TCP系列47—拥塞控制—10、FACK下的快速恢复与PRR
一、概述
FACK下的重传我们在之前的重传部分已经进行了介绍,这里简单介绍一下随着FACK提出的拥塞控制算法的改进及随后的进一步改进。
从我们之前介绍的RFC2582和RFC5681中可以看到,快速恢复下当探测到丢包的时候,会设置ssthresh = max (FlightSize / 2, 2*MSS)、 cwnd=ssthresh+3*MSS,随后发送端收到dup ACK的时候进行cwnd的inflate过程,发送端需要收到大约一半的dup ACK后,才能允许发送新数据,这意味着发送端需要等待大约RTT/2的时间后才能发送新数据,然后随后的RTT/2时间内每收到一个dup ACK就发送一个新数据包。为了避免初始的RTT/2等待并把发送过程平稳化,Mathis等人在1996年Mathis提出FACK的同时提出了overdamping和rampdown,随后作者把这两个算法统一并改进为rate halving,然后作者又给rate halving加了一些门限参数,提出了一个RHBP(Rate-Halving with Bounding Parameters)算法。RHBP的基本思路就是在快速恢复阶段的第一个RTT内发送端每收到两个dup ACK就允许发出一个数据包,从而避免了初始的RTT/2等待并使得发包过程更为平稳。可以看到RHBP假设了一个50%的窗口削减,但是有些最新的拥塞控制算法对于拥塞窗口的削减可能小于50%,因而rate halving会过度削减窗口,针对其存在的类似问题,Mathis又提出了PRR(Proportional Rate Reduction)算法。这个算法在RFC6937中定义,在快速恢复下prr_delivered和prr_out这两个状态变量就是PRR状态变量,RFC6937中定义的PRR算法就是对应我们之前介绍的SACK关闭时候快速恢复下cwnd的更新过程。因此PRR算法下cwnd的具体更新流程请参考前文。
二、wireshark示例
在执行本示例前如下设置initcwnd、ssthresh和reno拥塞控制算法。同时设置tcp_recovery=0关闭RACK重传,RACK下的快速恢复除了对lost数据包的标记外其余并无太大并无差异。之前文章我们提到过linux中使用fackets_out状态变量保存FACK信息,这个变量表示当前通过SACK块确认的最靠前的数据包的个数。通过下面示例来进一步理解这个状态变量吧。
******@Inspiron:~$ sudo ip route add local 127.0.0.2 dev lo congctl reno initcwnd 12 ssthresh lock 30 #参考本系列destination metric文章******@Inspiron:~$ sudo ethtool -K lo tso off gso off #关闭tso gso以方便观察cwnd变化
1、FACK下的快速恢复
在介绍本示例前如果读者不熟悉linux的TCP代码,那一定要先看前面的文章。
业务场景:server端与client建立连接后休眠1000ms,接着连续发出12个数据包,每个数据包的大小为50bytes,发送间隔为3ms,在第12数据包write写入后,立即进行一次write操作写入(15*50)bytes。server端的发送缓存设置足够大,因此write操作不会因为发送缓存不足而休眠。server发出的数据包中有5个数据包在传输过程中丢失,如下图所示,我高亮标示出来的No8、No9、No10、No11、No19这五个数据包传输丢失。client对收到的每个数据包都会进行ACK回复确认。
