向MIPS架构移植软件之大小端问题
向MIPS架构移植软件之大小端问题
来源 https://tupelo-shen.github.io/2020/10/23/MIPS%E6%9E%B6%E6%9E%84%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A38-%E5%90%91MIPS%E7%A7%BB%E6%A4%8D%E8%BD%AF%E4%BB%B6%E4%B9%8B%E5%A4%A7%E5%B0%8F%E7%AB%AF%E6%A8%A1%E5%BC%8F/
站在巨人的肩膀上,才能看得更远。
If I have seen further, it is by standing on the shoulders of giants.
牛顿
科学巨匠尚且如此,何况芸芸众生呢。我们不可能每个软件都从头开始搞起。大部分时候,我们都是利用已有的软件,不管是应用软件,还是操作系统。所以,对于MIPS架构来说,完全可以把在其它架构上运行的软件拿来为其所用。
但是,这是一个说简单也简单,说复杂也复杂的工作。为什么这么说呢?如果你要采用的软件,其可移植性比较好的话,可能只需要使用支持MIPS架构的编译器重新编译一遍就可以了;如果程序只是为特定的硬件平台编写的话(大部分嵌入式软件都是如此),可能处处是坑。而像Linux系统,在编写应用或者系统软件的时候,一般都会考虑可移植性。所以说,基于Linux的软件一般都可以直接编译使用。但是,像现在流行的一些实时操作系统,比如、μC/OS、Free-RTOS、RT-Thread或其它一些基于微内核的系统,它们的程序一般不通用,需要修改才能在其它平台上运行。
而且,越往底层越难移植,几乎所有嵌入式系统上的驱动程序都不能直接使用。而且,嵌入式系统软件通常好几年才会发生一次重大设计更新,所以,如果坚持考虑软硬件上的接口兼容并不合理,尤其是考虑到成本效益的时候。
本文就是总结一些在移植代码或者编写代码时,应该需要特别关注的一些点。
虽说本文主要以MIPS架构为主线进行讲解,但是其中的一些思想和方法,对其它架构同样适用。我们应该学会举一反三,灵活运用。
1 MIPS架构移植软件时常见的问题
以下是一些比较常见的问题:
-
大小端
计算机的世界分为大端(
big-endian)和小端(little-endian)两个阵营。为了二者兼容,MIPS架构一般都可以配置到底使用大端还是小端模式。所以,我们应该彻底理解这个问题,不要在这个问题上栽跟头。 -
内存布局和对齐
大部分时候,我们可以假定C声明的数据结构在内存中的布局是不可移植的。比如,使用C的结构体表示从输入文件或者网络上接收的数据的时候。还有,对于指针或者union型数据,通过不同方法引用的时候,也会存在风险。但是,内存布局还与一些其它的约定有关(比如寄存器的使用,参数传递和堆栈等)。
-
管理Cache
对于嵌入式系统来说,大部分时候采用的都是微处理器,可能并没有实现硬件Cache。但是,随着半导体技术的发展,现在的高端工业处理器一般都带有Cache,只是对于系统软件来说是不可见而已(比如,大部分处理器把Cahce可能带有的副作用都由硬件进行处理,软件不需要管理)。但是,大部分MIPS架构的CPU为了保持硬件的简单,而将一些Cache的副作用暴漏给软件,需要软件进行处理。关于这部分内容,我们后面会进行阐述。
-
内存访问序
在大部分的嵌入式或者消费电子产品中,一般都挂载了许多子系统,这些子系统一般通过一条总线,比如PCIe总线、AHB总线、APB总线等进行通信。虽然方便了我们对系统进行扩展,但是也带来了不可预知的问题。比如,CPU和I/O设备之间的信息需要缓存处理,招致不可见的延时;或者它们被拆分成几个数据流,扔到总线上,但是对于到达目的地的顺序却没有保障。关于这部分内容,我们后面会进行阐述。
-
编程语言
对于语言,当然大部分时候使用C语言了。但是,对于MIPS架构来说,有些事情可能使用汇编语言编写更好。讲解这部分内容的时候,主要涉及inline汇编、内存映射I/O寄存器和MIPS架构可能出现的各种缺陷。
2 什么是字节序:WORD、BYTE和BIT
WORD最早是由Danny Cohen在1980年引入计算机科学的。在他的文章中,以其独有的幽默和智慧指出,通信系统分为两大阵营,分别是字节寻址访问和整数寻址访问。
在乔纳森·斯威夫特(Jonathan Swift)的《格列佛游记》(Gulliver’s Travels)中,little-endians派和big-endians派就如何吃一个煮熟的鸡蛋展开了一场战争。斯威夫特讽刺的是18世纪的宗教争端问题,双方都不知道他们的分歧是完全武断的。科恩的笑话很受欢迎,这个词也就流传了下来。这个问题不仅仅体现在通信上,对于代码的可移植性也有影响。
计算机程序总是在处理不同类型的数据序列:迭代字符串中的字符,数组中的WORD类型元素,以及二进制表示的BIT位。C程序员普遍认为,所有这些变量以字节为单位在内存中顺序排列的-比如,memcpy()函数能够复制任何数据,不论什么数据类型。而且,使用C语言编写的I/O系统也将I/O操作以字节进行建模,你才能够使用read()和write()之类的函数读写包含任何数据类型的内存块。
这样,一个计算机写数据,另一个计算机读数据。那么,我们不禁想,第二台计算机是如何理解第一台计算所写的数据的呢?
