原文: https://blog.csdn.net/MyronCham/article/details/85706089
参考上文即可!
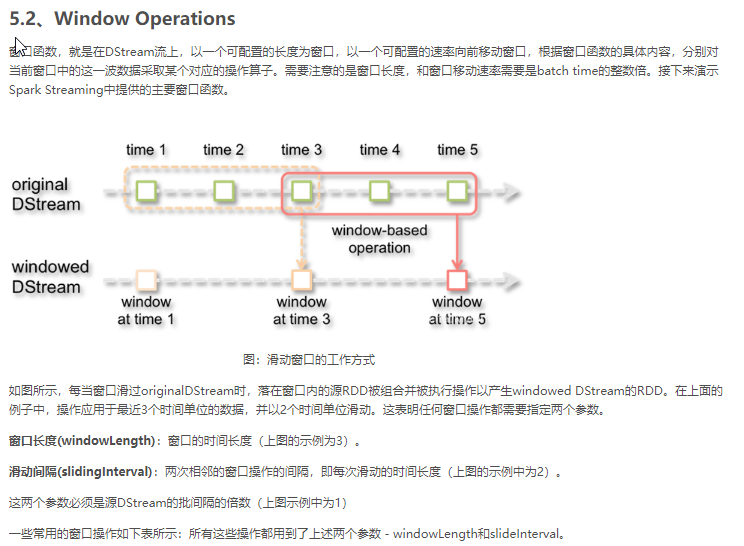

案例一: reduceByKeyAndWindow
// 热点搜索词滑动统计,每隔10秒钟,统计最近60秒钟的搜索词的搜索频次,并打印出排名最靠前的3个搜索词以及出现次数
package com.sea.scala.demo.windows import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} object ReduceByKeyAndWindowDemo { // 热点搜索词滑动统计,每隔10秒钟,统计最近60秒钟的搜索词的搜索频次,并打印出排名最靠前的3个搜索词以及出现次数 def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("WindowHotWordS").setMaster("local[2]") //Scala中,创建的是StreamingContext val ssc = new StreamingContext(conf, Seconds(5)) val searchLogsDStream = ssc.socketTextStream("localhost", 8099) val searchWordPairDStream=searchLogsDStream.flatMap(_.split(" ")).map((_,1)) // reduceByKeyAndWindow // 第二个参数,是窗口长度,这是是60秒 // 第三个参数,是滑动间隔,这里是10秒 // 也就是说,每隔10秒钟,将最近60秒的数据,作为一个窗口,进行内部的RDD的聚合,然后统一对一个RDD进行后续计算 // 而是只是放在那里 // 然后,等待我们的滑动间隔到了以后,10秒到了,会将之前60秒的RDD,因为一个batch间隔是5秒,所以之前60秒,就有12个RDD,给聚合起来,然后统一执行reduceByKey操作 // 所以这里的reduceByKeyAndWindow,是针对每个窗口执行计算的,而不是针对 某个DStream中的RDD // 每隔10秒钟,出来 之前60秒的收集到的单词的统计次数 val searchWordCountsDStream = searchWordPairDStream .reduceByKeyAndWindow((v1: Int, v2: Int) => v1 + v2, Seconds(60), Seconds(10)) val finalDStream = searchWordCountsDStream.transform(searchWordCountsRDD => { val countSearchWordsRDD = searchWordCountsRDD.map(tuple => (tuple._2, tuple._1)) //排序,key value 倒置,根据value倒叙排列,提取top3 val sortedCountSearchWordsRDD = countSearchWordsRDD.sortByKey(false) val sortedSearchWordCountsRDD = sortedCountSearchWordsRDD.map(tuple => (tuple._1, tuple._2)) val top3SearchWordCounts = sortedSearchWordCountsRDD.take(3) for (tuple <- top3SearchWordCounts) { println("result-top3 : " + tuple) } searchWordCountsRDD }) finalDStream.print() ssc.start() ssc.awaitTermination() } }
案例2 :原文链接:https://blog.csdn.net/h1025372645/java/article/details/99233218
Spark Streaming使用window函数与reduceByKeyAndWindow实现一定时间段内读取Kafka中的数据累加;reduceByKeyAndWindow函数的两种使用方式
使用window函数实现时间段内数据累加:
import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object J_WindowOrderTotalStreaming { //批次时间,Batch Interval val STREAMING_BATCH_INTERVAL = Seconds(1) //设置窗口时间间隔 val STREAMING_WINDOW_INTERVAL = STREAMING_BATCH_INTERVAL * 3 //设置滑动窗口时间间隔 val STREAMING_SLIDER_INTERVAL = STREAMING_BATCH_INTERVAL * 3 def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[3]"). setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, STREAMING_BATCH_INTERVAL) ssc.sparkContext.setLogLevel("WARN") val kafkaParams: Map[String, String] = Map( "metadata.broker.list"-> "bigdata-hpsk01.huadian.com:9092,bigdata-hpsk01.huadian.com:9093,bigdata-hpsk01.huadian.com:9094", "auto.offset.reset"->"largest" //读取最新数据 ) val topics: Set[String] = Set("orderTopic") val lines: DStream[String] = KafkaUtils.createDirectStream[String, String, StringDecoder,StringDecoder]( ssc, kafkaParams, topics ).map(_._2) //只需要获取Topic中每条Message中Value的值 val inputDStream = lines.window(STREAMING_WINDOW_INTERVAL,STREAMING_SLIDER_INTERVAL) val orderDStream: DStream[(Int, Int)] = inputDStream.transform(rdd=>{ rdd.filter(line=>line.trim.length> 0 && line.trim.split(",").length==3) .map(line=> { val split = line.split(",") (split(1).toInt,1) }) }) val orderCountDStream =orderDStream.reduceByKey( _ + _) orderCountDStream.print() ssc.start() ssc.awaitTermination() } } 原文链接:https://blog.csdn.net/h1025372645/java/article/details/99233218
使用reduceByKeyAndWindow实现累加方法一:不需要设置检查点