No1-No23:这些数据包的处理与前面SACK下的快速恢复示例1的处理相同,因此不再重复介绍。发出No23后,packets_out=14,sacked_out=0, lost_out=0, retrans_out=0,fackets_out=0,prr_delivered=0, prr_out=0,ssthresh=30, cwnd=14,server端TCP处于Open状态。
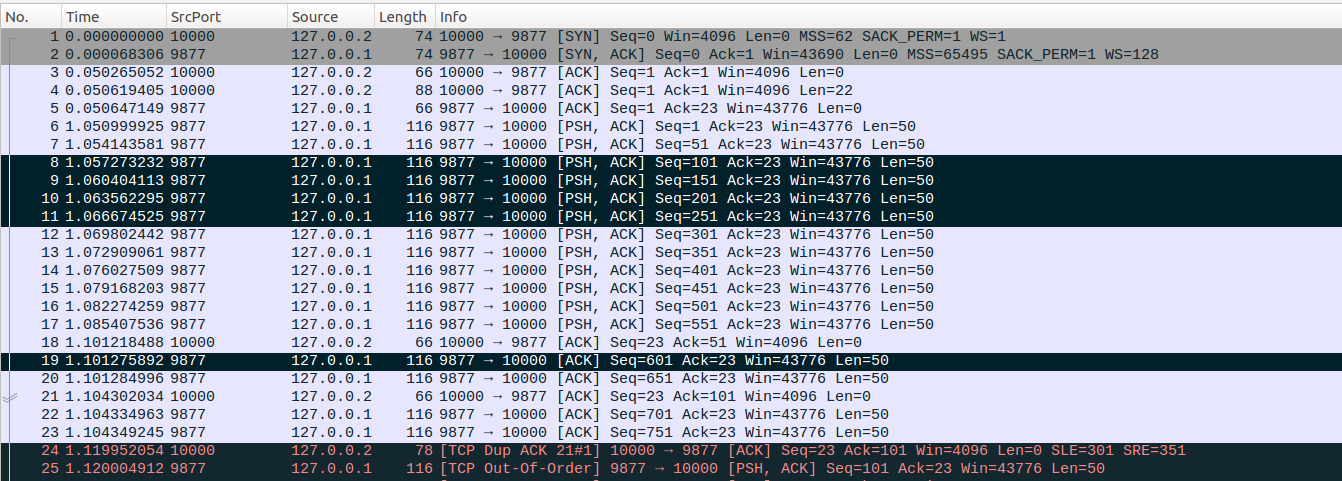
No24-No25:No8、No9、No10、No11这四个数据包丢失,client收到乱序的No12后回复No24确认包,No24通过SACK确认了No12数据包。client按序接收的数据包到No7为止,乱序接收了No12,因此更新fackets_out=12-7=5,表示server端当前接收到的最靠前的数据包No12与No7之间差了5个数据包(包括No12本身)。同样会更新sacked_out=1。此时dupthresh=3,在打开FACK的情况下,server端会判断如果fackets_out>dupthresh,就表示需要进行快速重传(请参考前面FACK重传的介绍文章),因此server端从Open状态直接切换到Recovery状态,注意这个切换中间是不经过Disorder状态的,进入Recovery状态的时候更新prior_ssthresh=max(ssthresh,3/4*cwnd)=30, ssthresh=max(cwnd/2,2)=7, prior_cwnd=cwnd=14, prr_delivered=0, prr_out=0,high_seq=801。因为fackets_out-dupthresh=2,因此server端TCP会把系列号范围(101,151)、(151,201)这两个数据包标记为lost,更新lost_out=2。接着进入Recovery状态下更新cwnd的流程,更新prr_delivered=1,此时in_flight= packets_out - ( sacked_out + lost_out) + retrans_out = 14-(1+2)+0=11,delta=sshresh-in_flight=7-11=-4<0,因此sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out =(7*1+14-1)/14-0=1, sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0)) = max(1, 1)=1,因而更新cwnd = in_flight + sndcnt = 12。接着server端进入快速重传流程,此时虽然有两个数据包被标记为lost但是因为cwnd的限制只能重传一个数据包,即No25,然后更新retrans_out=1, prr_out=1。随后server端尝试发送新的数据包同样由于cwnd限制未能发出。
No26:server端收到No26后,No26通过SACK块新确认了一个数据包,因此更新sacked_out=2,而No26通过SACK确认的最靠前的数据包为(351,401),与系列号Ack=101相差6个数据包,因此更新fackets_out=6,fackets_out-dupthresh=3,因此从Ack=101开始的三个数据包可以标记为lost,(101,151)和(151,201)这两个数据包在之前已经标记为lost了,因此本次只是额外标记(201,251)为lost,更新lost_out=3。接着进入cwnd的更新,prr_delivered=2,in_flight=14-(2+3)+1=10,delta=-3,sndcnt=(7*2+14-1)/14-1=0,sndcnt=max(0,0)=0,因此cwnd=10。拥塞控制不允许发出新的数据包,故而接下来的快速重传和新数据发送尝试都没有发出数据包。