另外,我们不止一次地被提醒,要小心数据填充和对齐。因为这对于数据搬运会产生很大的影响。比如说,因为填充的原因,想要完整准确地传递float型数据就变得很难,所以,浮点数据存在精度问题。但是,我们期望至少能够正确表述整形数据,而”字节序”就是个拦路虎。比如说,一个32位整型数,用16进制进行表示为0x12345678,而读进来却为0x78563412,发生了字节交换。想要理解为什么,我们需要追溯一下字节序的发展历史。
2.1 位、字节、字和整形
我们知道一个32位的int型数据,是由32个比特位组成的,它们每一位都有自己的意义,就像我们熟悉的10进制那样,每一位分别表示个、十、百、千、…以此类推,对于二进制,bit0代表1,bit1代表2,bit3代表4,bit4代表8,…。对于一个可以按字节访问的内存来说,32位整数占据4个字节。如何从比特位的视角表述整形数,有两种选择:一派,将低有效位(LS)放在前,也就是存储在内存的低地址里;而另一派,将高有效位(MS)放在前。科恩将其分别称为小端和大端。最早的时候,DEC的微型计算机是小端,而IBM的大型机是大端。彼时,两个阵营互不妥协。
有一个细节需要特殊提一下,大小端字节序的问题只有能够按字节访问的时候才会有。1960年代之前的电脑都是按照WORD大小进行组织:包括指令,整型数和内存宽度都是WORD大小。所以,不存在字节序的大小端问题。
我们在读写10进制数据的时候,习惯于从左到右,高有效位在左,低有效位在右。BYTE最早引入计算机,是为了方便将CHAR型字符打包成WORD,然后进行数据的交互。1970年代,一位IBM的老工程师花费了大量的时间,研究大量的内存dump列表,每个WORD大小的数据代表一组字符。这样看起来,使用小端字节序没有必要。大端字节序更有利于使用和阅读。但是,将数字的高有效位写在左端,字节顺序也是自左向右增加,这样和从右到左对bit位进行编号的行为不一致。于是,IBM将一个高有效位标记为bit0。看起来如下图所示:
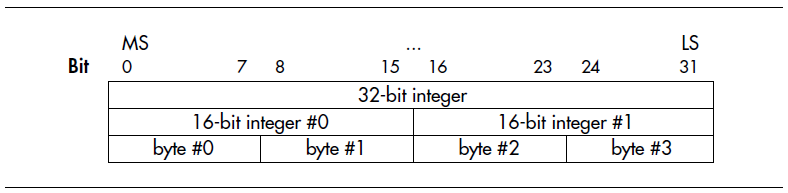
但是,根据数据的算术意义对bit位进行编号更自然,也就是说,标记为N的bit位,其算术意义就是2^N。这样,就可以把bit0-7存储在字节0中。显然,这种方式就变成了小端模式。显然,这种方式不利于阅读,但是对于习惯于将内存看成是一个字节型的大数组的人来说,就会非常有意义。
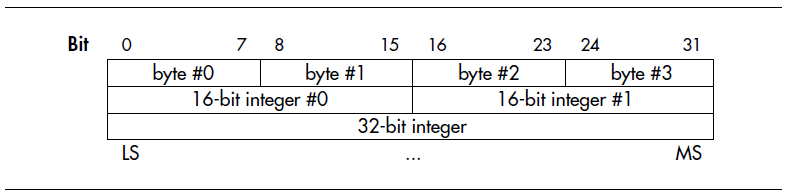
通过上面的讨论,可以看出,两幅图中,内容都是相同的,只是最高有效位(MS)和最低有效位(LS)进行了互换,当然,bit位的顺序也发生了互换。IBM主导的大端模式,看到的是被分割成字节的WORD;而Intel主导的小端模式看到的是构建WORD的字节序列。毋庸置疑的是,对于不同的人群,它们都非常有用。它们都有自己的优点,就看你怎么选择了。
让我们回到上面的问题。假设一个16进制类型的数据0x12345678,二进制形式为00010010 00110100 01010110 01111000。如果传送给一个具有相反字节序的系统,你肯定期望看到所有的位是相反的:00011110 01101010 00101100 01001000,16进制为0x1E6A2C48。但是,为什么我们上边却说是0x78563412。
的确,在某些情况下完全可以实现上面的位反转:有些通讯链路先发送最高有效位,另一些则先发送最低有效位。但是,在上世纪70年代,更多地使用8位的字节作为计算机内部和计算机通信系统的基本单元。通常,通信系统使用字节构建消息流,由硬件决定哪一位首先被发送出去。
与此同时,每个微控制器系统都使用8位宽的外设控制器(更宽的控制器是为高端设备预留的),这些外设一般都使用8位端口,bit0-bit7,最高有效位是bit7。对此,没有任何争议,每个字节都采用小端字节序。从那以后,一直保持到现在。
而早期的微处理器系统,都是8位CPU,使用8位总线和一个8位的内存进行通信,所以,根本不存在字节序问题。Intel的8086是一个16位的小端系统。当摩托罗拉在1978年左右推出68000微处理器时,他们推崇IBM的大型机架构。不管是处于对IBM的敬仰,还是为了区别于Intel,他们选择了大端模式。但是,它们无法违反8位外设控制器的习惯,于是,每一个8位的摩托罗拉的外设通过交错的数据总线与68000进行连接。这就是,我们为什么说收到0x78563412数据的原因。于是,68000家族系列使用如下图所示的字节序:
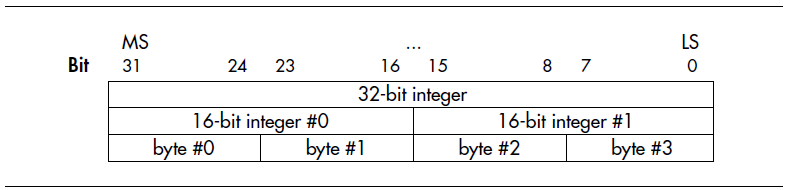
68000及其后继产品被大多数成功的UNIX服务器和工作站所使用(尤其是SUN公司)。所以,当MIPS架构和其它RISC指令集架构的CPU在1980年代出现时,他们的设计者为了兼容大小端字节序,都设置了配置选项,可以自由选择使用大小端模式。但是,从68000开始,大端模式就指68000风格的大端字节序,其bit位和字节序相反。当你配置MIPS架构CPU为大端模式时,就如上图所示。
选择不同的大小端模式,可能会影响你阅读CPU和寄存器手册。尤其是对于位操作指令,向左移动和向右移动的区别,位操作指令的参数位置等。
通过上面的讨论,我们知道,大小端字节序对于软硬件的影响分为2类:软件的话,比如移植软件和数据通信;硬件的话,如不兼容子系统和总线之间的连接问题。对此,我们分别进行阐述。
3 软件和字节序
对于软件来说,字节序的定义如下:如果CPU或编译器中,一个整型数的最低寻址字节存储的是最低8位,那么就是小端模式;如果最低寻址字节存储的是最高8位,那么就是大端模式。可以通过下面的代码,验证你的CPU是大端还是小端模式。
#include <stdio.h>
main ()
{
union {
int as_int;
short as_short[2];
char as_char[4];
} either;
either.as_int = 0x12345678;
if (sizeof(int) == 4 && either.as_char[0] == 0x78) {
printf ("Little endian\n");
}
else if (sizeof(int) == 4 && either.as_char[0] == 0x12) {
printf ("Big endian\n");
}
else {
printf ("Confused\n");
}
}
严格说来,软件字节序是编译器工具链的一个属性。只要你愿意,可以产生任何字节序的代码。但是对于像MIPS架构这样的可字节寻址的CPU,内部使用32位算术运算,这会导致硬件效率降低;因此,我们接下来,主要谈论的是CPU的字节序。
当然了,内存地址空间中字节布局的问题也同样适用于其它数据类型。比如浮点数据类型,文本字符串,甚至是机器指令的32位操作码。对于这些非整型数据类型来说,算术意义根本没有存在的价值。
当软件要处理的数据类型大于硬件能够管理的数据类型时,字节序问题完全就成为软件的一种约定了,可以是任何字节序。当然了,最好还是与硬件本身的约定保持一致。
3.1 可移植性和字节序
只要应用程序不从外界获取数据,或避免使用不同的整型数据类型访问同一个数据块(如上面我们故意那样做的那样),CPU的字节序对你的应用程序就是不可见的。也就是说,你的代码是可移植的。
但是,应用程序不可能接受这些限制。你可能必须处理外部发送过来的数据,或者需要把硬件寄存器映射到内存上,便于访问。不管哪种应用,你都需要准确知道编译器如何访问内存。
这好像没有什么,但是经验告诉我们,字节序是最容易混淆的,因为很难描述这个问题。大小端两种方案起源于勾画和描述数据的不同方式,它们在各自的视角都没有什么问题。
如上所述,大端模式通常围绕WORD来组织其数据结构。如下图1所示。虽然按照IBM约定,将最高有效位(MS)标记为位0更为美观,但是,现在已经不在那样做了。


而小端模式更主要从软件方面抽象数据结构,将计算机的内存视为一个字节类型的数组。如上图2所示。小端模式没有将数据看作是数值型的,所以倾向于把低有效位存放在左边。
所以,软件大小端的字节序问题,归根结底就是一个习惯的问题:究竟习惯于从左到右,还是从右到左对bit位进行编号。每个人的习惯不同,这也是字节序问题容易混淆的根源。
4 硬件和字节序
前面我们已经看见,CPU内部的字节序问题,只有在能够同时提供WORD字长的数据和按字节访问的内存系统中才会出现。同样,当系统与具有多字节宽度的总线进行连接时,也会存在字节序问题。
当通过总线传输多个字节数据时,数据中的每个字节都有自己的存储地址。如果总线上传输数据的低地址字节,被编为低编号,那么这条总线就是小端模式;反之,如果使用高编号对数据的低地址字节进行编号,那么就是大端模式总线。
