TCP系列42—拥塞控制—5、Linux中的慢启动和拥塞避免(二)
在本篇中我们继续上一篇文章wireshark的示例讲解,上一篇介绍了一个综合示例后,本篇介绍一些简单的示例,在读本篇前建议先把上一篇读完,为了节省篇幅,本篇只针对一些特殊的场景点报文进行讲解,不会像上一篇一样对每个报文都进行讲解并随报文更新相关状态变量的值了。
一、wireshark示例
本篇示例的TCP测试仍然设置初始拥塞窗口为3,并关闭TSO、GSO等功能。同时设置wireshark使其不在info列显示TSopt的信息。
******@Inspiron:~$ sudo ip route add local 127.0.0.2 dev lo congctl reno initcwnd 3 #请参考本系列destination metric文章******@Inspiron:~$ ip route show table all | grep 127.0.0.2local 127.0.0.2 dev lo table local scope host initcwnd 3 congctl reno******@Inspiron:~$ sudo ethtool -K lo tso off gso off #关闭tso gso以方便观察cwnd变化
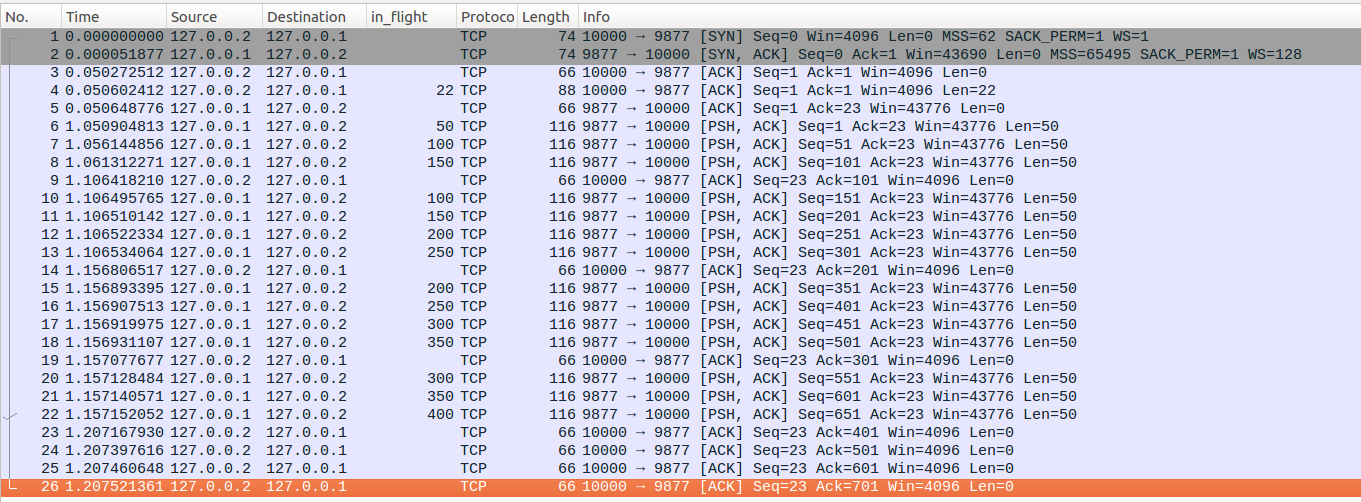
client与server端建立连接后,先发送一个请求报文No4,server端则立即回复ACK确认包。server端在与client建立连接后休眠1000ms,然后每隔5ms发送50bytes的数据包,总共发送14次。client端则每收到两个报文的时候回复一个ACK确认包。最终TCP流如下图所示,图中in_flight列是wireshark对于目前还在传输中的数据量的估计,在这种简单场景下wireshark的估计与linux是一致的,可以作为参考