No27-No28:server端收到No27后更新sacked_out=3, fackets_out=7,lost_out=4,prr_delivered=3,in_flight=14-(3+4)+1=8,delta=-1,sndcnt=(7*3+14-1)/14-1=1,sndcnt=max(1,0)=1,因此cwnd=9。此时拥塞控制允许发出一个数据包,因此随后的快速重传流程发出了No28数据包,并更新prr_out=2,retrans_out=2。
No29:server端收到No29后更新sacked_out=4, fackets_out=8, 此时fackets_out-dupthresh=5,也就意味着从Ack=101开始的5个数据包应该被标记为lost,但是第5个数据包的系列号为(301,351),这个数据包已经被SACK确认了,因此不会被标记为lost状态,lost_out因而不会更新。接着进入更新cwnd的流程,prr_delivered=4,in_flight=14-(4+4)+2=8,delta=-1<0,sndcnt=(7*4+14-1)/14-2=0,sndcnt=max(0,0)=0,因此cwnd=8,此时拥塞控制不允许发出数据包。
No30:server收到No30后,sacked_out=5,fackets_out=9,lost_out=4保持不变原因同上,prr_delivered=5,in_flight=14-(5+4)+2=7, delta=0, 此时delta不再小于0,因此sndcnt的更新流程也发生了变化,sndcnt = min(delta, newly_acked_sacked)=min(0,1)=0, sndcnt=max(0,0)=0,因此cwnd=7,此时同样不允许发出新的数据包。
No31-No32:server端收到No31后,sacked_out=6,fackets_out=10,lost_out=4,prr_delivered=6,in_flight=14-(6+4)+2=6, delta=1, sndcnt=min(1,1)=1, sndcnt=max(1,0)=1,因此cwnd=7,此时拥塞窗口允许发出一个数据包,接着server端快速重传No32数据包并更新prr_out=3,retrans_out=3。
No33-No34:这组数据包的处理与No31-No32类似,server收到No33后,sacked_out=7,注意No33这个ACK确认包的SACK块相比No31新确认数据包(651,701),701这个系列号相比No31的601系列号向前滑动了两个数据包的大小,因而更新fackets_out=fackets_out+2=12, lost_out=4, prr_delivered=7, in_flight=14-(7+4)+3=6, delta=1, sndcnt=min(1,1)=1, sndcnt=max(1,0)=1,因此cwnd=7,此时拥塞窗口允许发出一个数据包,接着server端快速重传No34数据包并更新prr_out=4,retrans_out=4。
No35-No36:server收到No35后,sacked_out=8,fackets_out=13,lost_out=4,prr_delivered=8,in_flight=14-(8+4)+4=6, delta=1, sndcnt=min(1,1)=1, sndcnt=max(1,0)=1,因此cwnd=7,此时拥塞窗口允许发出一个数据包,此时server端被标记为lost的数据包已全部重传了,没有额外的数据包等待重传,因此server端发出新数据,对应No36,发出No36后packets_out=15,prr_out=5。