可字节寻址的CPU,在它们传送数据的时候会声明是大端还是小端字节序。英特尔和DEC的CPU是小端模式;摩托罗拉680x0和IBM的CPU是大端模式。MIPS架构CPU可以支持大小端两种模式,需要上电时进行配置。许多其它RISC指令集架构的CPU也都遵循MIPS架构的思路,选择大小端可配置的方式:这在使用一个新的CPU替换已经存在的系统时是个优点,如果旧系统遵循小端模式,新的CPU也配置为小端模式;反之亦然。
假设硬件工程师按照比特位的顺序把系统串联在一起,这本身没有什么错。但是,如果你的系统包含总线、CPU和外设,而它们的字节序不匹配时,会很麻烦。只能哪种方式更简单一些,使用哪一种。
-
位顺序一致/字节序被打乱
很显然,设计者可以按照位顺序的方式,把两条总线接到一起。这样,每个WORD的位顺序没有变化,但是位编号和字节是不同的,那么,两边内存中的字节序列也是不同的。
任何小于总线宽度或没有按照总线宽度进行排列的数据,在总线上传输时,都会被破坏顺序,并按照总线宽度发生字节交换。这看上去要比软件问题严重。软件产生错误字节序的数据,根据数据类型仍能找到,因为没有破坏数据类型的边界;这是这个数据已经没有意义。但是,硬件却会打乱数据类型的边界(除非,数据恰好以总线宽度对其)。
这儿有一个问题。如果通过总线接口进行传输的数据,总是按照WORD大小对齐,然后按照比特位的编号进行接线,那么就会隐藏大小端字节序的问题。也就避免了软件再对其进行转换。但是,硬件工程师很难知道,设计的系统上的接口以后会传输什么数据。所以,应该小心应对这个问题。
-
字节地址一致/整数被打乱
设计者可以按字节地址进行连线,也就是保证两端的相同字节存储在相同的地址。这样,字节通道内的比特位的顺序必然不一致。至少,整个系统可以把数据看作字节数组,只是数组元素的比特位是相反的。
对于大多数情况下,字节地址乱序副作用更明显。所以,我们推荐使用“字节地址一致”方法进行连线。因为在处理、传输数据时,程序员更希望将内存看作为字节数组。其它数据类型一般也是据此构建的。
不幸的是,有时候使用位编号一致,好像在原理图上更为自然。想要说服硬件工程师修改他们的原理图是一件很难的事情哦。这个大家都懂的😀!!!
并不是每个系统内的连接都很重要。假设,我们有一个32位地址范围内的内存系统,直接与CPU相连。CPU的接口可以不包含字节寻址,只需将地址总线上的低2位置0即可。与此相反的是,大部分CPU使能字节存取。在内部,CPU将每个字节通道和内存中的字节地址相关联。我们可以想象得到,无论连线如何,内存系统都不受影响。内存按照任何一种连线被写入,只要再按照同样的方式读取出来就可以。虽然,大部分情况下,内存一般都继承了CPU的大小端模式。但是,这个连接无关于字节序1。
但是,上面的例子是个陷阱,千万不要以为简单的CPU/RAM架构不存在大小端的字节序问题。下面我们列举在构建内存系统时不能忽略CPU字节序问题的情况:
-
如果你的系统使用的是预先烧录到ROM内存中的固件时,硬件地址总线和字节数据通道与系统的连接方式必须与ROM编程时假设的方式是一致的。通俗的讲,现在是ROM,程序数据是预先写入到ROM中的,也就是大小端方式固定了,那么它与系统总线的连接必须是一致的大小端方式。尤其是对于指令来说,这很重要,因为它决定了取出的指令中操作码的字节序。
-
使用DMA直接传输数据到内存中时,字节序就很重要。
-
当CPU没有使能字节地址寻址,而使用一个字节大小的码表示该字节在WORD地址中的位置时(这在MIPS架构CPU中很常见),那么硬件必须能够正确解析CPU想要读写的是哪个字节,也就是必须知道CPU正在使用的大小端模式。这个需要仔细阅读芯片手册。
下面我们将分析硬件工程师如何构建一个字节地址一致的系统。
4.1 建立连接字节序不一致的总线
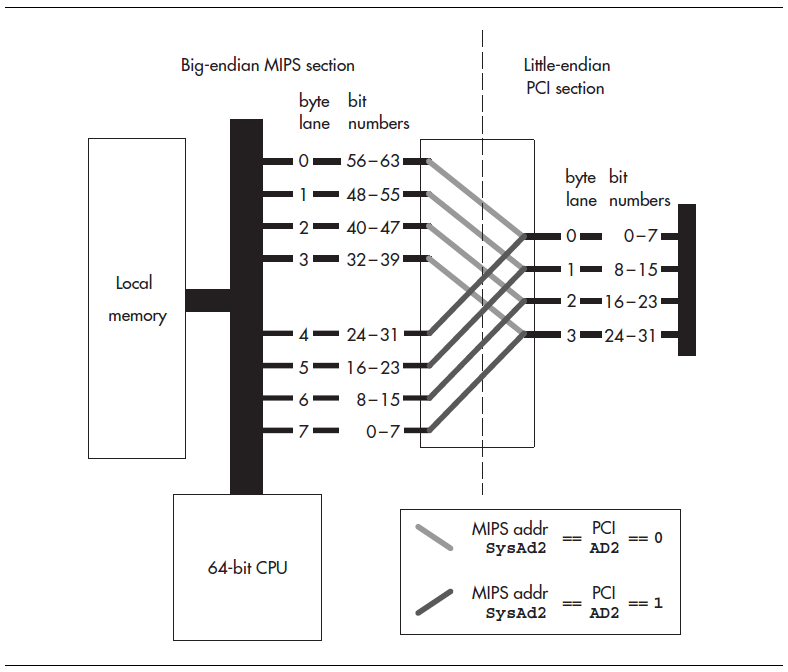
假设我们有一个64位的CPU,配置为大端模式,将其与一个小端模式的32位PCI总线相连。下图展示了如何连线,以获得CPU和PCI两端看上去都一致的字节地址。
因为CPU是64位,而PCI总线是32位,所以,根据32位WORD宽的地址中的bit2,将64位总线分成两组,与32位PCI总线进行连接。比特位1和比特位0是每个WORD中的其中一个字节地址。CPU的64位总线是大端模式,高编号的位携带的是低地址,这个从字节通道的编号能够看出来。
4.2 建立字节序可配置的连接
