
1. 下载 ollama https://ollama.com/
2. 安装完成后,没有操作界面(只能CLI)
3. 检测 安装是否成功 ollama --version
4.常用命令: ollama help
修改默认模型下载位置:
概述:Ollama默认将模型保存在C盘(Windows)、~/.ollama/models(MacOS)或/usr/share/ollama/.ollama/models(Linux)。
为了解决C盘空间不足的问题,可以通过设置环境变量OLLAMA_MODELS来修改模型存储位置。 Windows系统:(系统变量) 设置环境变量OLLAMA_MODELS,例如E:\ollama\models。 重启Ollama或PowerShell,使设置生效。 MacOS系统: 通过设置环境变量OLLAMA_MODELS,例如~/ollama/models。 重启Ollama服务。 Linux系统: 创建新目录并设置权限,例如sudo mkdir /path/to/ollama/models。 编辑ollama.service文件,添加环境变量OLLAMA_MODELS。 重启ollama服务。
5.下载模型: https://ollama.com/library
命令 :
ollama run llama3.1
完成后即可问答了
6. 运行模型提供API
6.1 安装代理服务:
创建新的虚拟环境 python -m venv D:/ollama
激活环境:
ollama/Scripts/active.bat
(ollama)> pip install litellm
pip install litellm[proxy](提供代理服务)
6.2 运行模型,提供服务:
litellm --model ollama/llama3.1
7. ollama 直接提供服务:(REST 缺省只支持本机访问,要对外提供服务,需要设置环境变量: OLLAMA_HOST=0.0.0.0)
ollama无法使用本地IP访问11434端口,但是localhost和127.0.0.1可以访问
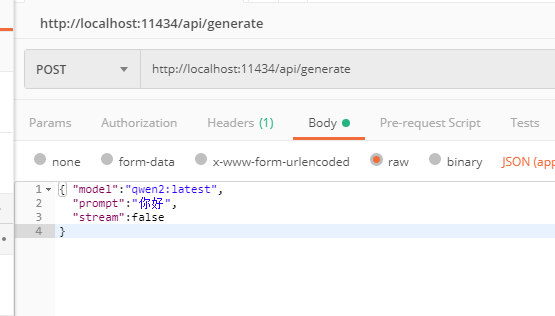
POST json url: http://localhost:11434/api/generate
body: { "model":"qwen2:latest",
"prompt":"你好",
"stream":false
}
curl -X POST -H "Content-Type: application/json" http://localhost:11434/api/generate -d "{\"model\":\"llama3\",\"prompt\":\"Why is the sky blue?\"}"
API 说明:
/api/generate 用途: 这个端点主要用于生成单个文本片段。它接收输入并返回基于该输入的模型生成的文本,通常不考虑之前的消息历史或对话上下文。 功能: 它可以用于各种生成任务,如文章创作、代码生成、故事编写等,其中每次请求都是独立的,不依赖于前一次请求的结果。 /api/chat 用途: 这个端点用于支持对话式的交互。它通常需要一个消息列表作为输入,以维护对话的历史和上下文,确保模型能够理解并响应连续的对话。 功能: 它适合于创建聊天机器人、问答系统或任何需要多轮对话的应用场景。通过跟踪对话历史,模型可以提供更加连贯和情境相关的响应。
基于ollama 的流式聊天:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # @mail : lshan523@163.com # @Time : 2024/11/21 18:14 # @Author : Sea # @File : OlllamaChat2.py # @Purpose : # @history: # **************************** import json import requests # NOTE: ollama must be running for this to work, start the ollama app or run `ollama serve` model = "qwen2:latest" # TODO: update this for whatever model you wish to use def chat(messages): r = requests.post( # "http://127.0.0.1:11434/api/generate", "http://127.0.0.1:11434/api/chat", json={"model": model, "messages": messages, "stream": True}, ) r.raise_for_status() output = "" for line in r.iter_lines(): body = json.loads(line) if "error" in body: raise Exception(body["error"]) if body.get("done") is False: message = body.get("message", "") content = message.get("content", "") output += content # the response streams one token at a time, print that as we receive it print(content, end="", flush=True) if body.get("done", False): message["content"] = output return message def main(): messages = [] while True: user_input = input("Enter a prompt: ") if not user_input: exit() messages.append({"role": "user", "content": user_input}) message = chat(messages) messages.append(message) print("\n\n") if __name__ == "__main__": main()

