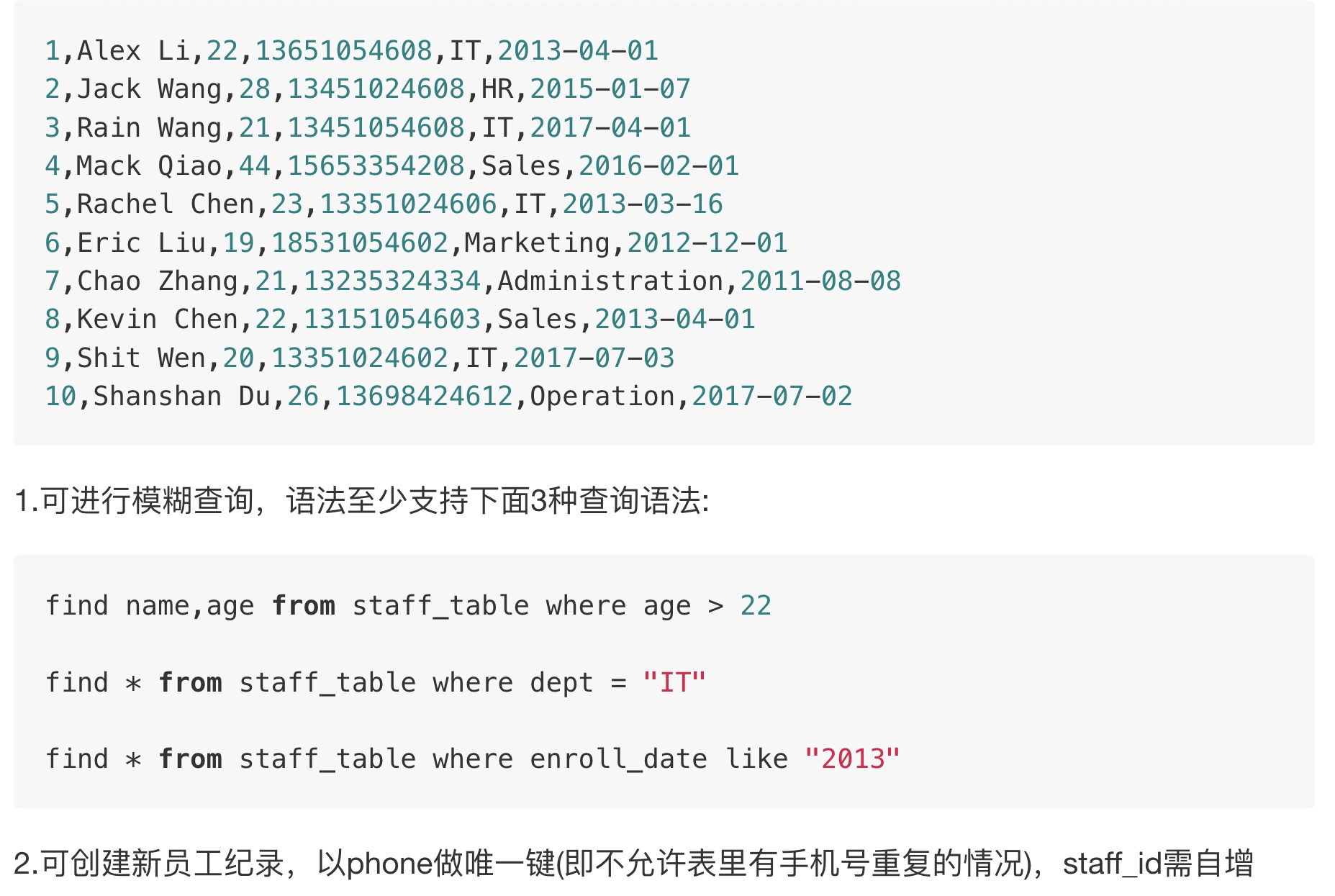
员工信息增删改查作业
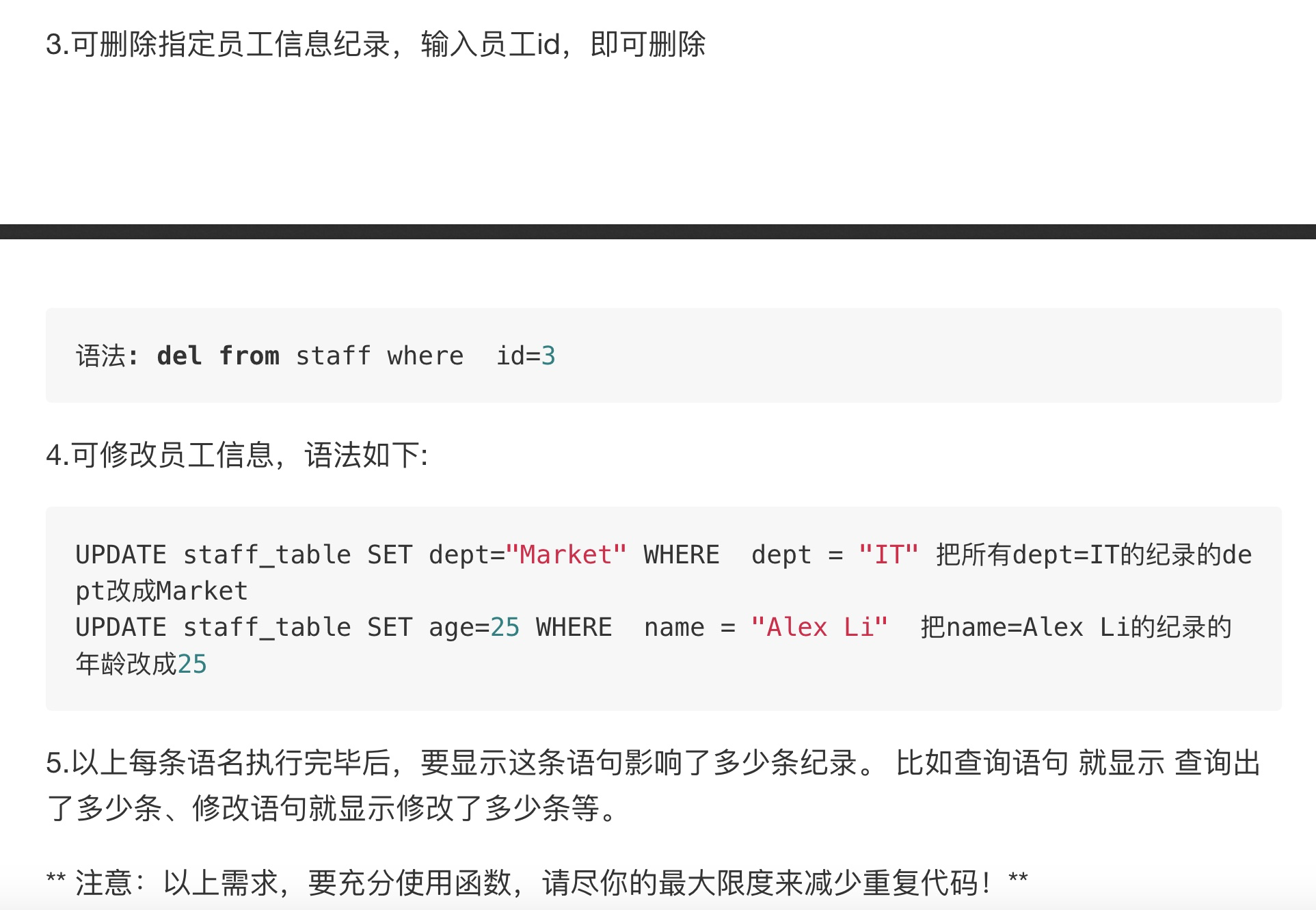
需求:
自己写的:
""" 除了支持作业中要求的语法,模糊查询还支持 >= <= 。严格按照作业中的语法,如果不按照作业中的语法会提示相应的错误。 增: 电话号码强制输入11位手机号而且里面不能有字母,否则会提示电话号码格式不对 add staff_table Alex Li,25,13443534411,IT,2015-10-29 删: del from staff_table where id=12 改: UPDATE staff_table SET dept="Market" WHERE dept = "IT" UPDATE staff_table SET age=26 WHERE name = "Alex Li" UPDATE staff_table SET age=25 WHERE phone = 13888888888 查: find name,age from staff_table where age > 22 find name,age from staff_table where age < 22 find name,age from staff_table where age >= 22 find name,age from staff_table where age <= 22 find * from staff_table where dept = "IT" find name,age from staff_table where age > 22 find * from staff_table where enroll_date like "2013" """ def add_staff(sql_cmd, matched_data): staff_id = [] staff_phone = [] filename = ''.join(sql_cmd[1]) + '.txt' try: with open(filename, 'r', encoding='utf-8') as f: # 把文件里的id写到staff_id = []里 for line in f: if len(line) == 1: # 如果有空行的话就跳过 continue staff_db_list = line.strip().split(',') staff_id.append(staff_db_list[0]) staff_phone.append(staff_db_list[3]) except FileNotFoundError: print('文件不存在,请查看输入顺序是否有误') else: for data in matched_data: if data in staff_phone: return print('号码已存在') new_id = str(int(staff_id[-1]) + 1) # 把最后一个id加1作为新id with open(filename, 'a', encoding='utf-8') as f2: f2.write( '\n' + new_id + ',' + matched_data[0] + ',' + matched_data[1] + ',' + matched_data[2] + ',' + matched_data[ 3] + ',' + matched_data[4]) print('添加成功') def search_staff(sql_cmd, matched_data): import re staff_info = {} filename = ''.join(matched_data[1]) + '.txt' try: with open(filename, 'r', encoding='utf-8') as f: for line in f: if len(line) == 1: continue staff_list = line.strip().split(',') staff_info[staff_list[0]] = { 'name': "\"" + staff_list[1] + "\"", 'age': int(staff_list[2]), 'phone': "\"" + staff_list[3] + "\"", 'dept': "\"" + staff_list[4] + "\"", 'enroll_date': "\"" + staff_list[5] + "\"", } except FileNotFoundError: print('文件不存在,请查看输入顺序是否有误') else: show_content = ''.join(matched_data[0]).split(',') # 查找内容 by_where = sql_cmd[0] # 在哪搜索 by_which = sql_cmd[1] # 通过哪种方法匹配 by_what = sql_cmd[2] # 匹配内容是什么 mached = {} tmp = 0 # 为了让by_what = by_what[1:-1]只执行一次 for key in staff_info: if by_which.lower() == 'like': if tmp == 0: by_what = by_what[1:-1] # 去掉开头和结尾的双引号,如何用户不按要求输入双引号,就搜索不到想要的结果 tmp += 1 if re.findall(r'^"\w*(%s)+-\d+-\d+"$' % by_what, staff_info[key][by_where]): mached[key] = staff_info[key] elif by_which == '=': if by_where == 'age': if staff_info[key][by_where] == int(by_what): mached[key] = staff_info[key] if staff_info[key][by_where] == by_what: mached[key] = staff_info[key] else: if by_where != 'age': return print('只有年龄可以比较大小') if by_which == '>': if staff_info[key][by_where] > int(by_what): mached[key] = staff_info[key] if by_which == '<': if staff_info[key][by_where] < int(by_what): mached[key] = staff_info[key] if by_which == '>=': if staff_info[key][by_where] >= int(by_what): mached[key] = staff_info[key] if by_which == '<=': if staff_info[key][by_where] <= int(by_what): mached[key] = staff_info[key] mached_num = len(mached.keys()) # 查到几条信息 display_all_data = {} display_data = {} count = 0 if '*' in show_content: display_all_data = mached else: for key in mached: for show in show_content: if show in mached[key]: count += 1 display_data[show + str(count)] = mached[key][show] print('共查询出了%s条记录' % mached_num) show_content_len = len(show_content) count2 = 0 count3 = 0 if display_all_data == {}: for key in display_data: if count2 % show_content_len == 0: # 每len(show_content)个信息,打印一个分割线 count3 += 1 print('--------------第%s条---------------' % count3) count2 += 1 print(display_data[key]) if display_data == {}: for key in display_all_data: count3 += 1 print('--------------第%s条---------------' % count3) print(mached[key]['name']) print(mached[key]['age']) print(mached[key]['phone']) print(mached[key]['dept']) print(mached[key]['enroll_date']) if display_all_data == {} and display_data == {}: return print('没有匹配的信息') def delete_staff(filename, user_id): filename = filename + '.txt' staff_info = {} try: with open(filename, 'r', encoding='utf-8') as f: for line in f: if len(line) == 1: continue staff_list = line.strip().split(',') staff_info[staff_list[0]] = { 'name': staff_list[1], 'age': staff_list[2], 'phone': staff_list[3], 'dept': staff_list[4], 'enroll_date': staff_list[5].strip(), } except FileNotFoundError: print('文件不存在') else: id_exist = False for key in list(staff_info.keys()): if user_id == key: staff_info.pop(key) id_exist = True if id_exist == True: with open(filename, 'w', encoding='utf-8') as f2: for key in staff_info: f2.write( key + ',' + staff_info[key]['name'] + ',' + staff_info[key]['age'] + ',' + staff_info[key][ 'phone'] + ',' + staff_info[key]['dept'] + ',' + staff_info[key]['enroll_date'] + '\n') print('删除成功') else: print('id不存在') def update_staff(filename, alter_where, where_data, original_keyword, alter_keyword): filename = filename + '.txt' if alter_where.lower() != 'age' and alter_where.lower() != 'phone': alter_keyword = alter_keyword[1:-1] # 去掉开头和结尾的双引号,如何用户不按要求输入双引号,就搜索不到想要的结果 if where_data.lower() != 'age' and where_data.lower() != 'phone': original_keyword = original_keyword[1:-1] staff_info = {} with open(filename, 'r', encoding='utf-8') as f: for line in f: if len(line) == 1: continue staff_list = line.strip().split(',') staff_info[staff_list[0]] = { 'name': staff_list[1], 'age': staff_list[2], 'phone': staff_list[3], 'dept': staff_list[4], 'enroll_date': staff_list[5], } count = 0 for key in staff_info: if staff_info[key][where_data] == original_keyword: count += 1 staff_info[key][alter_where] = alter_keyword with open(filename, 'w', encoding='utf-8') as f2: for key in staff_info: f2.write( key + ',' + staff_info[key]['name'] + ',' + staff_info[key]['age'] + ',' + staff_info[key][ 'phone'] + ',' + staff_info[key]['dept'] + ',' + staff_info[key]['enroll_date'] + '\n') if count == 0: print('没有符合条件的数据') else: print('修改成功,你共修改了%s条记录' % count) def staff_parse(cmd): cmd = cmd.split(' ') # 先用空格分开 if cmd[0].lower() == 'add': try: matched_data = cmd[2] + ' ' + cmd[3] # 从姓名开始把增加的数据提取成一个字符串,名和姓之间有空格,如果只输入名,会没有cmd[3]就到异常处理了 matched_data = matched_data.split(',') # 在把数据转换成列表 # 强制用户按顺序输入,否则从db拿电话号码查询是否重复的时候可能拿到别的数据 if len(matched_data[2]) != 11 or not matched_data[2].isdigit(): return print('没按顺序输入,或电话号码格式不对(请输入11位电话号码)\n' '请按顺序输入add 文件名 名、姓、年龄、手机号、部门、入职日期,并用空格隔开') # 强制年龄按顺序输入,防止提取年龄数据查询的时候出现错误 if len(matched_data[1]) != 2: return print('没按顺序输入,或年龄格式不对\n' '请按顺序输入add 文件名 名、姓、年龄、手机号、部门、入职日期,并用空格隔开') print( '你要增加的是:{0},{1},{2},{3},{4}'.format(matched_data[0], matched_data[1], matched_data[2], matched_data[3], matched_data[4], )) # 