上面的方法毕竟是固定的,一旦完成硬件设计就无法改动了。如果我们想要实现一个类似于总线开关设备,用它进行切换,让CPU既可以工作在大端模式,也可以工作在小端模式,如下图所示。
在这儿,我们称这个总线开关设备为字节通道交换器,而不是字节交换器。主要是想强调这个设备不管是开,还是关,都不会影响传输数据的大小。有了这个设备,我们就可以根据需要,认为关闭或者打开它,存取字节一致或者不一致的数据。
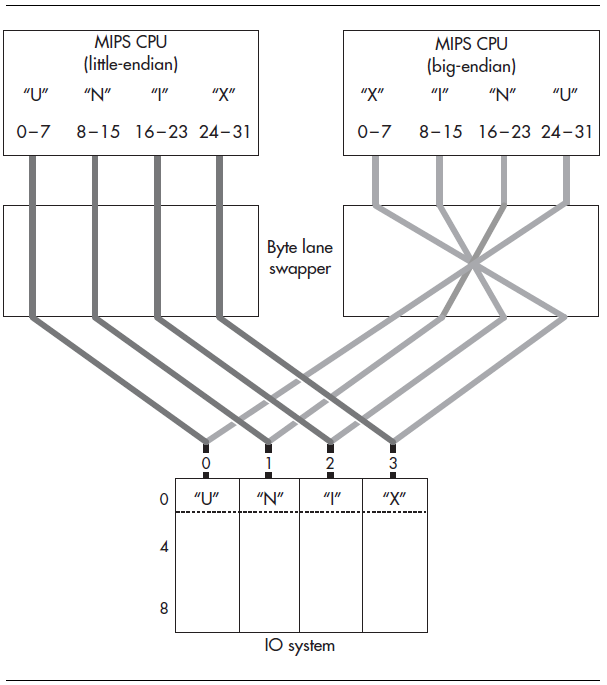
字节通道交换器所做的就是无论你的CPU设置为大端模式还是小端模式,CPU和不匹配的外设总线或设备之间,数据总能按照想要的序列进行交换。
正常情况下,在CPU和内存之间不需要添加字节通道交换器。因为它们之间的连接本身就是快速且是并联的,添加字节通道交换器的代价比较昂贵。
综上所述,我们将CPU和内存视为一个整体。然后,在CPU和系统其它部分之间增加一个字节通道交换器。这样,无论CPU配置成什么工作模式,字节序就不再是一个问题了。
4.3 对字节序问题的一些错误认知
每当遇到大小端的字节序问题时,我们的第一反应往往是:这个问题可能是一个硬件缺陷。然而,事情往往没有那么简单。比如下面的2个例子,有时候必须需要编程人员的干预。
-
可配置的I/O控制器:
一些新的I/O设备和系统控制器本身就可以自由配置成大端或者小端模式。想要使用这些特性之前,必须仔细阅读芯片手册。尤其是,可以使用跳线帽进行选择时,而不是固定在某种工作模式下时。
这些特性一般在大块数据传输时使用,其余的字节序问题,比如访问位编码的设备寄存器或者共享内存的控制位等问题,留给编程人员进行单独处理。
-
可以根据传输类型进行字节交换的硬件:
如果你正在尝试设计一些字节交换硬件,意图解决整个问题。可以肯定的告诉你,这条路行不通。软件问题没有任何一个可以一劳永逸的硬件解决方案。比如,一个实际系统中的许多传输都是以数据高速缓存作为单位的。他们可能包含不同大小和对其格式的任意数据组合。可能无法知道数据的边界在哪里,也就意味着没有办法确定所需的字节交换配置。
有条件的字节交换除了增加混乱之外,没有什么多大用处。除了无条件的字节通道交换器之外,任何做法都是用来骗人的东西。
5 在MIPS架构上编写支持任意字节序的软件
你可能会想,我是否可以写一个正确运行在MIPS CPU上的程序,不论它被配置为大端模式,还是小端模式。或者编写一个可以运行在任意配置的板子上的驱动程序。很遗憾,这是一个很棘手的问题。最多也就是在引导程序中的某一小部分里可以这样写。下面是一些指导原则。
MIPS架构指令集中能够实现字节加载的指令如下所示:
lbu t0, 1(zero)
上面这条语句的作用是:取字节地址1处的字节,加载到寄存器t0的最低有效位上(0-7),其余部分填充0。这条指令本身描述是与字节序无关的。但是,大端模式下,数据将从CPU数据总线的位16-23进行读取;小端模式下,将从CPU数据总线的位8-15位进行加载。
MIPS CPU内部,有个硬件单元负责把有效的字节从它们各自的字节通道中,加载到内存寄存器的正确位置上。这个负责操纵数据加载的硬件逻辑能够适应所有的加载大小、地址和对齐方式的组合(包括load/store和左右移位指令等)。
正是这个特性使得MIPS CPU能够配置大小端工作模式。当你重新配置MIPS CPU的字节序时,正是改变了这个操纵数据加载的硬件逻辑单元的行为。
为了配合CPU大小端的可配置性,大部分的MIPS工具链都能够在编译flag中添加一个选项,编译产生任何字节序的代码。
如果你设置了MIPS架构的CPU与系统不匹配的字节序,将会发生一些预料不到的事情。比如,软件可能会迅速崩溃,因为对于字节的读取可能会获取垃圾数据。在重新配置CPU的同时,最好重新配置解码CPU的时钟逻辑[^5]。
我们这儿选择位编号一致的方法,而不是字节地址一致的方法。之所以选择位编号一致的方法是因为,MIPS的指令都是按位进行编码的(32位指令集宽度)。这样的话,存放代码指令的ROM,不管是大端模式的CPU,还是小端模式的CPU都有意义。从而,可以共享这段引导程序。这不是完美无缺的,如果ROM包含非32位对齐的任何数据都将会被打乱。许多年前,Algorithmics公司的MIPS主板的ROM中,就使用了这种适应大小端模式的代码检测,主ROM程序是否与CPU的大小端模式匹配,如果不匹配,就会打印下面的帮助信息:
Emergency - wrong endianness configured.