No37-No38:No37的SACK新确认了一个数据包,更新sacked_out=9,fackets_out=14,此时fackets_out-dupthresh=11,而从Ack=101开始的第11个数据包为(601,651),这个数据包是没有被SACK确认的,因此TCP会把这个数据包标记为lost,进而更新lost_out=5。接着进行cwnd的更新操作,prr_delivered=9, in_flight=15-(9+5)+4=5, delta=2, sndcnt=min(2,1)=1, sndcnt=max(1,0)=1,因此cwnd=6,可以看到此时cwnd在Recovery状态下又降低到了ssthresh下面。此时cwnd允许发出一个数据包,因此发出No38重传包,更新retrans_out=5,prr_out=6。

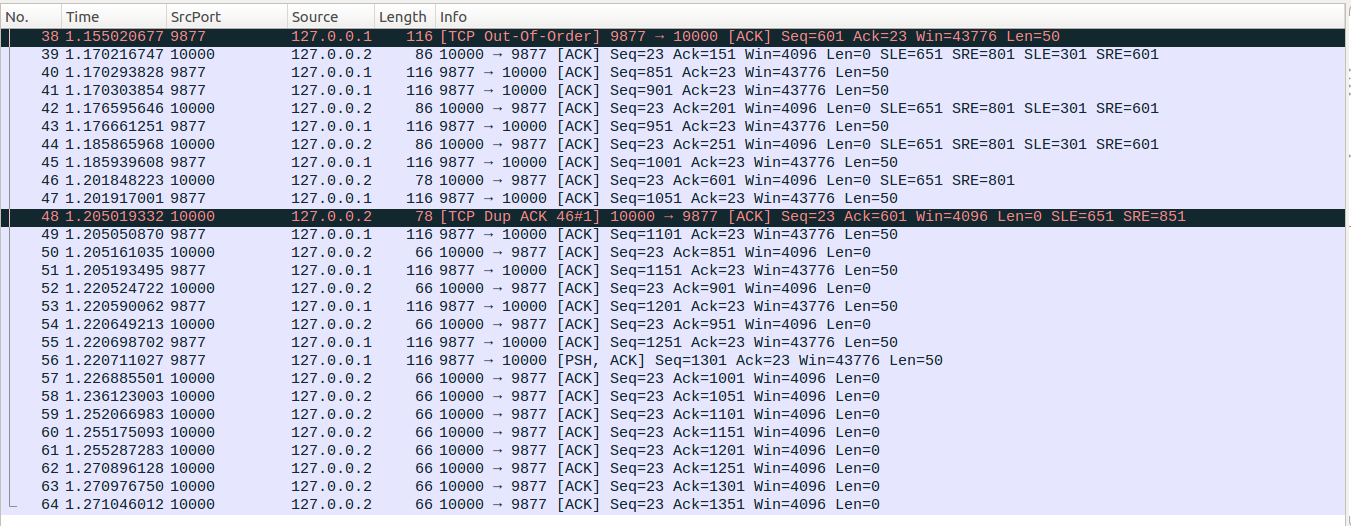
No39-No41:client收到No25重传包后,回复No39确认包,No39的SACK信息没有发生变化,但是ack number新确认了一个之前标记为lost的数据包,server收到No39后更新packets_out=14,fackets_out=13,lost_out=4,retrans_out=4,因为SACK块信息没有发生变化,因此sacked_out不变,此时in_flight=14-(9+4)+4=5,prr_delivered=10, delta=2>0,因为这个No39这个ACK报文确认了新数据,而且没有被RACK做标记,因此sndcnt = min(delta, max(prr_delivered - prr_out,newly_acked_sacked) + 1)=min(2,max(10-6,1)+1)=2,sndcnt=max(2,0)=2,cwnd=7,注意到了吧在Recovery状态下,cwnd也可能会向上调整的,此时拥塞窗口允许发出两个新的数据包,即对应No40和No41,并更新packets_out=16,prr_out=8。
No42-No43:server端收到No42后,更新packets_out=15,fackets_out=12,lost_out=3,retrans_out=3,sacked_out不变仍为9。此时in_flight=15-(9+3)+3=6,prr_delivered=11,delta=1>0,sndcnt=min(1,max(11-8,1)+1)=1,snd=max(1,0)=1,cwnd=6+1=7。此时拥塞控制允许TCP发出一个数据包,即对应No43,然后更新packets_out=16,prr_out=9。
No44-No45:这组数据包的处理与No42-No43相同,发出No45后,packets_out=16, fackets_out=11,lost_out=2,retrans_out=2, sacked_out=9, prr_delivered=12,cwnd=7,prr_out=10。
