
1.基础语法: 相关网站: http://www.runoob.com/mongodb/mongodb-query.html
Noted: 1> can not order by multiple fields.
2> better to use object array , not use a string to save a array data.
2.链接DB工具 1> nosqlbooster : https://nosqlbooster.com/downloads
2> studio 3T : https://studio3t.com/download-now/ win版破解方法网站: https://www.jianshu.com/p/cc97f31509ea
3聚合查询:
管道操作符


常用管道 含义 $group 将collection中的document分组,可用于统计结果 $match 过滤数据,只输出符合结果的文档 $project 修改输入文档的结构(例如重命名,增加、删除字段,创建结算结果等) $sort 将结果进行排序后输出 $limit 限制管道输出的结果个数 $skip 跳过制定数量的结果,并且返回剩下的结果 $unwind 将数组类型的字段进行拆分
表达式操作符
常用表达式 含义
$sum 计算总和,{$sum: 1}表示返回总和×1的值(即总和的数量),使用{$sum: '$制定字段'}也能直接获取制定字段的值的总和
$avg 平均值
$min min
$max max
$push 将结果文档中插入值到一个数组中
$first 根据文档的排序获取第一个文档数据
$last 同理,获取最后一个数据
# select count(*) from tb_sea group by userId
db.tb_sea.aggregate([{$group : {_id : "$userId", total : {$sum : 1}}}]) { "result" : [ { "_id" : "sea", "total" : 2 }, { "_id" : "shan", "total" : 1 } ], "ok" : 1 }
$match
# select count(*) from tb_sea where score >70 and score <90 group by userId
db.articles.aggregate( [ { $match : { score : { $gt : 70, $lte : 90 } } }, { $group: { _id: $userId, count: { $sum: 1 } } } ] );
关联查询:
# select b.bookingNO, b.origin,b.mawbNo,b.status from tb_booking b inner join tb_milestone as milestone_docs where b.status !='X' and milestone_docs.status ='RCF'
and b.bookingNo in ['1233' ,'23231']
return bookingCol.aggregate( [ { '$lookup': { "from": "tb_milestone", "localField": "bookingNo", "foreignField": "bookingNo", "as": "milestone_docs" }, }, { '$project': { 'bookingNo': 1, 'origin': 1, 'mawbNo': 1, 'status': 1,'_id': 0 }, }, { '$match': { 'status': {'$ne': 'X'}, 'bookingNo': {'$in': ['321312','2323213']}, 'milestone_docs.status': 'RCF' } } ] )
MongoDB Map Reduce :https://www.runoob.com/mongodb/mongodb-map-reduce.html
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
MapReduce 命令
以下是MapReduce的基本语法:
>db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
- map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
- reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
- out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
- sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
- limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
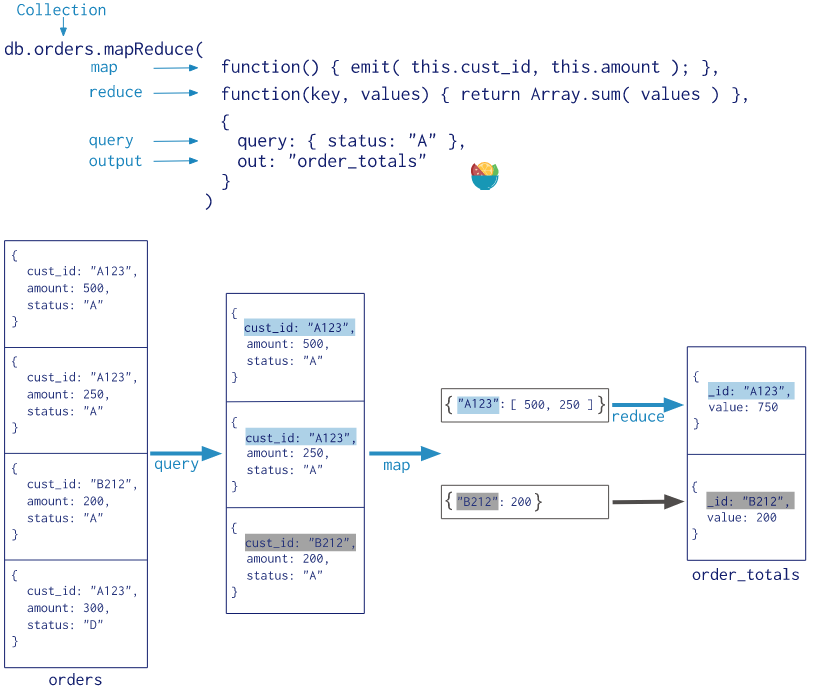
以下实例在集合 orders 中查找 status:"A" 的数据,并根据 cust_id 来分组,并计算 amount 的总和。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
2018-08-27 Sql语句在线转java bean https://www.bejson.com/othertools/sql2pojo/