单词Emergency被存放在一个C字符串中。现在,我们已经能够理解为什么ROM程序的开头,往往会有下面这么几行奇幻的代码了。
.align 4
.ascii "remEcneg\000\000\000y"
上面定义了一个文本字符串Emergency,包含标准C的终止符null和2个字节的填充。下图以大端模式为视角,展示了这个单词在内存中的布局。如果使用了小端模式,就会打印上面的帮助信息。
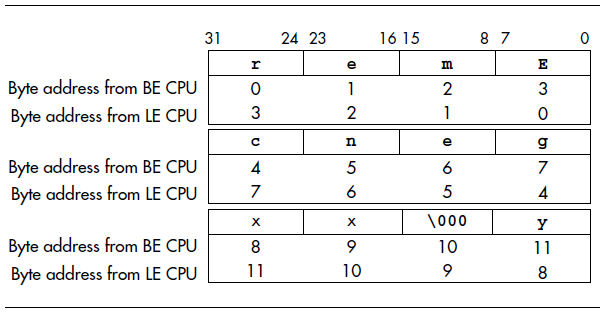
通过上面的示例,我们可以看出编写适应大小端模式的代码是可能的。但是,要注意当把代码加载到ROM中时,加载工具应该区分大端模式和小端模式,确保能够把数据写入到正确的位置上。
6 可移植性和大小端无关代码
如果确实需要编写支持大小端模式的代码,用于方便移植(笔者在移植函数库libmath的时候,就看到这样的代码)。可以按照下面的代码模板进行编写。通常,大部分的MIPS工具链定义BYTE_ORDER作为字节序选择的宏选择开关。
#if BYTE_ORDER == BIG_ENDIAN
/* 大端模式版本代码... */
#else
/* 小端模式版本代码... */
#endif
如果确实需要,你可以选择使用上面的模板编写不同的分支,分别处理大端模式和小端模式的代码。但是,还是尽量编写与字节序无关的代码,CPU处于哪种模式下,就编写哪种模式下的代码。
所有从外部数据源或设备接收数据的引用都有潜在的字节序问题。但是,根据系统的布线方式,你能够生成双向工作的代码。在不同的字节序之间接线只有两种方式:一种保持字节地址不变,另一种保持位编号不变。在系统特定范围内访问具体的外设寄存器,字节序可以保持与二者之一保持一致。
如果你的外设通常被映射为字节地址兼容,那么你应该按照字节操作进行编程。如果为了效率或者处于不得已,想要一次传输多个字节,你需要编写根据字节序进行打包和解包的代码。
如果你的外设与32位WORD兼容,通常按照总线宽度进行读写操作。那就是32位或64位的读写操作。
-
熟悉硬件的工程师可能意识到了一个更为通用的原则:可写存储器的一个性质就是,不管连接到它的地址和数据总线怎么排列,都能继续工作。一个具体数据存储在哪里并不重要,重要的是你给出相同的读取地址时,能够正确读取之前写入的数据即可。 ↩
大端小端问题总结
来源 https://www.jianshu.com/p/205057c6918a
一、简介大小端定义
- 大端模式
所谓的大端模式,是指数据的低位(就是权值较小的后面那几位)保存在内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放; - 小端模式
所谓的小端模式,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
例子:在内存中双字0x12345678(DWORD)的存储方式
内存地址
4000 4001 4002 4003
LE 78 56 34 12
BE 12 34 56 78
二、如何知道使用的CPU的大小端
对于一个数0x1122使用Little Endian方式时,低字节存储0x22,高字节存储0x11
而使用Big Endian方式时, 低字节存储0x11, 高字节存储0x22。
我们可以通过强制类型转换来判断CPU的大小端;
程序例子:
OTP_UINT8 test_data8 =0;
OTP_UINT16 test_data16 =0;
test_data16 = 0x1122;
x0 = ((OTP_UINT8*)&test_data16)[0]; /*低地址单元*/
x1 = ((OTP_UINT8*)&test_data16)[1]; /*高地址单元*/
test_data8=*( (unsigned char*) &test_data16 );
if(test_data8 ==0x11)
{
printf(" CPU = big-endian 大端"SCRN_NEWLINE);
}
else
{
printf(" CPU = little-endian 小端"SCRN_NEWLINE);
}
通过上例可以知道强制指针类型转换操作在大端系统和小端系统得出的内容是不一致的;
小端模式下:
OTP_UINT32型数据 = 0x12345678 , 指针类型强制转换后,OTP_UINT8为:0x78
OTP_UINT32型数据 = 0x12345678 , 指针类型强制转换后,OTP_UINT16为:0x5678
大端模式下:
OTP_UINT32型数据 = 0x12345678 , 指针类型强制转换后,OTP_UINT8为:0x12
OTP_UINT32型数据 = 0x12345678 , 指针类型强制转换后,OTP_UINT16为:0x1234
三、在大端、小端系统中对各类运算符操作的影响
-
通过编程测试,发现只有强制类型转换运算符在大小端系统中会得到不同的结果;
数据的强制转换操作无影响;
test_data8 =(OTP_UINT8)test_data32;
test_data16 =(OTP_UINT16)test_data32;
test_data32 =(OTP_UINT32)test_data8;
指针的强制转换操作有影响
test_data8=( (unsigned char) &test_data32 );
test_data16=( (unsigned short) &test_data32 ); -
其它的位运算符如:>> 、<< 、|、;算术运算符等都没有影响;
-
使用移位操作的特殊应用:
a_test_data8[0]=0x12;