No9-No13:No9报文回复了No6和No7两个报文,server端收到No9报文后,直接更新cwn=cwnd+2=5,此时in_flight=packets_out=1,因此可以额外发出四个新的数据包,即No10-No13。从wireshark中也可以看到发送完No13后in_flight为250,正好是5个数据包的大小。
No14-No18:与No9-No13类似不再重复分析
No19-No22:server端收到No19后,只有150bytes三个数据包等待发送,因此最终只发出了No20-No22三个数据包。
2、慢启动与ABC、stretched ACK、ACK Compression
ABC(Appropriate Byte Count):是指接收端对于接收到的一个TCP报文,分段反馈多个有效的ACK确认包,如果发送端收到每个ACK确认包后都会更新cwnd,那么在慢启动阶段可能会导致cwnd增长异常迅速,而且超过链路的承载能力,最终降低TCP的性能。这种手段也称呼为ABC攻击。
stretched ACK:我们之前介绍延迟ACK时候介绍过,当以SMSS发送报文的时候,协议规定延迟ACK不能超过两个full-sized报文。但是如果接收端收到的ACK确认包中ack number确认了三个或者以上的full-sized的报文的时候,这个ACK就叫做stretched ACK。stretached ACK原因有多种,最常见的就是ACK报文丢失。
ACK compression:由于中间链路的缓存以及和其他TCP连接一起共享缓存等原因,可能会导致ACK报文成堆到达发送端。这种场景我们就称呼为ACK压缩。
