TCP系列50—拥塞控制—13、Eifel探测下的拥塞撤销
一、概述
我们之前在SACK关闭场景下的拥塞撤销那篇文章中提到过Eifel探测算法(Eifel Detection Algorithm),最早在介绍DSACK和FRTO的时候我们就有提到过Eifel探测算法。Eifel探测算法是基于TSopt选项中TSV的单调非减特性设计的。简单介绍一下Linux中Eifel探测算法的实现,Linux会在TCP进行第一次重传的时候把重传数据包的TSV记录在状态变量retrans_stamp中,当收到partial ACK的时候,或者收到的Ack报文的ack number>=high_seq的时候,如果这个报文的TSER<retrans_stamp,说明这个ACK报文是对应TCP初传(称呼为original transmit)的确认包。
从上面的原理介绍可以看到Eifel探测可以用于虚假超时重传和虚假快速重传,而且即使发生ACK丢包,Eifel探测算法仍然可以使用随后ACK报文的TSER进行探测。本文重点介绍一下虚假快速重传后partial ACK触发的拥塞撤销。
Recovery状态下TCP收到partial ACK的时候,如果当前拥塞状态没有撤销(undo_marker标记非0),并且Eifel探测检测到虚假重传,那么TCP按照如下步骤处理(注意这是一个根据实现代码简化的步骤):
更新dupthresh门限,假设partial ACK的ack number新确认了acknum个数据包,那么如果当前使能了FACK功能,那么更新dupthresh=max(dupthresh,fackets_out+acknum),否则更新dupthresh=max(dupthresh,sacked_out+acknum)。
如果retrans_out>0,正常按照Recovery状态下cwnd的更新方式来更新cwnd,然后跳到第5步。
把标记为lost的数据包取消lost标记,更新cwnd=max(cwnd,2*ssthresh), ssthresh=max(ssthresh,prior_ssthresh),设置undo_marker=0,防止后面重复拥塞撤销
如果sacked_out>0,则切换到Disorder状态,否则切换到Open状态
尝试发送新的TCP数据包,而不进行快速重传尝试
二、wireshark示例
1、Recovery状态下partial ACK触发的拥塞撤销
如下设置拥塞控制算法和initcwnd。
******@Inspiron:~$ sudo ip route add local 127.0.0.2 dev lo congctl reno initcwnd 10 #参考本系列destination metric文章******@Inspiron:~$ sudo ethtool -K lo tso off gso off #关闭tso gso以方便观察cwnd变化
业务模型:server端和client建立连接后,首先休眠1002ms,然后以5ms为间隔连续写入17个数据包,每个数据包的大小为50bytes,其中数据包传输发生了乱序,对于No7-No14这几个数据包,client收包顺序为No9、No10、No11、No12、No7、No14、No8、No13,其余数据包则顺序到达client端,client端对每个收到的数据包都会回复一个ACK确认包。