如果输入的数据不够,就到异常处理了 except IndexError: print('指令有误,请按顺序输入add 文件名 名、姓、年龄、手机号、部门、入职日期,并用空格隔开') else: sql_cmd = cmd[0:2] add_staff(sql_cmd, matched_data) elif cmd[0].lower() == 'find': keyword1 = ['from', 'where'] keyword2 = ['=', '>', '<', '>=', '<=', 'like'] try: # 强制用户按照正确的语法输入 if cmd[2].lower() not in keyword1 or cmd[4] not in keyword1: return print('指令有误,请按顺序输入 find 查找内容 from 文件名 where 查找条件,并用空格隔开') if cmd[6].lower() not in keyword2: return print('指令有误,匹配关键词为like,>,<,=,>=,<=') if len(cmd) > 8: return print('指定有误,长度超出') if cmd[5].lower() == 'age' and not cmd[7].isdigit(): # 如果输入年龄的话,查找条件就必须是数字 return print('年龄只接收整数') sql_cmd = cmd[5] + ' ' + cmd[6] + ' ' + cmd[7] # 最后三个匹配条件 matched_data = cmd[1] + ' ' + cmd[3] # 查找内容和文件名 except IndexError: print('指令有误,请按顺序输入 find 查找内容 from 文件名 where 查找条件,并用空格隔开') else: sql_cmd = sql_cmd.split(' ') matched_data = matched_data.split(' ') search_staff(sql_cmd, matched_data) elif cmd[0].lower() == 'del': keyword = ['from', 'where'] str_id = cmd[4][0:2] # 检验用户输入的是不是id这个关键字 user_id = cmd[4][3:] # 检验用户输入的是不是数字 equal_sign = cmd[4][2] # 检验是不是等号 if cmd[1] not in keyword or cmd[3] not in keyword: return print('指令有误,请按顺序输入 del from 文件名 where id=整数,并用空格隔开') if str_id.lower() != 'id': return print('请输入关键字:id') if not user_id.isdigit(): return print('请输入整数') if equal_sign != '=': return print('只支持等号') filename = ''.join(cmd[2]) delete_staff(filename, user_id) elif cmd[0].lower() == 'update': keyword = ['set', 'where'] try: if cmd[2].lower() not in keyword or cmd[4].lower() not in keyword: # 1.防止用户没输入关键词 2.如果用户没有用空格分开要修改的内容,cmd[4]就不是where,也会报错 return print('指令有误,请按顺序输入UPDATE 文件名 SET 要修改的内容(中间不能有空格) WHERE 原内容(用空格分开),并用空格隔开') if cmd[6] != '=' or '=' not in cmd[3]: # 1.防止输入其他符号 2. 如果用户如输入的最后三条内容没有空格也会报这个错误 return print('只支持等号,或指令输入有误,请按顺序输入UPDATE 文件名 SET 要修改的内容(中间不能有空格) WHERE 原内容(用空格分开),并用空格隔开') except IndexError: return print('指令有误,请按顺序输入UPDATE 文件名 SET 要修改的内容(中间不能有空格) WHERE 原内容(用空格分开),并用空格隔开') else: search_keyword = ['name', 'age', 'phone', 'dept', 'enroll_date'] where_data = cmd[5] # 修改哪里的内容 关键词WHERE后面那个指定在哪符合什么条件,没有等号和原始内容 where1_equal_index = cmd[3].index('=') alter_where = cmd[3][0:where1_equal_index] # 关键词set后面指定要在哪里修改,去除掉等号和后面的修改内容 if alter_where