No46-No47:client收到No34这个重传包后,之前由No8、No9、No10、No11四个数据包丢包形成hole得以填上,可以看到No46的因此少了一个(301,601)的SACK块,这个SACK块中共包含6个数据包,因此更新sacked_out=3。No46的Ack=601,相比No44新确认了7个数据包,因此更新packets_out=9, fackets_out=4,这7个数据包(251,301)是之前被标记为lost的数据包并进行了重传,因此更新lost_out=1,retrans_out=1。此时in_flight=9-(3+1)+1=6, prr_delivered=13, delta=1>0, sndcnt=min(1,max(13-10,1)+1)=1,cwnd=7,此时拥塞控制允许发出一个数据包即No47,然后更新packets_out=10,prr_out=11。
No48-No49:No48这个dup ACK对应No36数据包,server收到No48后,更新sacked_out=4,fackets_out=5,in_flight=10-(4+1)+1=6, prr_delivered=14, delta=1>0, sndcnt=min(1,max(14-11,1)+1)=1,cwnd=7,此时拥塞控制允许发出一个数据包即No49,然后更新packets_out=11,prr_out=12。
No50-No51:client端收到No38的重传后,最后一个由No19形成的hole也被填充上了,因此No50中不在带有SACK信息,更新sacked_out=0, fackets_out=0,No50的Ack=851新确认了5个数据包,更新packets_out=6,其中4个是之前被SACK确认的,1个是被标记为lost并进行了重传的,因此更新lost_out=0, retrans_out=0,注意No50的Ack=851>high_seq=801,因此此时server端的TCP进入Open状态,更新cwnd=ssthresh=7,即此时TCP处于reno的拥塞避免过程中,更新cwnd_cnt=5,此时in_flight=6,因此拥塞控制允许TCP发出一个数据包即No51,发出后更新packets_out=7。
No52-No53:server端收到No52后更新packets_out=6,cwnd_cnt=6,cwnd=7,TCP发出No53数据包后更新packets_out=7。
No54-No56:server收到No54后更新packets_out=6,cwnd_cnt=7,此时cwnd_cnt/cwnd=1,因此更新cwnd=8,cwnd_cnt=0。此时拥塞控制允许TCP发出两个数据包No55和No56,并更新packets_out=8。此时server端write写入的数据都已经发出去了。
No57-No64:server端依次收到client端的ACK确认包,最终发出No64后packets_out=0, fackets_out=0,lost_out=0,retrans_out=0, sacked_out=0, cwnd=9(server端收到No59后reno的拥塞避免又更新cwnd=cwnd+1=9),ssthresh=7,cwnd_cnt=0。
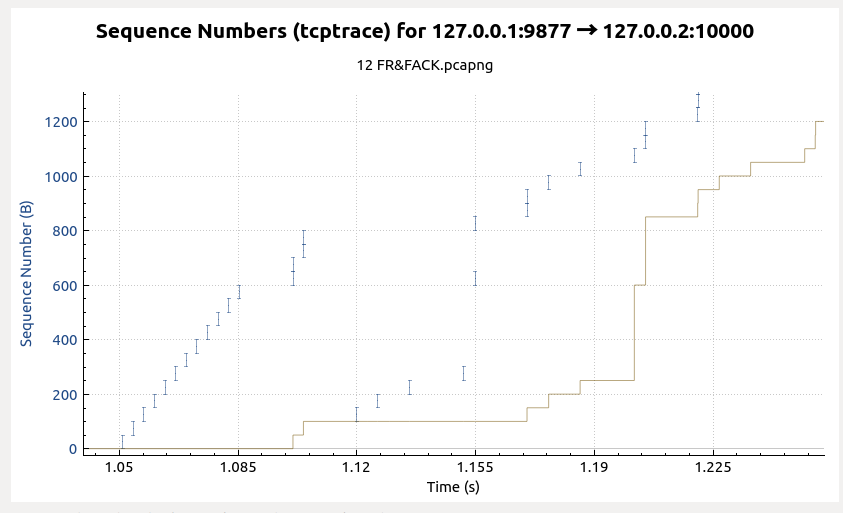
最后依然给出系列号的时序图,不过因为这个图中不能显示处SACK的信息,所以看起来不像SACK关闭场景下那么直观了
补充说明:
1、https://tools.ietf.org/html/draft-mathis-tcp-ratehalving-00
2、https://tools.ietf.org/html/rfc6937
3、http://conferences.sigcomm.org/sigcomm/1996/papers/mathis.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号