2023-03-19 堆和优先队列
堆和优先队列
1.什么是优先队列?
普通队列和优先队列的比较
- 普通队列:先进先出;后进后出
- 优先队列:出队顺序和入队顺序无关,和优先级相关,优先级高地先出队
优先队列的应用
- 医院排队,VIP客户优先
- Windows任务管理器,系统任务优先
优先队列不同实现方式的时间复杂度

2.堆的基础
二叉堆与二叉树的区别和联系
二叉堆是一棵完全二叉树。
完全二叉树与满二叉树的比较
-
满二叉树和完全二叉树的区别:
对于满二叉树,除最后一层无任何子节点外,每一层上的所有结点都有两个子结点二叉树。
而完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
-
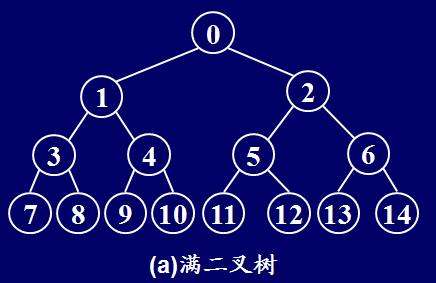
满二叉树定义
定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
-
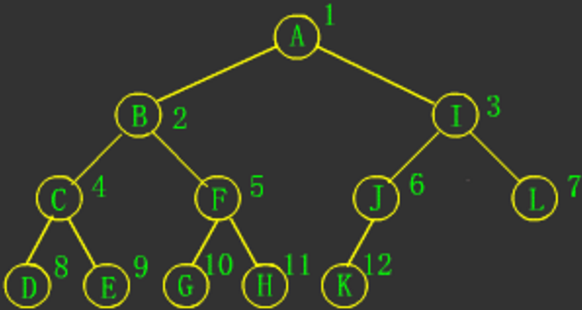
完全二叉树
定义:若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