in search_keyword and where_data in search_keyword: filename = cmd[1] original_keyword = ' '.join(cmd[7:]) # 数据库里是这个的将被修改 alter_keyword = cmd[3][where1_equal_index + 1:] # 修改成什么 update_staff(filename, alter_where, where_data, original_keyword, alter_keyword) else: return print('修改的内容不存在') else: print('指令不存在') if __name__ == '__main__': def main(): ''' 主程序入口 :return: ''' while True: cmd = input('please enter sql:').strip() if not cmd: continue if cmd.lower() == 'exit': return None else: staff_parse(cmd) main()
讲解版本:
import os import re from tabulate import tabulate DB_FILE = 'staff_table.txt' COLUMNS = ['id', 'name', 'age', 'phone', 'dept', 'enrolled_date'] def load_db(db_file): data = {} for i in COLUMNS: data[i] = [] with open(db_file, 'r', encoding='utf-8') as f: for line in f: staff_id, name, age, phone, dept, enrolled_date = line.split(',') data['id'].append(staff_id) data['name'].append(name) data['age'].append(age) data['phone'].append(phone) data['dept'].append(dept) data['enrolled_date'].append(enrolled_date) return data STAFF_DATE = load_db(DB_FILE) def save_db(): with open('%s.new' % DB_FILE, 'w', encoding='utf-8') as f: for index, staff_id in enumerate(STAFF_DATE['id']): row = [] for col in COLUMNS: row.append(STAFF_DATE[col][index]) f.write(','.join(row)) os.rename("%s.new" % DB_FILE, DB_FILE) def print_log(msg, log_type='info'): if log_type == 'info': print('\033[32;1m%s\033[0m' % msg) elif log_type == 'error': print('\033[31;1m%s\033[0m' % msg) def op_gt(column, condition): matched_date = [] for index, val in enumerate(STAFF_DATE[column]): if float(val) > float(condition): record = [] for col in COLUMNS: record.append(STAFF_DATE[col][index]) matched_date.append(record) if matched_date == []: print_log('没有匹配到', 'error') return None else: return matched_date def op_lt(column, condition): matched_date = [] for index, val in enumerate(STAFF_DATE[column]): if float(val) < float(condition): record = [] for col in COLUMNS: record.append(STAFF_DATE[col][index]) matched_date.append(record) if matched_date == []: print_log('没有匹配到', 'error') return None else: return matched_date def op_eq(column, condition): matched_date = [] for index, val in enumerate(STAFF_DATE[column]): if val == condition: record = [] for col in COLUMNS: record.append(STAFF_DATE[col][index]) matched_date.append(record) if matched_date == []: print_log('没有匹配到', 'error') return None else: return matched_date def op_like(column, condition): matched_date = [] for index, val in enumerate(STAFF_DATE[column]): if condition in val: record = [] for col in COLUMNS: record.append(STAFF_DATE[col][index]) matched_date.append(record) if matched_date == []: print_log('没有匹配到', 'error') return None else: print(matched_date) return matched_date def syntax_where(clause): operator = { '>': op_gt, '<': op_lt, '=': op_eq, 'like': op_like, } parttern = re.compile('(?P<column>.+)(?P<operation>>|<|=|like+)(?P<condition>.+)') data = re.search(parttern, clause) try: column = data.groupdict()['column'].strip() operation = data.groupdict()['operation'] condition = data.groupdict()['condition'].strip() except Exception: print_log('语法错误:where条件只能支持[>,<,=,like]', 'error') else: matched_data = operator[operation](column, condition) return matched_data def syntax_find(data_set, query_clause): filter_cols = query_clause.split('from')[0][4:].split(',') filter_cols = [i.strip() for i in filter_cols] # 干净的columns if '*' in filter_cols[0]: print(tabulate(data_set, headers=COLUMNS, tablefmt='grid')) else: reformat_data_set = [] for row in data_set: filtered_vals = [] for col in filter_cols: col_index = COLUMNS.index(col) filtered_vals.append(row[col_index]) reformat_data_set.append(filtered_vals) print(tabulate(reformat_data_set, headers=filter_cols, tablefmt='grid')) print_log('匹配到%s条数据' % len(data_set)) def syntax_delete(data_set): staff_id = int(data_set[0][0]) - 1 # 获取id ,列表是从0开始数,所以减1 for data in list(STAFF_DATE.keys()): STAFF_DATE[data].pop(staff_id) save_db() print_log('删除成功') def syntax_update(data_set, query_clause): need_set_row = query_clause.split('set') if len(need_set_row) > 1: col_name, new_val = need_set_row[1].strip().split('=') # age = 25 col_index = COLUMNS.index(col_name) # 循环data_set,取到每条记录的id,拿着这个id到STAFF_DATE['id]里找对应的id的索引,找到之后,再拿这个索引,去STAFF_DATA['age']列表里,改对应索引的值 for mached_row in data_set: staff_id = mached_row[0] staff_id_index = STAFF_DATE['id'].index(staff_id) STAFF_DATE[col_name][staff_id_index] = new_val