import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object K_WindowOrderTotalStreaming { //批次时间,Batch Interval val STREAMING_BATCH_INTERVAL = Seconds(5) //设置窗口时间间隔 val STREAMING_WINDOW_INTERVAL = STREAMING_BATCH_INTERVAL * 3 //设置滑动窗口时间间隔 val STREAMING_SLIDER_INTERVAL = STREAMING_BATCH_INTERVAL * 2 def main(args: Array[String]): Unit = { val conf = new SparkConf() .setMaster("local[3]") //为什么启动3个,有一个Thread运行Receiver .setAppName("J_WindowOrderTotalStreaming") val ssc: StreamingContext = new StreamingContext(conf, STREAMING_BATCH_INTERVAL) //日志级别 ssc.sparkContext.setLogLevel("WARN") val kafkaParams: Map[String, String] = Map( "metadata.broker.list"->"bigdata-hpsk01.huadian.com:9092,bigdata-hpsk01.huadian.com:9093,bigdata-hpsk01.huadian.com:9094", "auto.offset.reset"->"largest" //读取最新数据 ) val topics: Set[String] = Set("orderTopic") val kafkaDStream: DStream[String] = KafkaUtils .createDirectStream[String, String, StringDecoder,StringDecoder]( ssc, kafkaParams, topics ).map(_._2) //只需要获取Topic中每条Message中Value的值 //设置窗口 val orderDStream: DStream[(Int, Int)] = kafkaDStream.transform(rdd=>{ rdd //过滤不合法的数据 .filter(line => line.trim.length >0 && line.trim.split(",").length ==3) //提取字段 .map(line =>{ val splits = line.split(",") (splits(1).toInt,1) }) }) /** * reduceByKeyAndWindow = window + reduceByKey * def reduceByKeyAndWindow( * reduceFunc: (V, V) => V, * windowDuration: Duration, * slideDuration: Duration * ): DStream[(K, V)] */ //统计各个省份订单数目 val orderCountDStream = orderDStream.reduceByKeyAndWindow( (v1:Int, v2:Int) => v1 + v2, STREAMING_WINDOW_INTERVAL, STREAMING_SLIDER_INTERVAL ) orderCountDStream.print() //启动流式实时应用 ssc.start() // 将会启动Receiver接收器,用于接收源端 的数据 //实时应用一旦启动,正常情况下不会自动停止,触发遇到特性情况(报错,强行终止) ssc.awaitTermination() // Wait for the computation to terminate } } 原文链接:https://blog.csdn.net/h1025372645/java/article/details/99233218
使用reduceByKeyAndWindow实现累加方法二:设置检查点
import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object L_TrendOrderTotalStreaming { //检查点存放目录 val CHECK_POINT_PATH = "file:///E:\\JavaWork\\20190811\\test93" //批次时间,Batch Interval val STREAMING_BATCH_INTERVAL = Seconds(1) //设置窗口时间间隔 val STREAMING_WINDOW_INTERVAL = STREAMING_BATCH_INTERVAL * 3 //设置滑动窗口时间间隔 val STREAMING_SLIDER_INTERVAL = STREAMING_BATCH_INTERVAL * 3 def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[3]"). setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, STREAMING_BATCH_INTERVAL) ssc.sparkContext.setLogLevel("WARN") ssc.checkpoint(CHECK_POINT_PATH) val kafkaParams: Map[String, String] = Map( "metadata.broker.list"-> "bigdata-hpsk01.huadian.com:9092,bigdata-hpsk01.huadian.com:9093,bigdata-hpsk01.huadian.com:9094", "auto.offset.reset"->"largest" //读取最新数据 ) val topics: Set[String] = Set("orderTopic") val lines: DStream[String] = KafkaUtils.createDirectStream[String, String, StringDecoder,StringDecoder]( ssc, kafkaParams, topics ).map(_._2) //只需要获取Topic中每条Message中Value的值 val orderDStream: DStream[(Int, Int)] = lines.transform(rdd=>{ rdd.filter(line=>line.trim.length> 0 && line.trim.split(",").length==3) .map(line=> { val split = line.split(",") (split(1).toInt,1) }) }) val orderCountDStream = orderDStream.reduceByKeyAndWindow( (v1:Int, v2:Int) => v1 + v2, (v1:Int, v2:Int) => v1 - v2, STREAMING_WINDOW_INTERVAL, STREAMING_SLIDER_INTERVAL ) orderCountDStream.print() ssc.start() ssc.awaitTermination() } } ———————————————— 原文链接:https://blog.csdn.net/h1025372645/java/article/details/99233218

 浙公网安备 33010602011771号
浙公网安备 33010602011771号