2是一个non-ECN-setup SYN-ACK packet。
从No2可以看出这个TCP连接协商ECN失败,因此随后的No4和No6这两数据包报文都没有设置ECT(0),即没有使能ECN。
3、ECN下的拥塞控制处理
接下来我们把关注点移动到ECN下Linux的拥塞处理上,看一下Linux在ECN下的拥塞控制状态切换,相关状态变量的更新。首先把路由表设置成如下所示
root@Inspiron:/proc/sys/net/ipv4# ip route show table all 127.0.0.2local127.0.0.2 dev lo table local scope host ssthresh lock 50 initcwnd 3 features ecn congctl reno
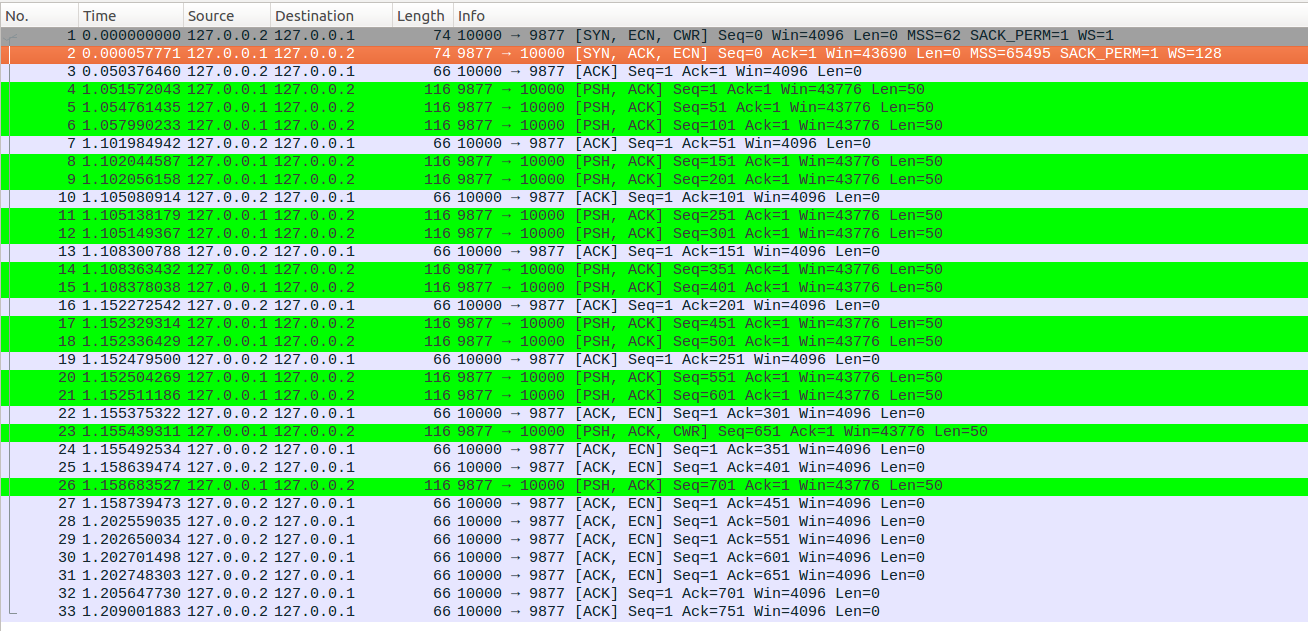
业务场景:server端与client建立连接后,休眠1000ms,然后以3ms为间隔连续write写入15个数据包,每个数据包的大小为50bytes,其中第六次写入的数据包即No11模拟在传输过程中被RED标记为CE,client对server端的每个数据包都会回复一个ACK确认包。最终如下图所示,其中IP头中ECN标志位为ECT(0)的数据包都被我标记为青绿色了。TCP头中的ECE和CWR标志可以从Info列查看
No1-No21:这个是连接建立和慢启动过程,从图中可以看到No1-No3协商了ECN功能。使能ECN后慢启动过程并无差异这里不再赘述。最终server端在发出No21报文后,ssthresh=50, cwnd=8, packets_out=8, sacked_out=0, lost_out=0, retrans_out=0,server端处于Open状态。
No22-No23:No22报文是No11报文的确认包,首先更新packets_out=7,注意这里No22这个ACK报文中ECE标志位有效(ECE标志位在wireshark的Info列显示为ECN标志位),server端在收到这个ECE有效的确认包后,拥塞状态从Open切换到CWR,并且初始化ssthresh=max(cwnd/2,2)=4,high_seq=651, prior_cwnd=8。接着使用PRR算法更新cwnd,更新prr_delivered=1,此时in_flight=7,delta=ssthresh-in_flight=-3<0,接着sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out = (4*1+7)/8-0=1,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(1,0)=1,因此最终更新cwnd = in_flight + sndcnt = 7+1=8。可以看到此时拥塞窗口允许发出一个新的数据包,CWR状态下没有数据包被标记为lost,因此不会尝试重传之前的数据包,最终发出No23这个新数据包,注意No23这个数据包响应了No22的ECE,设置了CWR标志位有效。发出No23后,ssthresh=4, cwnd=8, packets_out=8, sacked_out=0, lost_out=0, retrans_out=0,prr_delivered=1,prr_out=1,server端处于CWR状态。