最终业务情况如下面的wireshark图示,No7、No8、No13、No14这几个乱序包高亮标出来了。注意下面拥塞控制状态的变化为:Open->Disorder->Recovery->Disorder->Open
No1-No18:这种类似的初始化慢启动前面已经介绍过多次,这里不再进行介绍,最终server端发出No18数据包后,ssthresh=0x7fffffff(我们在上面的路由表中并没有设置ssthresh的参数,这个是个默认初始值),cwnd=11,packets_out=11,sacked_out=0, lost_out=0, retrans_out=0, fackets_out=0, prr_delivered=0, prr_out=0,server端TCP处于Open状态。
No19-No25:No19、No21、No23、No24这四个确认包分别对应No9、No10、No11、No12,这种FACK快速重传也介绍过多次了,这里不再废话,最终server发出No25后,prior_ssthresh=0x7fffffff,prior_cwnd=11,ssthresh=5,cwnd=8,packets_out=12,sacked_out=4, lost_out=2, retrans_out=2, fackets_out=6, prr_delivered=3, prr_out=2,high_seq=651,retrans_stamp=2409052(No22的TSVal),undo_marker标记有效(即值非零),server端TCP处于Recovery状态。
No26:No26是对应乱序后的No7数据包的,是一个partial ACK,server端的TCP收到这个partial ACK的时候,首先更新packets_out=11, fackets_out=5,lost_out=1,retrans_out=1,接着按照我们上面介绍的流程处理,首先undo_marker非零,表示当前还没有进行过拥塞撤销,接着No26中的TSecr=2409036<retrans_stamp=2409052,因此Eifel探测算法判断这个partial ACK是对应初传数据包的,之前的快速重传为虚假快速重传,接着按照上面介绍的处理流程更新dupthresh=fackets_out+acknum=6,此时retrans_out>0,因此按照之前文章介绍的Recovery状态cwnd更新流程来更新拥塞窗口。prr_delivered=4,in_flight=11-(4+1)+1=7,delta=5-7<0,sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out=(5*4+10)/11-2=0, sndcnt=max(0,0)=0,因此cwnd=in_flight+sndcnt=7。随后server端尝试发送新数据包,但是受限于cwnd未能发出。注意在Eifel探测到虚假重传后server端不再尝试重传TCP数据。