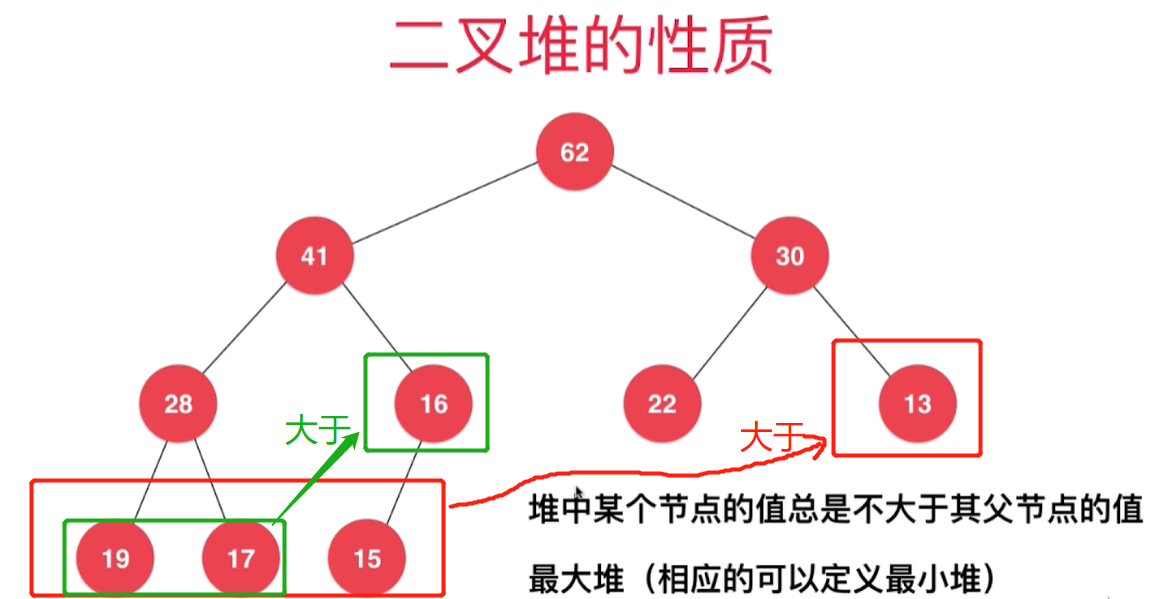
二叉堆的性质
对比:二分搜索树是左节点小于父节点、右节点大于父节点的二叉树
- 每个子节点的值不大于其父亲节点的值--->最大二叉堆,简称最大堆,因为此时根节点肯定是值最大的节点
- 每个子节点的值不小于其父亲节点的值--->最小二叉堆,简称最小堆,因为此时根节点肯定是值最小的节点
注意:最大堆中,第k层的节点不一定比第k-1层的节点小,只要保证比自己的父亲节点小即可
最大堆的表示
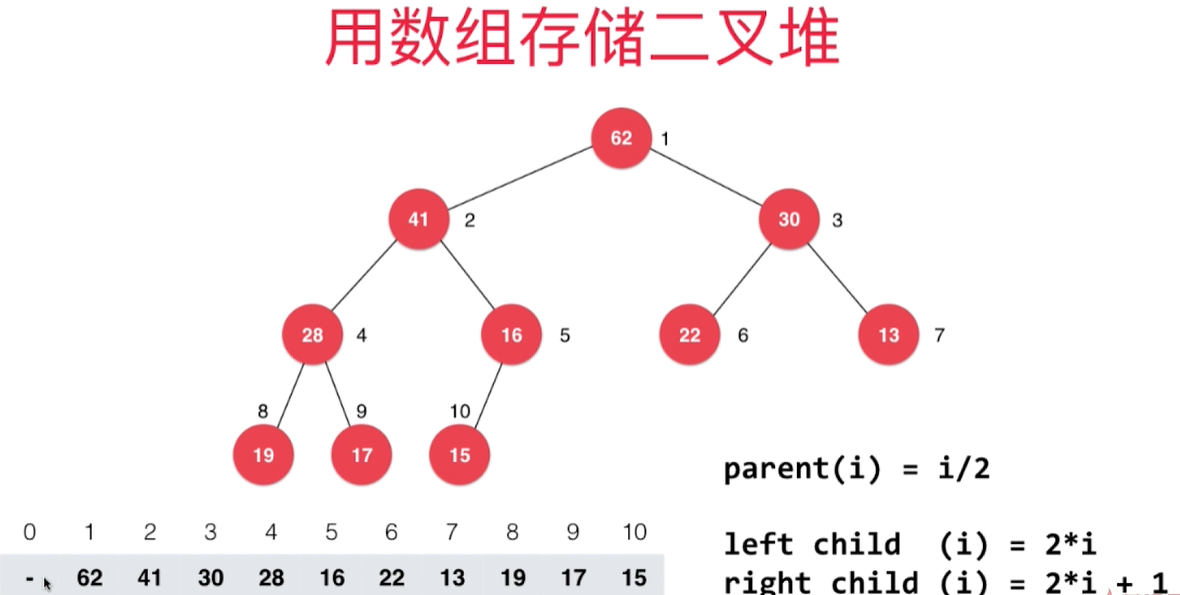
基于数组表示最大堆,注意数组下标是从1开始的
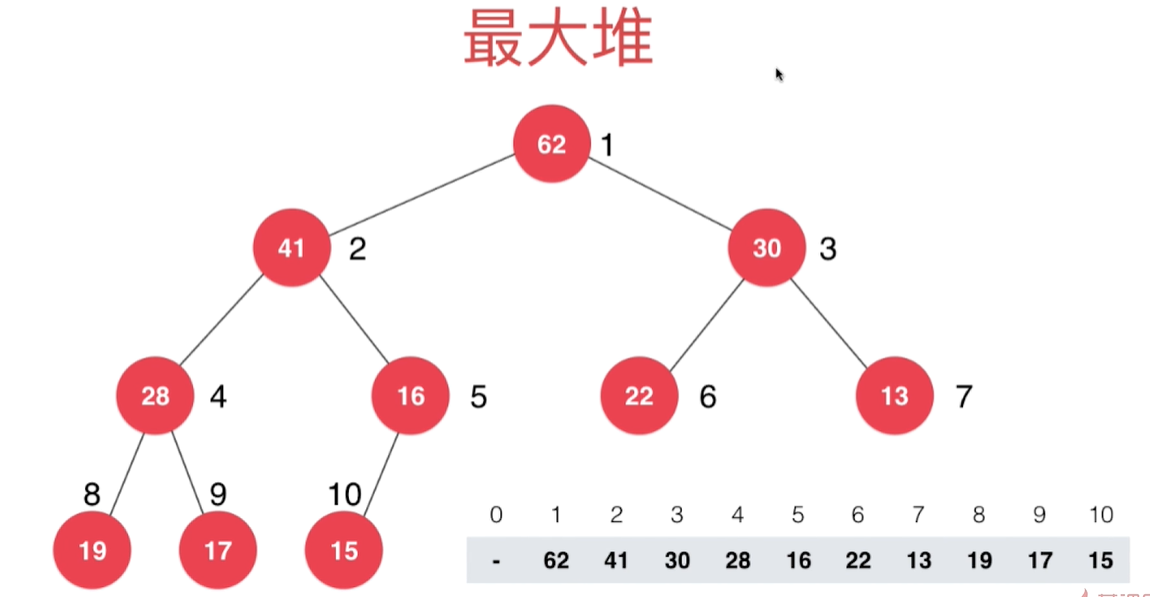
一个节点在数组中的索引为i,则其父亲节点和左右孩子节点在数组中的索引表示如下:
- 父亲节点索引 =
i / 2,注意是整除 - 左孩子的索引 =
2 * i - 右孩子的索引 =
2 * i + 1
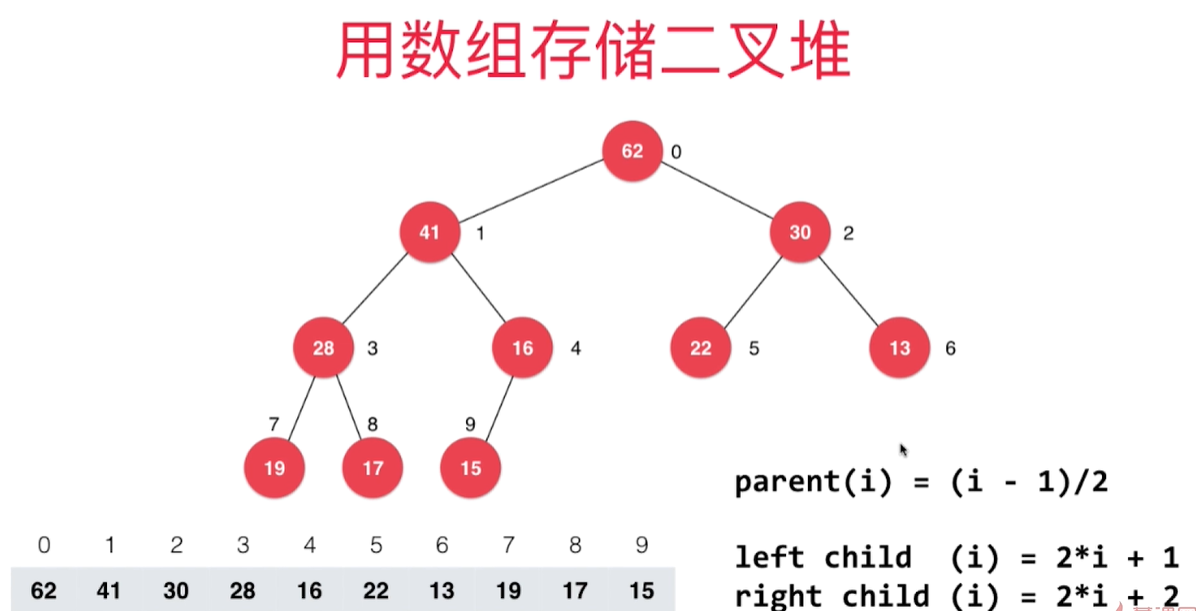