No24-No26:这个过程与之前介绍过多次的Recovery状态下的cwnd更新过程类似,这里仅简单介绍一下。server端在收到No24后,计算sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out = (4*2+7)/8-1=0,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(0,0)=0,因此最终更新cwnd = in_flight + sndcnt = 7+0=7。此时拥塞窗口cwnd不允许发出数据包。server端在收到No25后,计算sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out = (4*3+7)/8-1=1,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(1,0)=1,因此最终更新cwnd = in_flight + sndcnt = 6+1=7。此时拥塞窗口允许发出一个数据包,即对应No26,No26中不再标记CWR标志位。发出No26后,ssthresh=4, cwnd=7, packets_out=7, sacked_out=0, lost_out=0, retrans_out=0,prr_delivered=3,prr_out=2,server端处于CWR状态。
No27-No31:cwnd更新过程与之前的Recovery状态处理类似,最终处理完No31后,ssthresh=4, cwnd=3, packets_out=2, sacked_out=0, lost_out=0, retrans_out=0,prr_delivered=8,prr_out=2,server端处于CWR状态。
No32:No32是client对No23的确认包,server首先更新packets_out=1,因为No23中CWR有效,client在收到No23这个报文后,再次回复ACK的时候就不会在设置ECE标志为了,可以从Info列看到从No32开始,client的ACK确认包不再有ECN标志(wireshark中Info列的ECN标志就是TCP头中的ECE标志)。No32的Ack=701>high_seq,server端TCP切换到Open状态,更新cwnd=ssthresh=4。接着进入reno的拥塞避免过程更新更cwnd_cnt=1。
No33:最终server端处理完No33后,ssthresh=4, cwnd=4, cwnd_cnt=2, packets_out=0, sacked_out=0, lost_out=0, retrans_out=0, server端处于Open状态。
4、CWR状态被Recovery状态打断
本示例路由表的设置与示例3一致
