

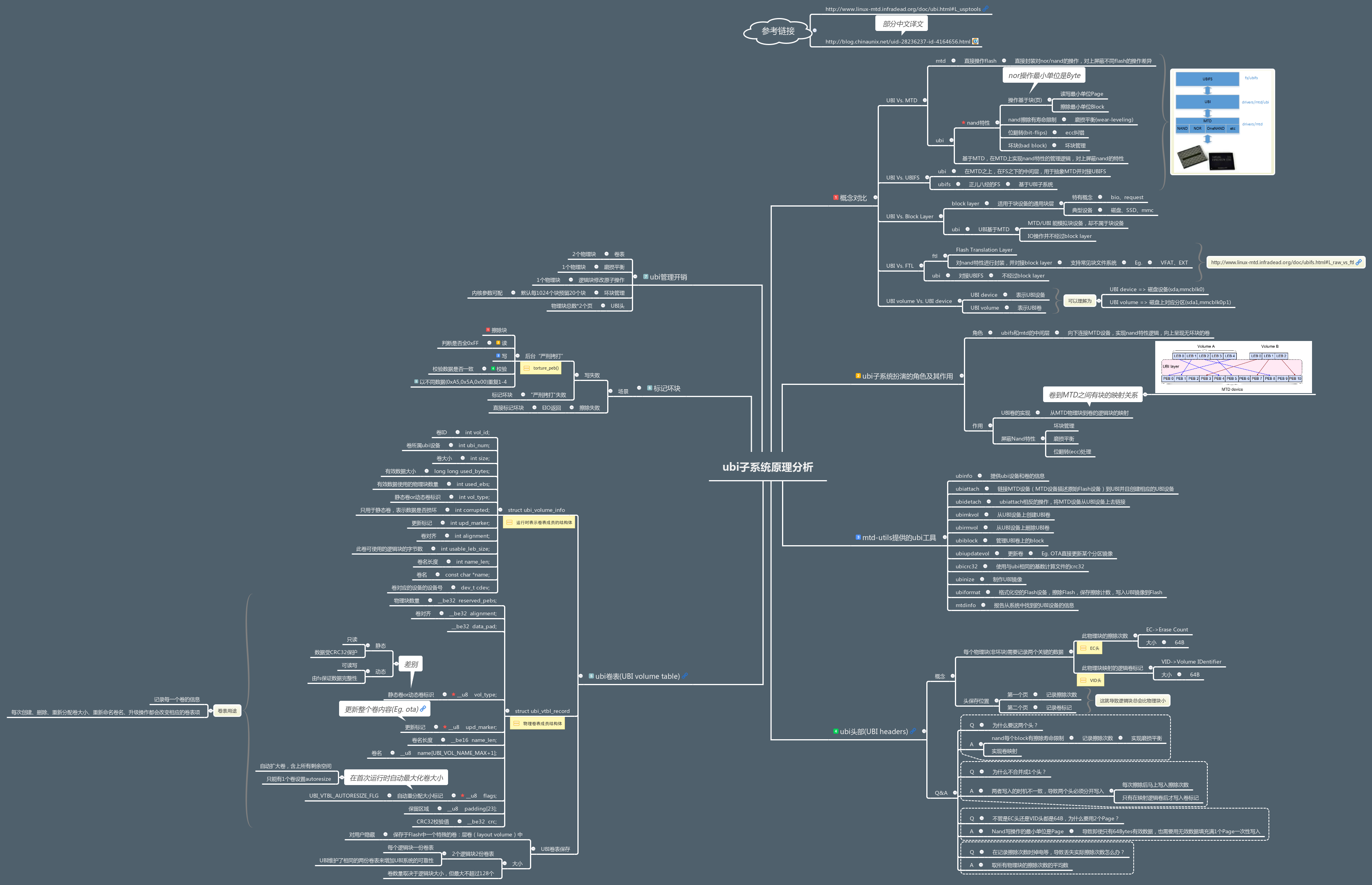
ubi子系统原理分析
ubi子系统原理分析
来源 https://www.cnblogs.com/gmpy/p/10874475.html
综述#
关于ubi子系统,早已有比较正式的介绍,也提供非常形象的介绍ubi子系统ppt
国内的前辈 alloysystem 不辞辛劳为我们提供了部分正式介绍的中文译文,以及找不到原文的转载译文
感谢这些资料让我迅速入门ubi,进而整理出这博文
此博文是对上文的总结以及中文译文的补充
概念对比#
UBI Vs. MTD#

上图非常形象地描述了从Flash到UBIFS的各个层次。从上图我们发现,MTD子系统在实际的Flash驱动之上 ,而UBI子系统则在MTD子系统之上。
要对比UBI和MTD的概念,我们不妨问自己一个问题,UBI和MTD两个不同的层次的"使命"分别是什么?