数组下标从0开始存储最大堆时,节点索引公式需要修改如下:
- 父亲节点索引 =
(i - 1) / 2,注意是整除 - 左孩子的索引 =
2 * i + 1 - 右孩子的索引 =
2 * i + 2
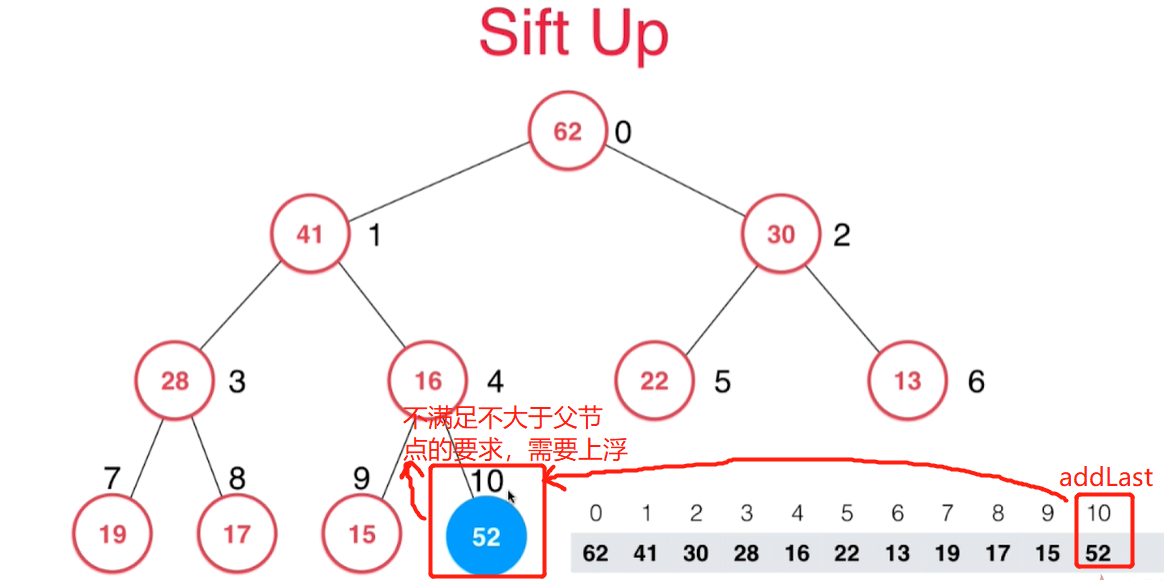
3.向堆中添加元素ShiftUp
- 根据完全二叉树的特点,添加元素需要添加到动态数组的最后,即用addLast添加元素
- 添加完新元素,虽然仍然是完全二叉树,但是已经不满足所有节点都不大于父节点的要求了,所以新加的元素需要上浮ShiftUp
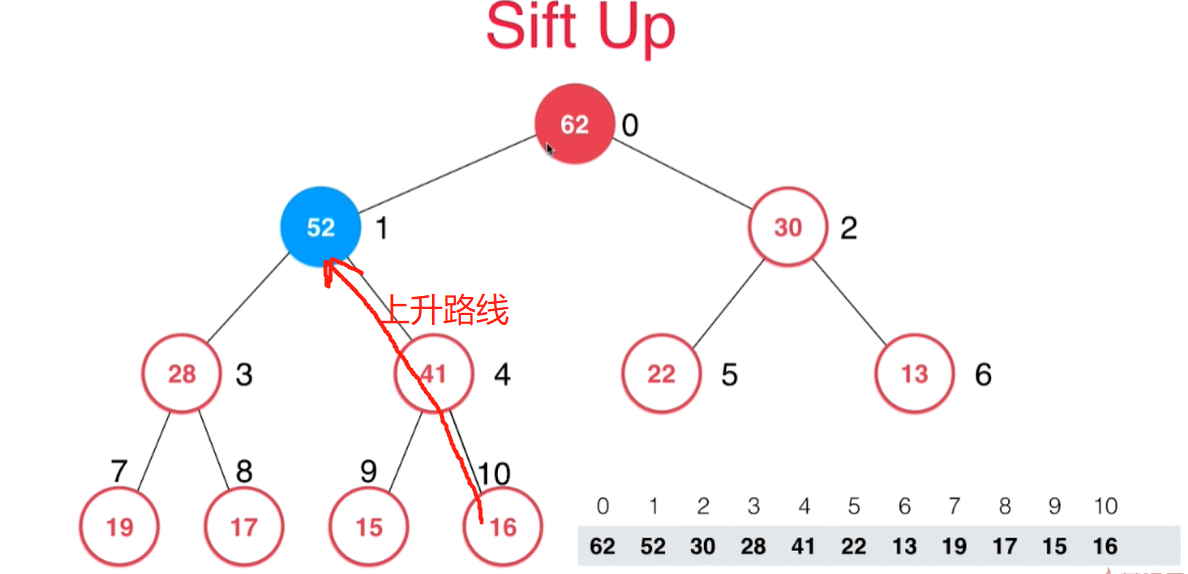
- 不断把新加入的节点和父节点进行比较,如果大于父节点就和父节点进行进行位置对调,一直到满足不大于父节点的要求
/**
* 向堆中添加元素
*/
public void add(E e) {
data.addLast(e);
// 新加入的元素一定在末尾,所以上浮它即可
shiftUp(data.getSize() - 1);
}
/**
* 上浮data中索引为k的元素
*
* @param k 索引
*/
