问题:目前2.0 还未解决该问题
(1)log4j的日志文件肯定是会根据规则进行滚动的:当*.log满了就会滚动把前文件更名为*.log.1,然后重新进行*.log文件打印。这样flume就会把*.log.1文件当作新文件,又重新读取一遍,导致重复。
(2)当flume监控的日志文件被移走或删除,flume仍然在监控中,并没有释放资源,当然,在一定时间后会自动释放,这个时间根据官方文档设置默认值是120000ms。
个人编译好的jar: https://gitee.com/lshan523/flume1.9
案例: 监听文件 /opt/service/xx-user-service 下的logger , 并且发送到kakfa topic flume_log_test_topic
Docker 发布:
mkdir -p /opt/docker/flume/checkpoint/ sudo docker run -itd --privileged --name=my_flume \ -e "kafka_topic=flume_log_test_topic " \ -e "kafka_bootstrap_servers=192.168.18.199:9092,192.168.18.54:9092,192.168.18.176:9092" \ -e "listener_file_groups=/opt/listener/.*log.*" \ -e "taildir_checkpoint_position=/opt/checkpoint/taildir_position.json" \ -v /opt/service/xx-user-service/:/opt/listener/:rw \ -v /opt/docker/flume/checkpoint/:/opt/checkpoint/:rw \ happysea/flume:1.9.0
-v /opt/service/xx-user-service/:/opt/listener/:rw 需要监听的文件目录
-e "listener_file_groups=/opt/listener/.*log.*" \ 需要监听文件后缀
非docker 操作如下:
adoop@bx002:~/apache-flume-1.9.0-bin$ ls bin CHANGELOG conf DEVNOTES doap_Flume.rdf docs job lib LICENSE NOTICE README.md RELEASE-NOTES start_cbb_log_kafka_job.sh tools
准备:
mkdir -p /home/hadoop/flume/checkpoint/ touch taildir_position.json sudo chmod 777 /home/hadoop/flume/checkpoint/taildir_position.json
vim ./job/taildirSource-kafka.conf


#taildir source http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#kafka-channel #为各个组件命名 a1.sources = r1 a1.channels = c1 #声明source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 #监控的目录 /log/app.* #a1.sources.r1.filegroups.f1 = /home/sea/Desktop/xx/log/.*log.* a1.sources.r1.filegroups.f1 = /tmp/bx-gate-service-path_record.*log.* #开启断点续传,不配置 默认开启 a1.sources.r1.positionFile= /home/hadoop/flume/checkpoint/taildir_position.json a1.sources.r1.fileHeader = true #kafka channel #channels a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = hadoop001:9092,hadoop004:9092,hadoop005:9092 a1.channels.c1.kafka.topic = cbb_api_request_log a1.channels.c1.parseAsFlumeEvent = false # 配置生产者的ack为1 a1.channels.c1.kafka.producer.acks = 1 # 配置生产者的批大小为1000 a1.channels.c1.kafka.producer.batch.size = 1000 a1.channels.c1.kafka.producer.linger.ms = 5000 #绑定source和channel以及sink和channel的关系 a1.sources.r1.channels = c1
启动: start_cbb_log_kafka_job.sh
bin/flume-ng agent --conf conf --conf-file job/taildirSource-kafka.conf --name a1 -Dflume.root.logger=INFO,console
原文: https://blog.csdn.net/maoyuanming0806/article/details/79391657
flume使用(三):实时log4j日志通过flume输出到MySql数据库
flume使用(四):taildirSource多文件监控实时采集
本文针对【flume使用(四):taildirSource多文件监控实时采集】一文中提出的两个flume的TailDirSource可能出现的问题进行解决。
一、问题思考
(1)log4j的日志文件肯定是会根据规则进行滚动的:当*.log满了就会滚动把前文件更名为*.log.1,然后重新进行*.log文件打印。这样flume就会把*.log.1文件当作新文件,又重新读取一遍,导致重复。
(2)当flume监控的日志文件被移走或删除,flume仍然在监控中,并没有释放资源,当然,在一定时间后会自动释放,这个时间根据官方文档设置默认值是120000ms。
二、处理方式
我这里不叫解决方式,在其他人的文章中说这两个是bug,个人认为这都不是bug。大家都知道flume作为apache的顶级项目,真有这样的bug在它的托管网站上肯定有相关pull并且肯定会有尽快的解决。至少,在flume1.8上会解决掉。个人查看了flume1.8处理的bug和功能的增加list中,对于(1)(2)没有关于这样解决项。
官方文档1.8的release说明:只有这一项关于taildir,解决的是当flume关闭文件同时该文件正更新数据。