业务场景:本示例业务场景与示例3基本一致,但是有两个不同点,一个是server端在休眠1000ms后,以3ms为间隔连续write写入16个数据包,另外一个不同点是No14报文在传输过程中丢失,触发server端Recovery状态打断CWR状态,并进行快速重传。下面我们看一下Recovery状态打断CWR状态的处理。
No1-No24:这部分的处理与上面的示例类似,不再重复,处理完No24后,ssthresh=4, cwnd=7, packets_out=7, sacked_out=0, lost_out=0, retrans_out=0,prr_delivered=2,prr_out=1,server端处于CWR状态。
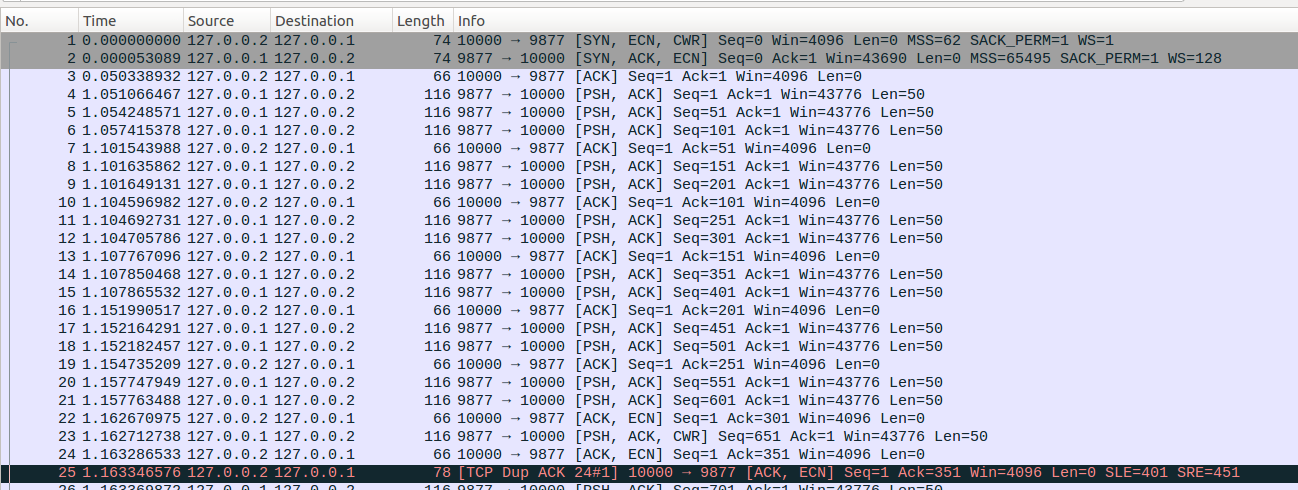
No25-No26:之前我们介绍各种快速重传场景收到dup ACK后,都是从Open切换到Disorder状态,但是如果TCP之前处于CWR状态,收到dup ACK的时候并不会切换到Disorder状态,而是继续停留在CWR状态。CWR状态下收到dup ACK时候,cwnd仍然按照PRR流程更新。因此收到No25后,先更新sacked_out=1。 接着进入cwnd更新流程,更新prr_delivered=3,计算sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out = (4*3+7)/8-1=1,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(1,0)=1,因此最终更新cwnd = in_flight + sndcnt = 6+1=7。此时拥塞窗口允许发出一个数据包,即对应No26,No26中不再标记CWR标志位。发出No26后,ssthresh=4, cwnd=7, packets_out=8, sacked_out=1, lost_out=0, retrans_out=0,prr_delivered=3,prr_out=2,server端处于CWR状态。
No27-No29:No27和No28这两个数据包依然按照PRR算法更新。注意server端在收到No28数据包的时候,sacked_out=3,已经被SACK确认的数据包到达门限dupthresh,因此server端会从CWR状态切换为Recovery状态,更新high_seq=751,把No14报文标记为lost状态,并更新lost_out=1,设置fast_rexmit=1,这样PRR更新cwnd的时候就可以确保拥塞窗口至少允许发出一个重传报文。注意从CWR状态切换为Recovery状态的时候并不会重新削减ssthresh。server收到No28报文时候,更新prr_delivered=5,计算delta=ssthresh-in_flight=0。 sndcnt = min(delta, max(prr_delivered - prr_out,newly_acked_sacked) + 1)=min(0,max(5-3,1)+1)=0,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(0,1)=1,因此最终更新cwnd = in_flight + sndcnt = 4+1=5。接着进行快速重传,即No29报文,更新retrans_out=1,prr_out=3。