a_test_data8[1]=0x34;
a_test_data8[2]=0x56;
a_test_data8[3]=0x78;test_data32 =(OTP_UINT32)((a_test_data8[0]<<24)+ (a_test_data8[1]<<16)
+(a_test_data8[2]<<8)+(a_test_data8[3]));
test_data32的结果位0x12345678;
这里在进行赋值操作前已经认为a_test_data8[0]中为高字节,a_test_data8[3]为低字节,上面的左移赋值操作在大端和小端的系统中得出的值是相同的;若在进行赋值操作前已经认为a_test_data8[0]中为低字节,a_test_data8[3]为高字节则操作为test_data32 =(OTP_UINT32)((a_test_data8[3]<<24)+ (a_test_data8[2]<<16)
+(a_test_data8[1]<<8)+(a_test_data8[0])); -
使用移位操作的特殊应用:
test_data32 = 0x12345678;a_test_data8[0] =(test_data32>>24);
a_test_data8[1] =(test_data32>>16);
a_test_data8[2] =(test_data32>>8);
a_test_data8[3] =(test_data32);
上述操作完成后,a_test_data8[0]中为高字节=0x12,a_test_data8[3]=0x78 低字节;大端和小端的系统中是相同的;
四、字节序的转换方法
不同端模式的处理器进行数据传递时必须要考虑端模式的不同。如进行网络数据传递时,必须要考虑端模式的转换。在我们ROPT平台库里提供了转换函数:
#define ntohs(n) /*16位数据类型网络字节顺序到主机字节顺序的转换*/
#define htons(n) /*16位数据类型主机字节顺序到网络字节顺序的转换*/
#define ntohl(n) /*32位数据类型网络字节顺序到主机字节顺序的转换*/
#define htonl(n) /*32位数据类型主机字节顺序到网络字节顺序的转换*/
其中互联网使用的网络字节顺序采用大端模式进行编址,而主机字节顺序根据处理器的不同而不同,如PowerPC处理器使用大端模式,而Spear 310处理器使用小端模式。
大端模式处理器的字节序到网络字节序不需要转换,此时htons(n)=n,htonl = n;而小端模式处理器的字节序到网络字节必须要进行转换;
#define htonl(x) ((((x) & 0x000000ff) << 24) | \
(((x) & 0x0000ff00) << 8) | \
(((x) & 0x00ff0000) >> 8) | \
(((x) & 0xff000000) >> 24))
#define htons(x) ((((x) & 0x00ff) << 8) | \
(((x) & 0xff00) >> 8))
所以在使用小端模式的CPU进行开发工作时,一旦涉及到数据的网络字节序传递,一定需要注意将整型、长整型进行网络字节序转换,否则会导致接收端数据错误;
五、在大端、小端系统中的比特序说明
一个采用大端模式的32位处理器,其寄存器的最高位msb(most significant bit)定义为0,最低位lsb(lease significant bit)定义为31;而小端模式的32位处理器,将其寄存器的最高位定义为31,低位地址定义为0。
例:按位域定义结构:
typedef union
{
OTP_UINT32 Byte;
struct
{
OTP_UINT32 a_bit0 :1;
OTP_UINT32 b_bit1 :1;
OTP_UINT32 c_bit2_3:2;
OTP_UINT32 d_bit4_13:10;
OTP_UINT32 e_bit14_21:8;
OTP_UINT32 f_bit22_29:8;
OTP_UINT32 g_bit30:1;
OTP_UINT32 h_bit31:1;
}bits;
}E1SlotCtrl;
E1SlotCtrl g_test_32;
这个共用体会占用4个字节。由于a,b,c,d,e,f,g,h的类型都是OTP_UINT32,所以他们都在以OTP_UINT32为单位的整数上分配bit。根据CPU大小端的不同,这些字节在这4个字节内是分配顺序也是不一样的。
程序中对结构体成员赋值:
g_test_32.bits.a_bit0 =1;
g_test_32.bits.b_bit1 =1;
g_test_32.bits.c_bit2_3 =2;
g_test_32.bits.d_bit4_13 =7;
g_test_32.bits.e_bit14_21 =5;
g_test_32.bits.f_bit22_29 =3;
g_test_32.bits.g_bit30 =0;
g_test_32.bits.h_bit31 =1;
打印的长整型数据如下:
在大端模式下g_test_32.Byte =0xe01c140d;
在小端模式下g_test_32.Byte =0x80c1407b;
具体的数据分配总结:
大端模式下g_test_32.Byte =0xe01c140d
Bit位定义 bit31(lsb) bit0(msb)
二进制码 1 1 1 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 0 1 0 0 0 0 0 0 1 1 0 1
结构成员 a b c d e f g h