Flash驱动直接操作设备,而MTD在Flash驱动之上,向上呈现统一的操作接口。所以MTD的"使命"是 屏蔽不同Flash的操作差异,向上提供统一的操作接口 。
UBI基于MTD,那么UBI的目的是什么呢? 在MTD上实现nand特性的管理逻辑,向上屏蔽nand的特性 。
nand有什么特性呢?
(下文描述的 Nand驱动,是广义上的操作Nand的集合,包括fs/ubi/mtd的层次,而非纯粹的nand驱动)
1. 操作最小单元为页(Page)/块(Block)
Nand不同于Nor,Nor可以以字节为单位操作Flash,但Nand的读写最小单元是页,擦除最小单元是块。
对常见的1Gbit的spinand而言,其页大小2KBytes,块大小是128K,表示一个块有64个页。
2. 擦除寿命限制
Nand的物理性质决定了其每个块都有擦除寿命的限制,SLC约10W次,MLC约5000次,TLC约1000次。
因此,Nand驱动必须要做到磨损平衡。
所谓磨损平衡,就是尽可能均衡使用每一个块,既不让一个块太大压力,也不让一个块太过空闲。
3. 位翻转(bit-flips)
Nand的物理性质使其可能会在使用、保存过程中出现位翻转的现象。
例如,原始数据为0xFFFC,在存储过程中Flash的数据却变成了0xFFFF。
所以要不在nand内部,要不在nand控制器都会存在ecc校正模块,在位翻转后校正。
然而,ecc并不是万能的,其校正能力有限,所以驱动必须在位翻转数量进一步变多之前把数据搬移到其他块。
萌新可能会有疑问,ecc都已经校正了为什么还要搬移?因为ecc校正的是从Flash中读到内存中的数据,
而不是Flash本身存储的数据,换句话说,此时Flash中的数据依然是错的,如果不搬移,随着翻转的位数量积累,
ecc就校正不了了,此时就相当于永久丢失正确数据了。
4. 存在坏块(Bad Block)
制作工艺和Nand本身的物理性质,导致在出厂和正常使用过程中都会产生坏块。
所谓坏块,就是说这个块已经损坏,不能再用于存储数据,因此Nand驱动需要能自动跳过坏块。
关于SLC/MLC/TLC的比较,可参考这篇博客
UBI Vs. UBIFS#
如果说UBI在MTD之上,在FS之下的中间层,用于抽象MTD屏蔽nand差异,那么ubifs就是正儿八经的文件系统。
ubifs是基于UBI子系统的文件系统,实现文件系统该有的所有基本功能,例如文件的实现,例如日志的实现。
这里需要特别注意的是,ubifs跟jffs/yaffs相比,并不包含nand特性的管理,而是交由ubi来实现。
UBI Vs. Block Layer#
Block Layer是适用于常见块设备的通用块层,其特有的概念有bio、request、电梯算法等,其典型的设备有磁盘、SSD、mmc等。
而ubi基于mtd,虽然能模拟块设备,从本质上来讲其并不是块设备。跟踪UBIFS的IO操作,发现其IO操作并不经过通用块设备层。
UBI Vs. FTL#
FTL(Flash Translation Layer)是一个"黑盒子",其跟UBI非常像,都是对nand特性进行封装。
按我的理解,UBI跟FTL的目标不同,导致其实现上会有差异。UBI屏蔽nand特性是为了对接UBIFS,而FTL则是为了对接Block Layer。例如MMC其实也是封装起来的Nand,只不过在MMC内部实现了FTL,经过FTL的转换就能以块设备层的方法直接操作Nand,就能在mmc上格式化常见的块文件系统,例如EXT、VFAT等。
UBI Volume Vs. UBI Device#
在UBI中还有两个概念,分别是UBI卷(UBI Volume)和UBI设备(UBI Device)。这两个概念,我们可以这么理解:
UBI设备 相当于 磁盘设备(sda,mmcblk0)
UBI卷 相当于 磁盘上对应分区(sda1,mmcblk0p1)
换句话说,UBI设备是在MTD设备上创建出来的设备,而UBI卷则是从UBI设备上划分出来的分区, 从设备节点名(ubi0)和卷名(ubi0_3)可以看出端倪。
上面的描述是为了方便理解UBI卷和UBI设备,实际上UBI卷和分区的概念之间还是有差别的。
LEB Vs. PEB#
在UBI子系统中,还有LEB和PEB的概念:
LEB指Logical Erase Block,即逻辑擦除块,简称逻辑块,表示逻辑卷中的一个块
PEB指Physical Erase Block,即物理擦除块,简称物理块,表示物理Nand中的一个块