对于ACK compression场景,reno拥塞控制就是逐个处理每个ACK报文,这样就会导致拥塞窗口突然增大,发送端突然发出大量的TCP报文,这种突然发出大量数据的行为我们称呼为burst,影响网络平稳。另外一方面ACK compression还会影响RTT估计,之前我们介绍过有些拥塞控制算法基于时延来来估计网络拥塞情况,因此 ACK compresion还会影响这类基于时延的拥塞控制算法的性能。
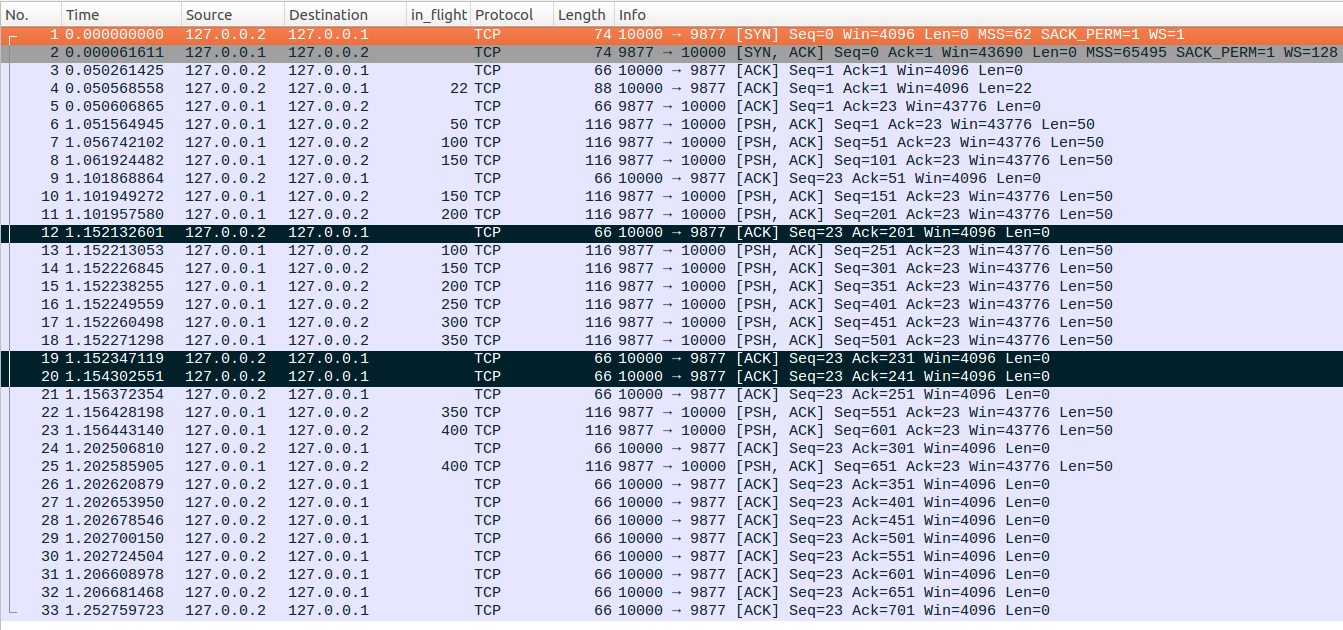
在这里我们仅演示一下linux慢启动对于ABC和stretched ACK的处理场景,拥塞避免阶段的处理与慢启动类似不在示例,如下图所示我高亮标出了一些ACK报文
No12:可以看到No12相对于No9报文Ack number一共反馈确认了三个数据包,这个就是我们说的stretched ACK。可以看到此处linux对于stretched ACK的处理上,直接更新了cwnd=cwnd+3,然后一共发出了No13-No18六个数据包。
No19-No21:可以看到No19相对于No12,ack number只反馈确认了30bytes的数据,并没有完整反馈No11这个数据包,No20同样也没有完整反馈No11这个数据包,linux在收到这两个ACK报文的时候,则会判断是否完整反馈了之前发出的No11数据包,当发现没有完整反馈No11数据包的时候并不会更新cwnd。直到linux收到No21这个数据包后,发现之前的No11这个数据包已经被完整反馈了,因此更新cwnd=cwnd+1,发出两个数据包。
3、多个数据包RTO超时
在之前的综合示例中我们看到过,一次RTO超时触发重传后,同一个报文的多次RTO超时并不会继续更新ssthresh,而随后的recovery point之前的慢启动重传也不会更新ssthresh。但是在recovery point之前的多个数据包触发的RTO超时则会重新更新ssthresh。一定要记得是不同TCP报文的RTO超时才会更新ssthresh,而linux只有一个RTO定时器。要分清慢启动重传和RTO超时重传的区别。