private void shiftUp(int k) {
// 只要k处节点大于其父亲节点,就交换两个节点继续上浮。不断更新k但要保证k>0
while (k > 0 && data.get(k).compareTo(data.get(parent(k))) > 0) {
// k和父亲节点交换
data.swap(k, parent(k));
// 交换会更新k为父亲节点的索引
k = parent(k);
}
}
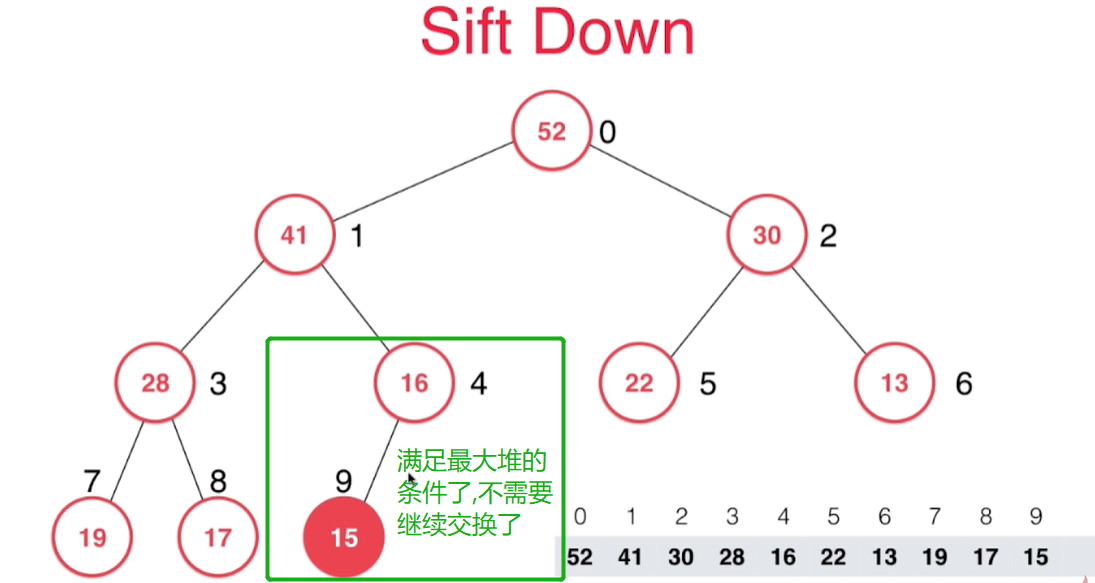
4.从堆中取出最大元素(即根节点)和ShiftDown
- 删除根节点后,把数组中最后一个元素覆盖到根节点处,并把最后一个节点位置清空。
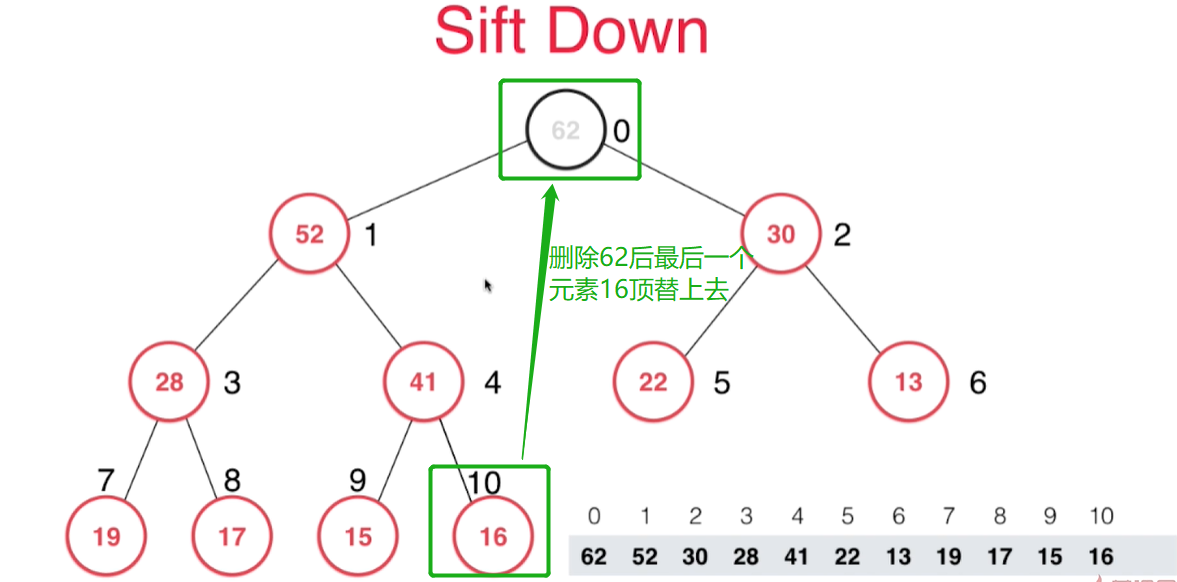
最后位置的元素覆盖根节点后清理最后位置的元素空间
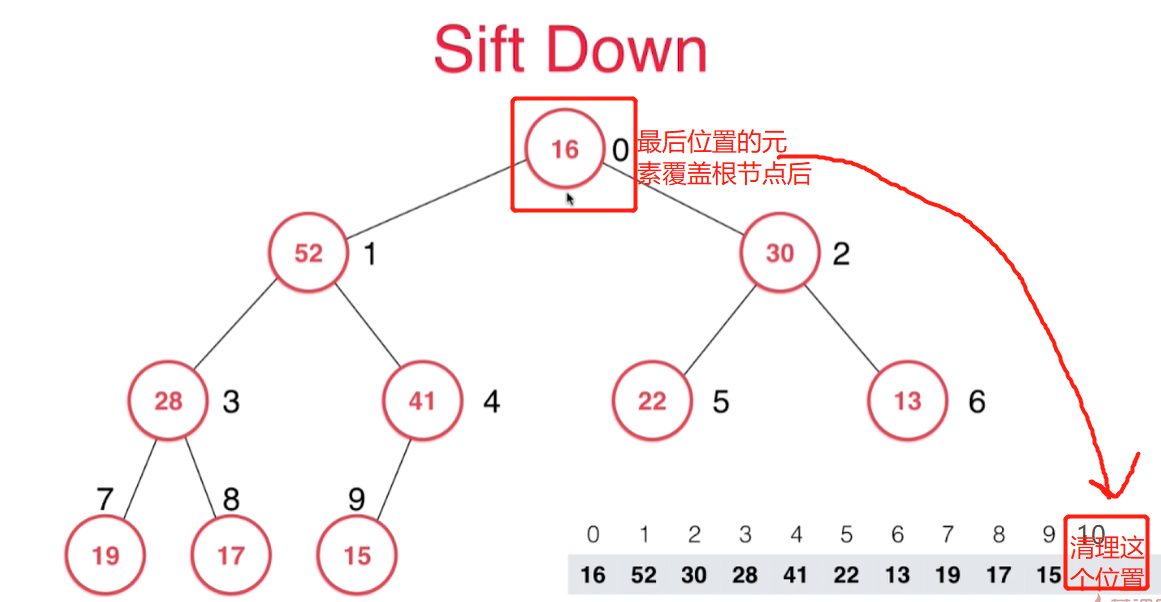
- 然后新的根节点和左右孩子节点进行比较,不大于左右孩子节点地话,就选择较大的孩子节点进行位置交换。如此一直ShiftDown下沉到合适位置
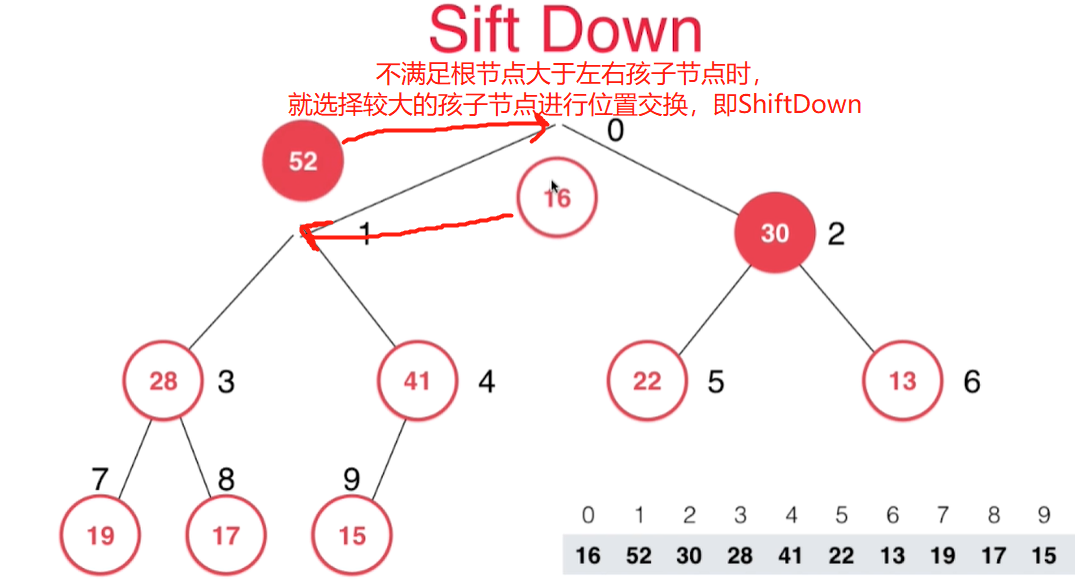