官网:http://flume.apache.org/releases/1.8.0.html
(1)flume会把重命名的文件重新当作新文件读取是因为正则表达式的原因,因为重命名后的文件名仍然符合正则表达式。所以第一,重命名后的文件仍然会被flume监控;第二,flume是根据文件inode&&文件绝对路径 、文件是否为null&&文件绝对路径,这样的条件来判断是否是同一个文件这个可以看源码:下载源码,放到maven项目(注意路径名称对应),找到taildirsource的包。
先看执行案例:
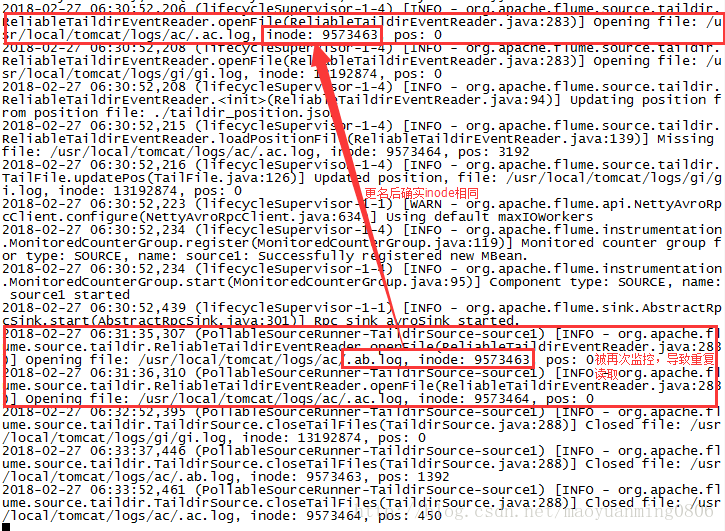
确实是有重复,然后看源码:flume-taildir-source工程
- ReliableTaildirEventReader 类的 updateTailFiles 方法
public List<Long> updateTailFiles(boolean skipToEnd) throws IOException {
updateTime = System.currentTimeMillis();
List<Long> updatedInodes = Lists.newArrayList();
for (TaildirMatcher taildir : taildirCache) {
Map<String, String> headers = headerTable.row(taildir.getFileGroup());
for (File f : taildir.getMatchingFiles()) {
long inode = getInode(f);
TailFile tf = tailFiles.get(inode);
if (tf == null || !tf.getPath().equals(f.getAbsolutePath())) {
long startPos = skipToEnd ? f.length() : 0;
tf = openFile(f, headers, inode, startPos);
} else {
boolean updated = tf.getLastUpdated() < f.lastModified();
if (updated) {
if (tf.getRaf() == null) {
tf = openFile(f, headers, inode, tf.getPos());
}
if (f.length() < tf.getPos()) {
logger.info("Pos " + tf.getPos() + " is larger than file size! "
+ "Restarting from pos 0, file: " + tf.getPath() + ", inode: " + inode);
tf.updatePos(tf.getPath(), inode, 0);
}
}
tf.setNeedTail(updated);
}
tailFiles.put(inode, tf);
updatedInodes.add(inode);
}
}
return updatedInodes;
}重点:
for (File f : taildir.getMatchingFiles()) {
long inode = getInode(f);
TailFile tf = tailFiles.get(inode);
if (tf == null || !tf.getPath().equals(f.getAbsolutePath())) {
long startPos = skipToEnd ? f.length() : 0;
tf = openFile(f, headers, inode, startPos);
} - TailFile 类的 updatePos 方法:
public boolean updatePos(String path, long inode, long pos) throws IOException {
<strong>if (this.inode == inode && this.path.equals(path)) {<!-- --></strong>
setPos(pos);
updateFilePos(pos);
logger.info("Updated position, file: " + path + ", inode: " + inode + ", pos: " + pos);
return true;
}
return false;
}这样带来的麻烦就是当文件更名后仍然符合正则表达式时,会被flume进行监控,即使inode相同而文件名不同,flume就认为是新文件。
实际上这是开发者自身给自己造成的不便,完全可以通过监控文件名的正则表达式来排除重命名的文件。
就如正则表达式:【.*.log.* 】这样的正则表达式当然文件由 .ac.log 重命名为.ac.log.1会带来重复读取的问题。
而正则表达式:【.*.log】 当文件由 .ac.log 重命名为 .ac.log.1 就不会被flume监控,就不会有重复读取的问题。
以上是针对这个问题并flume团队没有改正这个问题原因的思考。
当然,如果类似【.*.log.* 】这样的正则表达式在实际生产中是非常必要使用的话,那么flume团队应该会根据github上issue的呼声大小来考虑是否修正到项目中。
那么实际生产中真需要这样的正则表达式来监控目录下的文件的话,为了避免重复读取,就需要对flume1.7源码进行修改:
处理问题(1)方式
1.修改 ReliableTaildirEventReader
修改 ReliableTaildirEventReader 类的 updateTailFiles方法。
去除tf.getPath().equals(f.getAbsolutePath()) 。只用判断文件不为空即可,不用判断文件的名字,因为log4j 日志切分文件会重命名文件。
if (tf == null || !tf.getPath().equals(f.getAbsolutePath())) {
修改为:
if (tf == null) {<!-- -->2.修改TailFile
修改TailFile 类的 updatePos方法。
inode 已经能够确定唯一的 文件,不用加 path 作为判定条件
if (this.inode == inode && this.path.equals(path)) {
修改为:
if (this.inode == inode) {<!-- -->3.将修改过的代码打包为自定义source的jar
可以直接打包taildirSource组件即可,然后替换该组件的jar
此时可以进行测试。
处理问题(2)
问题(2)说的是,当监控的文件不存在了,flume资源没有释放。
这个问题也不是问题,实际上,资源的确会释放,但是 是有一定时间等待。
查看flume1.7官方文档taildirSource说明:

可知,如果这个文件在默认值120000ms内都没有新行append,就会关闭资源;而当有新行append就自动打开该资源。
也就是说,默认120000ms--》2分钟后会自动关闭所谓没有释放的资源。
为了避免这么长时间的资源浪费,可以把这个值调小一些。但是,官方给定的默认值为什么这么大(相对于类似超时时间都是秒单位的,而这是分钟单位)?当然不能为所欲为的把这个值改小,频繁的开关文件资源造成系统资源的浪费更应该考虑。
一般没有很好的测试过性能的话,还是按照默认值来就可以了。
以上,是个人见解,若有研究不当之处,叙述不当之处,敬请指出,倍加感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号