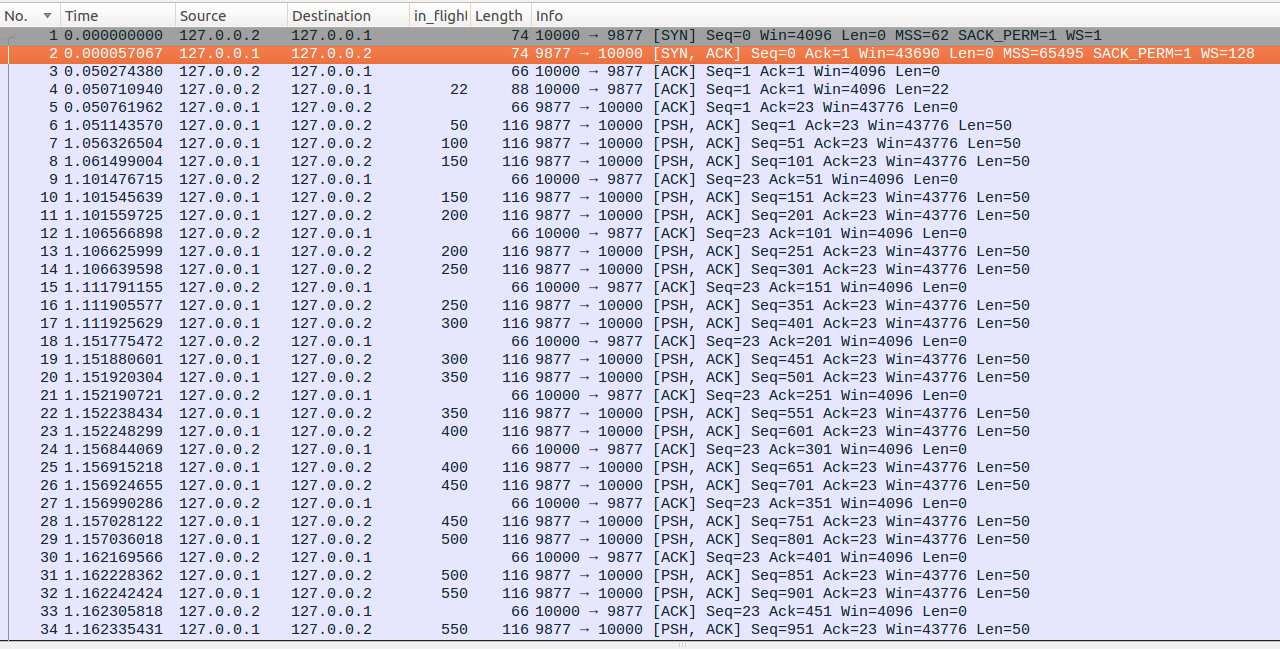
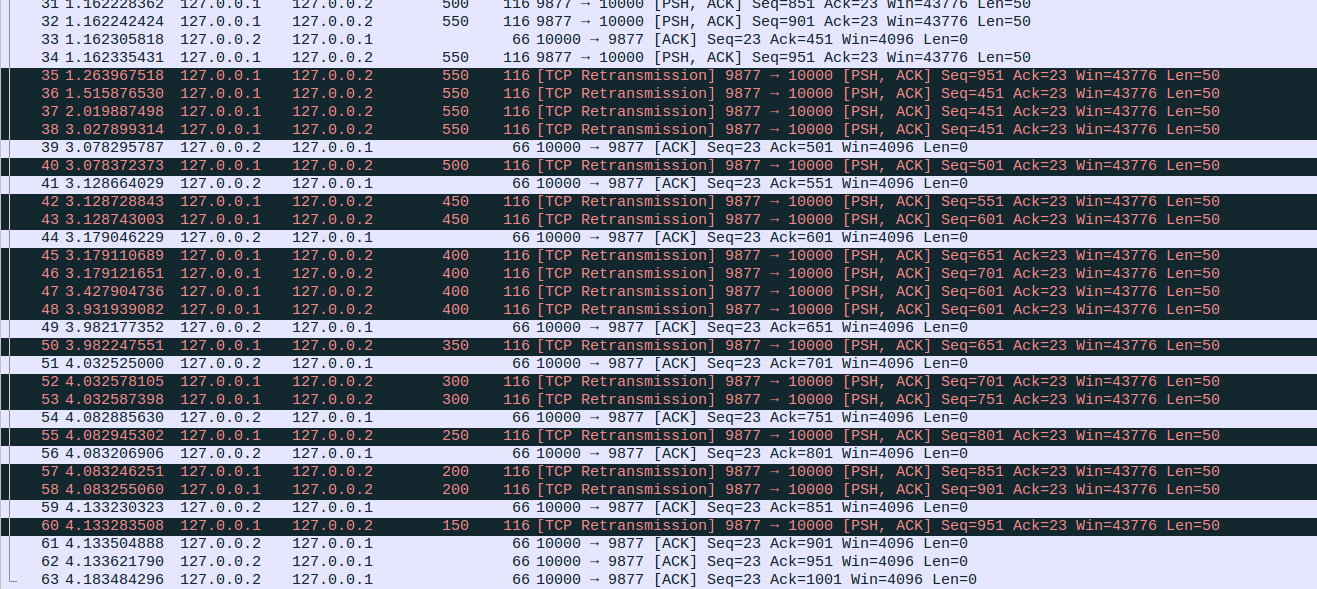
这个示例与综合示例非常类似,不同点在于这次RTO超时的是Seq为451的报文,而且No43对应的报文发生了两次RTO超时。下面总结一下这个示例相对于综合示例的几个注意点
No35:可以看到这个loss probe报文是个重传包,而之前综合示例中,loss probe报文是一个未发送过的报文,这里一定要分清,No35的重传是TLP超时触发的,而不是RTO超时触发。看不懂的前翻TLP的文章。
No43、No47、No48:No43是一个慢启动重传,并不是RTO超时触发的,因此不会更新ssthresh,而No47则是No43的RTO超时重传,因此会更新ssthresh = max(cwnd/2, 2),实际上在RTO超时发出No47之前,ssthresh=6,cwnd=4,而RTO超时发出No47报文后,则更新ssthresh=2,cwnd=1。No48同样是RTO超时重传,但是No48和No47是同一个数据包的多次连续RTO超时重传因此不会更新ssthresh。另外这里可以看到wireshark估计的in_flight的大小与linux的差异,例如在RTO超时重传No35后,linux计算的in_flight为1,大小实际为50bytes。之前我们已经介绍过多个linux和wireshark对数据包理解上的差异了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号