交换一次后还不满足,接着交换
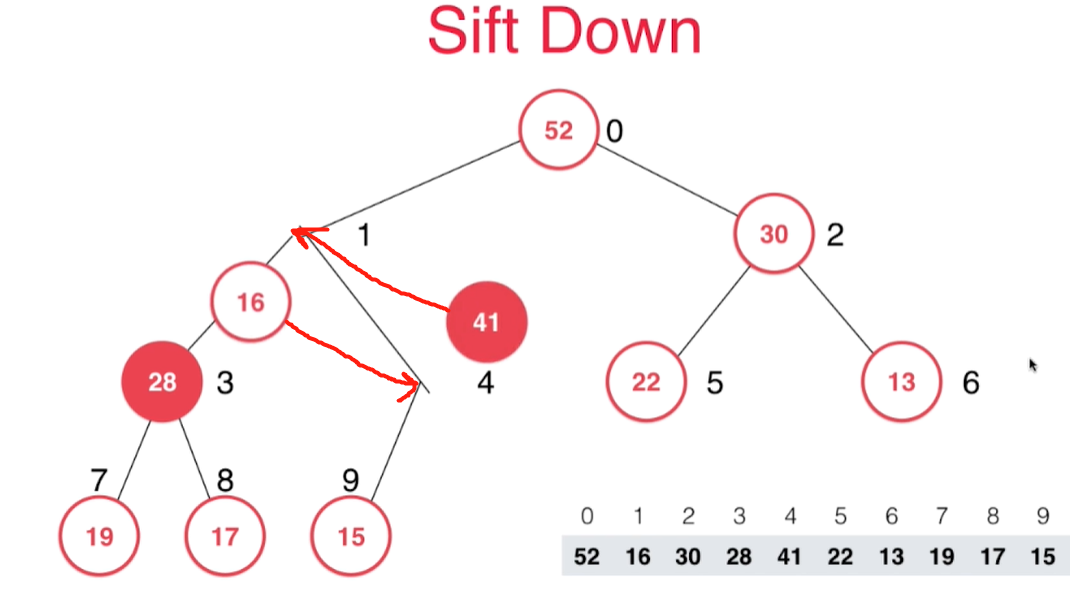
继续下沉到满足最大堆的性质为止
/**
* 取出堆中最大元素
*/
public E popMax() {
E ret = getMax();
// 交换根节点和最后一个节点
data.swap(0, data.getSize() - 1);
// 删除最后一个节点,此时最大值就被正式删除了
data.removeLast();
// 调整新的二叉堆直到满足最大堆的性质
siftDown(0);
// 返回前面暂存的最大节点
return ret;
}
private void siftDown(int k) {
while (leftChild(k) < data.getSize()) {
/* 在此轮循环中,data[k]和data[j]交换位置 */
int j = leftChild(k);
// j+1表右孩子,首先要在数组索引范围内,而且右孩子比左孩子大,则j取左右孩子中的较大值即右孩子的索引