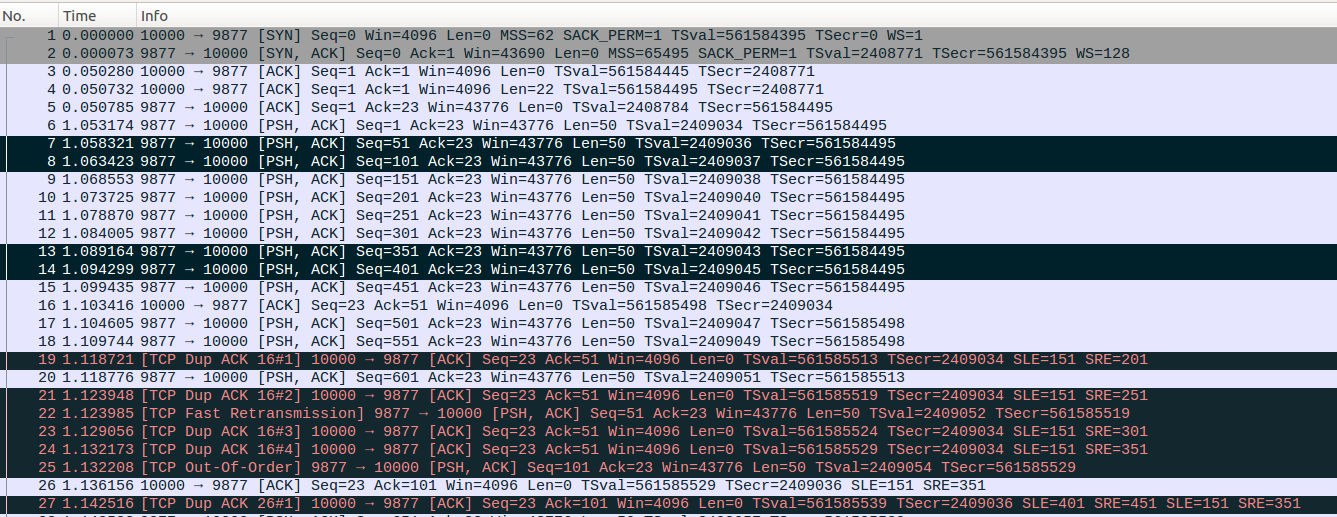
No27-No28:No27对应乱序的No14数据包,通过SACK确认了No14数据包,因此更新sacked_out=5,fackets_out=7,No27的ack number并没有发生变化,因此并不是partial ACK,因此会按照Recovery状态下普通的dup ACK处理流程来处理。server端接着进入Recovery状态下的cwnd更新流程,prr_delivered=5,in_flight=11-(5+1)+1=6,delta=-1<0,sndcnt = (5*5+10)/11-2=1, sndcnt=max(1,0)=1,因此cwnd=in_flight+sndcnt=7。拥塞窗口允许发出一个TCP数据包,此时尝试快速重传没有对应的需要重传的数据包,接着发出新数据包No28,更新packets_out=12,prr_out=3。
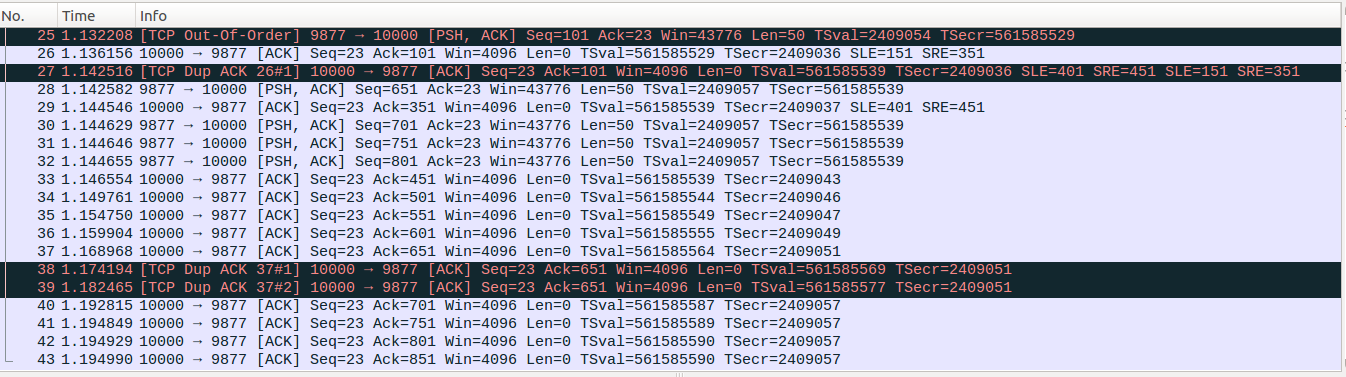
No29-No32:No29仍然是一个partial ACK,ack number新确认了5个数据包,server端收到这个partial ACK后,更新packets_out=7,sacked_out=1, lost_out=0, retrans_out=0, fackets_out=2,接着进入partial ACK的处理流程,No29的TSecr=2409037<retrans_stamp=2409052,因此Eifel探测认为之前快速重传为虚假重传,而且此时undo_marker非零,因此进入上面介绍的处理流程,首先dupthresh=6不变,此时retrans_out=0,因此把标记为lost的数据包取消lost标记,更新cwnd=max(cwnd,2*ssthresh)=10, ssthresh=max(ssthresh,prior_ssthresh)=0x7fffffff,设置undo_marker=0,防止后面重复拥塞撤销。此时sacked_out>0,因此server端TCP从Recovery状态切换到DIsorder状态。接着进入reno的慢启动过程,No29的ack number新确认了5个数据包,因此更新cwnd=cwnd+5=15,更新。最后发出新数据包No30、No31、No32,此时server端TCP中已经没有待发送的数据了。发出No32后,ssthresh=0x7fffffff,cwnd=15,packets_out=10,sacked_out=1, lost_out=0, retrans_out=0, fackets_out=2。