print(STAFF_DATE) save_db() print_log('成功修改了%s条数据' % len(data_set)) else: print_log('语法错误:未检测到set关键字!', 'error') def syntax_add(query_clause): # add staff_table Alex Bai,25,13451054622,Market,2016‐01-11 query_clause = query_clause.split(',') # 转成列表 name = ' '.join(query_clause[0].split(' ')[2:]) # 提取出名字 query_clause[0] = name # 把 add staff_table 换成名字 new_id = len(STAFF_DATE['id']) + 1 query_clause.insert(0, str(new_id)) # 加上id 只剩添加内容了 last_data = query_clause[-1] last_data = last_data + '\n' # 给最后一个元素加上换行符 query_clause[-1] = last_data for index, cow in enumerate(COLUMNS): if len(query_clause[index]) == 11 and query_clause[index] in STAFF_DATE[cow]: print_log('电话号码不能重复', 'error') return None STAFF_DATE[cow].append(query_clause[index]) save_db() print_log('添加成功') def syntax_parser(cmd): # find name,age from staff_table where age > 22 syntax_list = { 'find': syntax_find, 'del': syntax_delete, 'update': syntax_update, 'add': syntax_add, } if cmd.split()[0].lower() in ('find', 'add', 'del', 'update'): if 'where' in cmd: query_clause, where_clause = cmd.split('where') matched_record = syntax_where(where_clause) elif 'WHERE' in cmd: query_clause, where_clause = cmd.split('WHERE') matched_record = syntax_where(where_clause) else: matched_record = [] # add staff_table Alex Li,25,134435344,IT,2015‐10‐29 for index, staff_id in enumerate(STAFF_DATE['id']): record = [] for cow in COLUMNS: record.append(STAFF_DATE[cow][index]) matched_record.append(record) query_clause = cmd cmd_action = cmd.split()[0].lower() if cmd_action in syntax_list: if cmd_action == 'add': syntax_list[cmd_action](query_clause) elif cmd_action == 'del': syntax_list[cmd_action](matched_record) else: syntax_list[cmd_action](matched_record, query_clause) else: print_log('语法错误:[find\\add\del\\update] [column1,...] from [staff_table] [where] [column] [>,..] [condition]', 'error') def main(): while True: cmd = input('[staff_db]:').strip() if not cmd: continue syntax_parser(cmd) main() # FIND name,age from staff_table WHERE age > 22 # find * from staff_table where age > 22 # update staff_table set dept=Market where dept = IT # UPDATE staff_table set dept=技术部 where name=Alex Li # UPDATE staff_table set dept=开发部 where dept=技术部

 浙公网安备 33010602011771号
浙公网安备 33010602011771号