if (j + 1 < data.getSize() && data.get(j + 1).compareTo(data.get(j)) > 0) {
j++;
}
// data[j] 是 leftChild 和 rightChild 中的最大值
if (data.get(k).compareTo(data.get(j)) >= 0) {
break;
}
data.swap(k, j);
k = j;
}
}
add()和popMax()的时间复杂度都是O(logn)
8.5 Replace和Heapify
replace():取出最大元素后,放入一个新的元素到最大元素的位置上(即根节点上)
实现:直接将堆顶元素替换成新元素后shiftDown,一次O(logn)的操作
/**
* 取出堆中的最大元素,并且替换成元素e
*/
public E replace(E e) {
E ret = getMax();
data.set(0, e);
siftDown(0);
return ret;
}
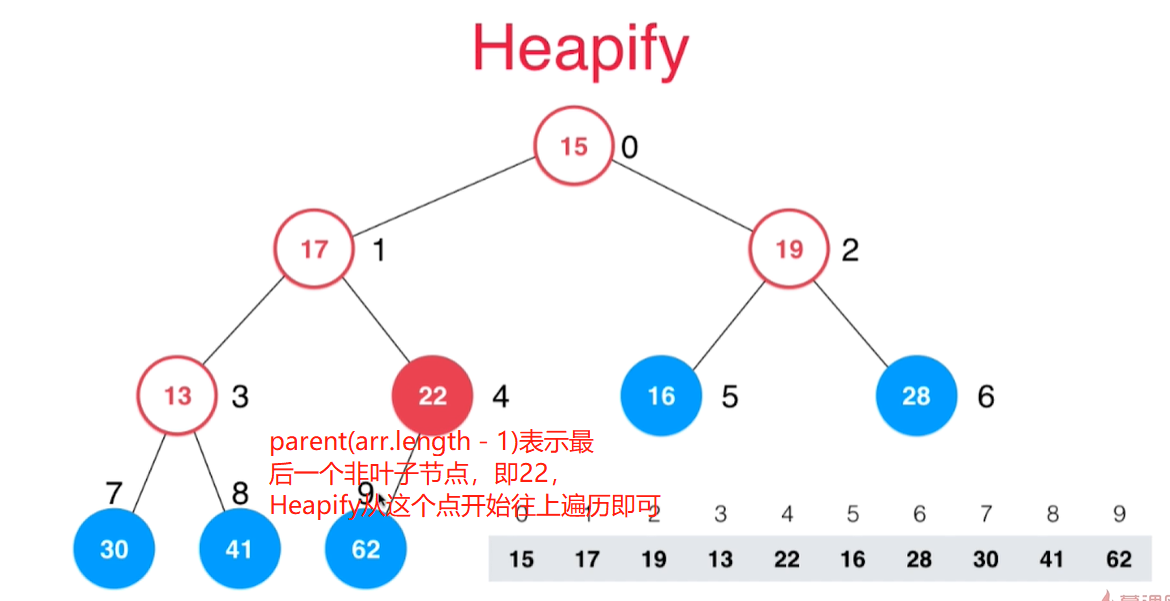
Heapify:将任意数组整理成堆(最大堆or最小堆)
public MaxHeap(E[] arr) {
// 直接根据外面传入的数组对整理成最大堆
data = new Array<>(arr);
heapify();
}
/**
* 将任意数组整理成堆
*/
public void heapify() {
// 初始化的数组,靠上层的节点肯定索引小,所以不断循环进行下沉即可
// parent(arr.length - 1)表示最后一个非叶子节点
// i--的过程就是不断向最大堆上面遍历的过程
int lastNotLeaf = parent(data.getSize() - 1);
for (int i = lastNotLeaf; i >= 0; i--) {
siftDown(i);
}
}
至此我们完成了最大堆和最小堆(仿照最大堆很快就写好啦)
其实最大堆和最小堆中大小的定义可以我们自己实现Comparable接口来定义,所以其实只要一个最大堆就能实现弹出真正想要的最大值或最小值的功能。
6.基于堆的优先队列
优先队列即出队时总是出最大或最小元素的队列,是一种特殊的队列
7.优先队列的常见问题
在N那个元素中选取前M名?M远远小于N
比如在全国高考成绩中(几百万人)选取前100名?