No33-No37:client端的ack确认包,server端在收到No37后,ssthresh=0x7fffffff,cwnd=21,packets_out=4,sacked_out=1, lost_out=0, retrans_out=0, fackets_out=0。
No38-No39:注意这两个数据包是对应虚假快速重传No22和No25的,server端在收到No38这个dup ACK后并不会进入Disorder状态,原因是当前SACK处于打开状态,进入Disorder的条件是有SACK信息,这里还有两个点需要注意,首先注意这里反馈的确认包的ack number与之前的high_seq相同,如果是SACK关闭的场景,这里如果有dupthresh次以上的dup ACK就会再次触发虚假快速重传,这里要和我们之前文章介绍的SACK关闭场景下false fast retransmit的避免算法进行对比。另外一点就是在SACK打开的场景下,收到这样的dup ACK并不会触发快速重传,后面我们介绍TLP的时候会演示这种场景,这也就是之前的false fast retransmit的避免算法只需要处理SACK关闭场景的原因。
No40-No42:最终server发出No43后,ssthresh=0x7fffffff,cwnd=24,packets_out=1,sacked_out=0, lost_out=0, retrans_out=0, fackets_out=0。
No43:server在收到这个ACK后,发现当前处于application-limited传输状态(参考前面CWV的介绍文章),因此并不会更新cwnd,最终 ssthresh=0x7fffffff, cwnd=24, packets_out=0, sacked_out=0, lost_out=0, retrans_out=0, fackets_out=0。
最后同样给出本示例的系列号时序图

2、SACK关闭场景下的Eifel探测与拥塞撤销
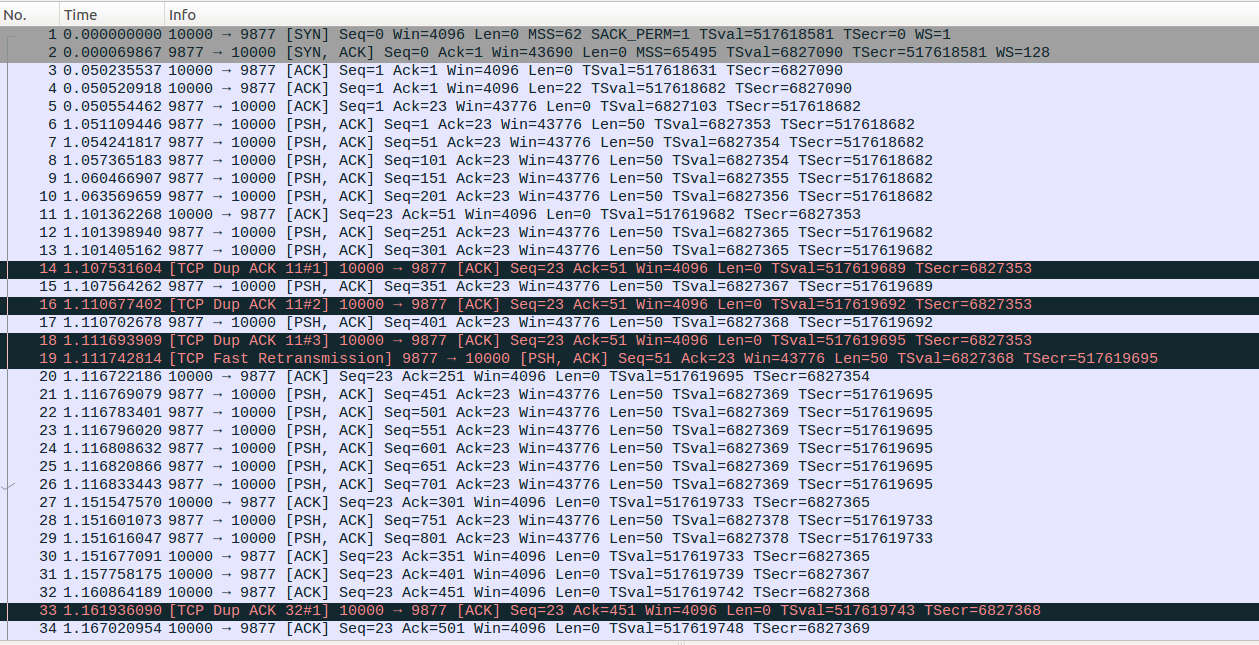
还记得我们之前在演示SACK关闭场景下的拥塞撤销示例的时候设置tcp_timestamps=0关闭了TSopt选项吧。原因是如果不关闭的话收到partial ACK的时候Eifel探测算法就会进行拥塞撤销操作。下面给出一个SACK关闭场景下Eifel探测的示例,下面示例中tcp_sack=0,initcwnd=5,congctl=reno,关闭GSO、TSO功能,其中No7发生乱序传输,client先收到No8、No9、No10然后在收到的No7。整体处理比较简单不再进行逐包解释了。

补充说明:
1、partial ACK下拥塞撤销的详细流程请参考tcp_try_undo_partial。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号