为什么要划分逻辑块和物理块?从PPT中我们可以发现,物理块和逻辑块存在动态映射关系,且由于UBI头的存在,逻辑块一般会比物理块小2个页。
UBI子系统扮演的角色及其作用#
UBI子系统就是ubifs与mtd之间的中间层,其向下连接MTD设备,实现nand特性的管理逻辑,向上呈现无坏块的卷。
所以UBI子系统的作用,主要包括两点:
1. 屏蔽nand特性(坏块管理、磨损平衡、位翻转)
2. UBI卷的实现
UBI卷的逻辑擦除块(LEB)与物理擦除块(PEB)之间是动态映射的,详细可以看PPT
UBI相关的工具#
ubi的工具集成在包mtd-utils中,分别有以下工具及其作用
| 工具 | 作用 |
|---|---|
| ubinfo | 提供ubi设备和卷的信息 |
| ubiattach | 链接MTD设备到UBI并且创建相应的UBI设备 |
| ubidetach | ubiattach相反的操作,将MTD设备从UBI设备上去链接 |
| ubimkvol | 从UBI设备上创建UBI卷 |
| ubirmvol | 从UBI设备上删除UBI卷 |
| ubiblock | 管理UBI卷上的block |
| ubiupdatevol | 更新卷,例如OTA直接更新某个分区镜像 |
| ubicrc32 | 使用与ubi相同的基数计算文件的crc32 |
| ubinize | 制作UBI镜像 |
| ubiformat | 格式化空的Flash设备,擦除Flash,保存擦除计数,写入UBI镜像到Flash |
| mtdinfo | 报告从系统中找到的UBI设备的信息 |
UBI头部#
UBI子系统需要往每个物理块的开头写入两个关键数据,这两个关键数据就叫做UBI的头部。
这两个数据分别是 此物理块擦除次数头 和 此物理块的逻辑卷标记头,也分别称为 EC头(Erase Count) 和 VID头(Volume IDentifier)。
不管是EC头还是VID头,都是64Bytes,分别记录与Nand块的第一个页和第二个页。
以Q&A的形式介绍UBI头:
Q:为什么要这两个头?
A:前文有说道,nand每个block有擦除寿命限制,因此需要记录擦除次数,以实现磨损平衡,因此需要EC头。此外,为了实现卷,必须记录卷的逻辑块与物理块之间的映射关系,因此需要VID头。
Q:为什么不合并成1个头?
A:两者写入的时机不一致,导致两个头必须分开写入。EC头在每次擦除后,必须马上写入以避免丢失,而VID头只有在映射卷后才会写入。
Q:不管是EC头还是VID头都是64B,为什么要用2个Page?
A:使用2个Page是对Nand来说的。前文有说过,Nor的读写最小单元是Byte,而Nand的读写最小单元是Page,因此对Nor可以只使用64Bytes,对Nand则必须使用2个Page,就是说,即使只有64Bytes有效数据,也需要用无效数据填充满1个Page一次性写入。
Q:在记录擦除次数时掉电等,导致丢失实际擦除次数怎么办?
A:取所有物理块的擦除次数的平均数
关于UBI头部的详细介绍,可参考链接
UBI卷表(UBI Volume Table)#
UBI子系统有个对用户隐藏的特殊卷,叫层卷(layout volume),用来记录卷表。我们可以把卷表等价于分区表,记录各个卷的信息。卷表大小为2个逻辑擦除块,每个逻辑擦除块记录一份卷表,换句话说,UBI子系统为了保证卷表的可靠性,用2个逻辑记录2分卷标信息。
由于层卷的大小是固定的(2个逻辑块),导致能保存的卷信息受限,所以最大支持的卷数量是随着逻辑块的大小改变而改变的,但最多不超过128个。
卷表中每个卷都保存了什么信息?
struct ubi_vtbl_record {
__be32 reserved_pebs; //物理块数量
__be32 alignment; //卷对齐
__be32 data_pad;
__u8 vol_type; //静态卷or动态卷标识
__u8 upd_marker; //更新标识
__be16 name_len; //卷名长度
__u8 name[UBI_VOL_NAME_MAX+1]; //卷名
__u8 flags; //常用语自动重分配大小标记
__u8 padding[23]; //保留区域
__be32 crc; //卷信息的CRC32校验值
} __packed;
由这个结构体我们可以发现,卷信息是被CRC32保护着的。比较有意思的有两个成员:vol_type 和 flags
动态卷 & 静态卷#
vol_type成员标记了卷的类型,在创建卷时指定,可选动态卷和静态卷。那么什么是动态卷?什么又是静态卷?