No30-No36:这个过程与SACK打开场景下的快速恢复类似,最终server在处理完No36后,ssthresh=4, cwnd=6,cwnd_cnt=1, packets_out=0, sacked_out=0, lost_out=0, retrans_out=0,prr_delivered=9,prr_out=4,server端处于Open状态。

5、ECN下ssthresh削减后下一个发送的新数据包需要设置CWR标志位
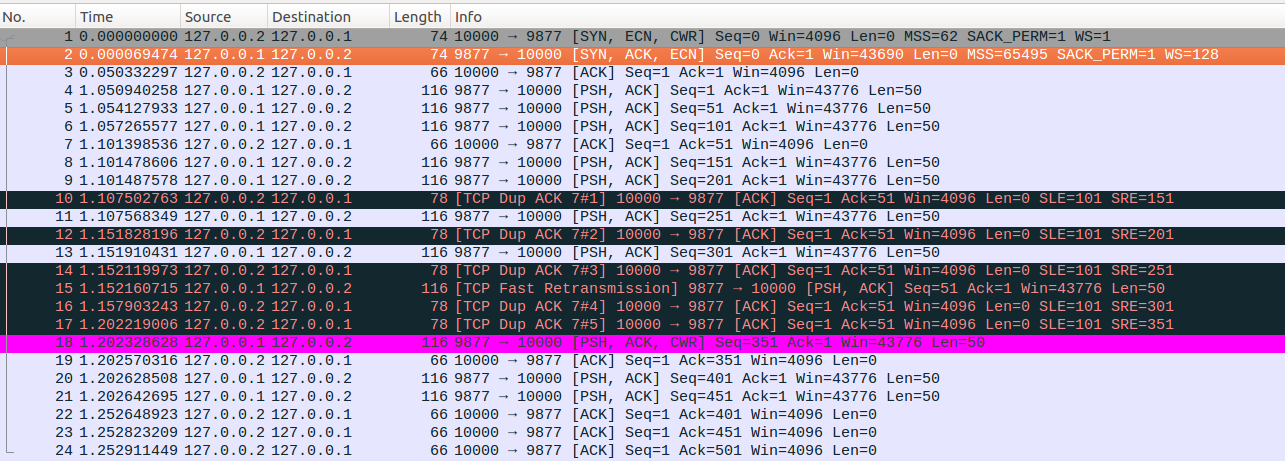
最后我们再来看一下ECN协商使能情况下,dup ACK触发快速重传,Open->Disorder->Recovery状态切换场景下,快速重传后发送的第一个新数据包中CWR标志为使能,如下图红色高亮的No18数据包所示。那么为什么上一个示例中快速重传后的No32这个新数据包没有设置CWR标记位呢?原因是上一个示例是从CWR状态切换到Recovery状态的,在切换到Recovery状态时,并没有削减ssthresh,因此快速重传后的第一个新数据包并不会标记CWR标志位。本示例是一个简单的SACK下快速重传/快速恢复的过程,不再逐包解释相关状态变量的更新变化情况,感兴趣的请参考前文。
补充说明:
1、允许ECN在SYNs, Pure ACKs, Window probes, FINs, RSTs and retransmissions中使用https://datatracker.ietf.org/doc/draft-bagnulo-tcpm-generalized-ecn/
2、RECN https://datatracker.ietf.org/doc/rfc7514/?include_text=1
3、ECN规范文档 https://datatracker.ietf.org/doc/rfc3168/?include_text=1
4、AQM机制 https://datatracker.ietf.org/doc/rfc7567/?include_text=1
5、RED相关状态变量和操作规则可以参考http://www.mathcs.emory.edu/~cheung/Courses/558-old/Syllabus/90-NS/RED.html
6、windows设置 netsh int tcp set global ecncapability=enabled 未验证
7、MAC设置 net.inet.tcp.ecn_initiate_out和net.inet.tcp.ecn_negotiate_in 未验证
8、DCTCP http://simula.stanford.edu/~alizade/Site/DCTCP.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号