结构成员值 1 1 2 7 5 3 0 1
小端模式下g_test_32.Byte =0x80c1407b;
Bit位定义 bit31(msb) bit0(lsb)
二进制码 1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 1 1 1 0 1 1
结构成员 h g f e d c b a
结构成员值 1 0 3 5 7 2 1 1
所以直接使用位域的方式定义结构体是依赖于使用CPU的大小端模式的,当进行不同端系统移植的时候,必须重新定义这些结构体。
正确的位域定义方式:
typedef union
{
OTP_UINT32 Byte;
struct
{
#ifdef OTP_LITTLE_ENDIAN
OTP_UINT32 a_bit0 :1;
OTP_UINT32 b_bit1 :1;
OTP_UINT32 c_bit2_3:2;
OTP_UINT32 d_bit4_13:10;
OTP_UINT32 e_bit14_21:8;
OTP_UINT32 f_bit22_29:8;
OTP_UINT32 g_bit30:1;
OTP_UINT32 h_bit31:1;
#else
OTP_UINT32 h_bit31:1;
OTP_UINT32 g_bit30:1;
OTP_UINT32 f_bit22_29:8;
OTP_UINT32 e_bit14_21:8;
OTP_UINT32 d_bit4_13:10;
OTP_UINT32 c_bit2_3:2;
OTP_UINT32 b_bit1 :1;
OTP_UINT32 a_bit0 :1;
#endif
}bits;
}E1SlotCtrl;
六、大端向小端系统移植代码时需要注意内容
- 有使用位域定义的结构,必须区分大小端进行定义;
- 需要进行网络字节序传递的整型、长整型数据必须进行网络字节序转换;
- 使用指针强制转换操作的需要根据端模式进行重新处理;
- 注意一些特殊的移位操作,见三.3、三.4;
七.附件:测试代码
typedef union
{
OTP_UINT32 Byte;
struct
{
#if 1 /*#ifdef OTP_LITTLE_ENDIAN*/
OTP_UINT32 a_bit0 :1;
OTP_UINT32 b_bit1 :1;
OTP_UINT32 c_bit2_3:2;
OTP_UINT32 d_bit4_13:10;
OTP_UINT32 e_bit14_21:8;
OTP_UINT32 f_bit22_29:8;
OTP_UINT32 g_bit30:1;
OTP_UINT32 h_bit31:1;
#else
OTP_UINT32 h_bit31:1;
OTP_UINT32 g_bit30:1;
OTP_UINT32 f_bit22_29:8;
OTP_UINT32 e_bit14_21:8;
OTP_UINT32 d_bit4_13:10;
OTP_UINT32 c_bit2_3:2;
OTP_UINT32 b_bit1 :1;
OTP_UINT32 a_bit0 :1;
#endif #endif
}bits;
}E1SlotCtrl;
/*CPU big little endian test*/
void test_cpu_big_little_endian()
{
OTP_UINT16 test_data16 =0;
OTP_UINT8 x0 = 0;
OTP_UINT8 x1 = 0;
OTP_UINT8 x2 = 0;
OTP_UINT8 x3 = 0;
OTP_UINT8 test_data8=0;
OTP_UINT8 a_test_data8[4];
OTP_UINT32 test_data32 =0;
OTP_UINT32 test0_data32 =0;
E1SlotCtrl g_test_32;
test_data16 = 0x1122;
x0 = ((OTP_UINT8*)&test_data16)[0]; /*低地址单元*/
x1 = ((OTP_UINT8*)&test_data16)[1]; /*高地址单元*/
test_data8=*( (unsigned char*) &test_data16 );
printf(SCRN_NEWLINE);
printf(SCRN_NEWLINE);
if(test_data8 ==0x11)
{
printf(" CPU = big-endian 大端"SCRN_NEWLINE);
}
else
{
printf(" CPU = little-endian 小端"SCRN_NEWLINE);
}
printf(SCRN_NEWLINE);
printf(" test_data16 =0x1122 ,强制转换OTP_UINT8为:%x"SCRN_NEWLINE,test_data8);
printf(" 低地址单元 test_data16[0]:0x%x"SCRN_NEWLINE, x0);
printf(" 高地址单元 test_data16[1]:0x%x"SCRN_NEWLINE, x1);
test_data32 = 0x12345678;
x0 = ((OTP_UINT8*)&test_data32)[0]; /*低地址单元*/
x1 = ((OTP_UINT8*)&test_data32)[1]; /*低中地址单元*/
x2 = ((OTP_UINT8*)&test_data32)[2]; /*高中地址单元*/
x3 = ((OTP_UINT8*)&test_data32)[3]; /*高地址单元*/
test_data8=*