动态卷和静态卷是两种卷的类型,静态卷标记此卷只读,于是UBI子系统使用CRC32来校验保护整个卷的数据,动态卷是可读写的卷,数据的完整性由文件系统来保证。
关于静态卷和动态卷的介绍,可参考链接
更新标识#
flags成员常用于标识是否自动重分配大小。怎么样自动充分配大小呢?在首次运行时自动resize卷,让卷大小覆盖所有未使用的逻辑块。
例如Flash大小是128M,在烧录的镜像中分配的所有卷加起来只用了100M,如果有卷被表示为autoresize,那么在首次运行时,那个卷会自动扩大,把剩余的28M囊括在内。
这个功能挺实用的,例如某个方案规划中,除去rootfs、内核等必要空间外,把剩余所有空间尽可能分配给用户数据分区。
在开发过程中加了个应用,导致rootfs卷需要更大的空间,进而需要压缩user_data卷的空间。
如果user_data空间是autoresize的,那么user_data卷的空间就会自动压缩。
再例如旧方案用的是128M的nand,后面升级为256M,即使使用相同的固件,也不用担心多出来的128M浪费掉了,
因为user_data卷自动扩大囊括多出来的128M。
需要注意的是,只允许1个卷设置autoresize标志
关于更新标识更多的介绍,参考链接
坏块标记#
我们知道Nand的物理性质,导致在使用久之后会产生坏块,那么UBI是如何判断好块是否变成了坏块的呢?
有两个场景可能会标识坏块,分别是写失败和擦除失败。擦除失败且返回是EIO,则直接标记坏块。比较有意思的是写失败的判断逻辑。
UBI子系统有后台进程对疑似的坏块进行"严刑拷打"(torturing),有5个步骤:
1. 擦除嫌疑坏块
2. 读取擦除后的值,判断是否都是0xFF(擦除后理应全为0xFF)
3. 写入特定数据
4. 读取并校验写入的数据
5. 以不同的数据模式重复步骤1-4
如果"严刑拷打"出问题,则标记坏块,详细的实现逻辑可参考函数torture_peb()
原文可参考链接
UBI管理开销#
什么是管理开销呢?为了管理Nand的空间,实现磨损平衡、坏块管理等等功能,必须占用一部分空间来存储关键数据,就好像文件系统的元数据。管理占用的空间是不会呈现给用户空间使用的,这空间即为管理的开销。
对Nand来说,UBI管理开销主要包含5个部分:
1. 层卷(卷表) : 占用两个物理块
2. 磨损平衡:占用一个物理块
3. 逻辑块修改原子操作:占用一个物理块
4. 坏块管理:默认每1024个块则预留20个块(内核参数可配:CONFIG_MTD_UBI_BEB_LIMIT)
5. UBI头:(物理块总数*2)个页
坏块管理预留的块数量,也可以理解为最大能容纳多少个坏块;再考虑坏块的存在,管理开销计算公式为:
UBI管理总开销 = 特性开销 + UBI头开销
其中:
坏块预留 = MAX(坏块数量,坏块管理预留数量)
特性开销 = (坏块预留 + 1个磨损平衡开销 + 1个原子操作开销 + 2个层卷开销) * 物理块大小
UBI头开销 = 2 * 页大小 * (含坏块的总块数 - 坏块预留 - 1个磨损平衡开销 + 1个原子操作开销 + 2个层卷开销)
也就是说:
UBI管理总开销 = (坏块预留 + 4) * 物理块大小 + 2 * 页大小 * (含坏块的总块数 - 坏块预留 - 4)
以128M的江波龙的FS35ND01G-S1F1 SPI Nand为例,其规格为:
总大小:128M(1Gbit)
页大小:2K bytes
块大小:128K
块数量:1024
假设是完全无坏块的片子,其管理开销为:
UBI管理开销 = (20 + 4) * 128K + 2 * 2K * (1024 - 20 - 4) = 7072K ≈ 7M
详细参考原文链接
=========== End