- 排序:时间复杂度是NlogN
- 优先队列:时间复杂度是NlogM,当是百万级别时,显然优先队列性能高地多
维护一个M个元素的优先队列
- 求最大的前M名就用
容量为M的基于最小堆的优先队列- 当优先队列的size没到M时,直接把新元素加入到优先队列
- 当优先队列的size到了M时,把要加入的元素和栈顶元素比较
- 如果新元素比栈顶元素大,就弹出栈顶元素,把新元素加入到优先队列中
- 如果新元素比栈顶元素小,什么都不做
- 求最小的前M名就用
容量为M的基于最大堆的优先队列,每次弹出最大值,遍历N个元素完毕,优先队列中的M的元素就是前M名- 当优先队列的size没到M时,直接把新元素加入到优先队列
- 当优先队列的size到了M时,把要加入的元素和栈顶元素比较
- 如果新元素比栈顶元素小,就弹出栈顶元素,把新元素加入到优先队列中
- 如果新元素比栈顶元素大,什么都不做
- 求最大的前M名就用
实际我们不需要指定最大堆和最小堆,因为我们指定堆的Comparator定制比较规则,从而只用最大堆就能得到我们真正想要的最大值或最小值
实际应用:LeetCode347号问题--求前k个高频元素
import java.util.*;
class Solution {
class PII {
int num, freq;
public PII(int num, int freq) {
this.num = num;
this.freq = freq;
}
}
public int[] topKFrequent(int[] nums, int k) {
Map<Integer, Integer> mapNumFreq = new HashMap<>();
PriorityQueue<PII> pq = new PriorityQueue<>((o1, o2) -> o1.freq - o2.freq);
for (int num : nums) {
if (mapNumFreq.get(num) == null) {
mapNumFreq.put(num, 1);
continue;
}
mapNumFreq.put(num, mapNumFreq.get(num) + 1);
}
for (Integer key : mapNumFreq.keySet()) {
pq.add(new PII(key, mapNumFreq.get(key)));
if (pq.size() > k) pq.remove(); // 维持优先队列长度为k
}
int[] res = new int[k];
int cnt = 0;
while (!pq.isEmpty()) res[cnt++] = pq.remove().num;
return res;
}
}
8.JDK中的优先队列java.util.PriorityQueue
java.util.ArrayDeque进行区分,JDK中优先队列的实现叫java.util.PriorityQueue
PriorityQueue自定义比较器Comparator
PriorityQueue实际上是一个堆(不指定Comparator时默认为最小堆),通过传入自定义的Comparator函数可以实现最大堆
PriorityQueue<Integer> minHeap = new PriorityQueue<Integer>(); //小顶堆,默认容量为11
PriorityQueue<Integer> maxHeap = new PriorityQueue<Integer>(11,new Comparator<Integer>(){ //大顶堆,容量11
@Override
public int compare(Integer i1,Integer i2){
return i2-i1;
}
});
PriorityQueue的常用方法poll(),offer(Object),size(),peek()等。
- 插入和删除方法(offer()、poll()、remove() 、add() 方法)时间复杂度为O(log(n)) ;
- remove(Object) 和 contains(Object) 时间复杂度为O(n);
- 检索方法(peek、element 和 size)时间复杂度为常量。
构造方法
| 构造方法摘要 | 阐述 |
|---|---|
| PriorityQueue() | 使用默认的初始容量(11)创建一个 PriorityQueue,并根据其自然顺序对元素进行排序。 |
| PriorityQueue(Collection c) | 创建包含指定 collection 中元素的 PriorityQueue。 |
| PriorityQueue(int initialCapacity) | 使用指定的初始容量创建一个 PriorityQueue,并根据其自然顺序对元素进行排序。 |
| PriorityQueue(int initialCapacity, Comparator comparator) | 使用指定的初始容量创建一个 PriorityQueue,并根据指定的比较器对元素进行排序。 |
| PriorityQueue(PriorityQueue c) | 创建包含指定优先级队列元素的 PriorityQueue。 |
| PriorityQueue(SortedSet c) | 创建包含指定有序 set 元素的 PriorityQueue。 |
普通方法
| 方法摘要 | 阐述 |
|---|---|
boolean |
add(E e) 将指定的元素插入此优先级队列。 |
void |
clear() 从此优先级队列中移除所有元素。 |
Comparator |
comparator() 返回用来对此队列中的元素进行排序的比较器;如果此队列根据其元素的自然顺序进行排序,则返回 null。 |
boolean |
contains(Object o) 如果此队列包含指定的元素,则返回 true。 |
Iterator |
iterator() 返回在此队列中的元素上进行迭代的迭代器。 |
boolean |
offer(E e) 将指定的元素插入此优先级队列。 |
E |
peek() 获取但不移除此队列的头;如果此队列为空,则返回 null。 |
E |
poll() 获取并移除此队列的头,如果此队列为空,则返回 null。 |
boolean |
remove(Object o) 从此队列中移除指定元素的单个实例(如果存在)。 |
int |
size() 返回此 collection 中的元素数。 |
Object[] |
toArray() 返回一个包含此队列所有元素的数组。 |
T[] |
toArray(T[] a) 返回一个包含此队列所有元素的数组;返回数组的运行时类型是指定数组的类型。 |
从父类集成的方法
- 从类 java.util.AbstractCollection 继承的方法:containsAll, isEmpty, removeAll, retainAll, toString
- 从类 java.lang.Object 继承的方法:clone, equals, finalize, getClass, hashCode, notify, notifyAll, wait, wait, wait
- 从接口 java.util.Collection 继承的方法:containsAll, equals, hashCode, isEmpty, removeAll, retainAll
9.和堆相关的更多话题和广义队列
索引堆:相对高级的数据结构,详见《算法与数据结构C++版》 4.8~4.9
- 1、传统的堆结构只能看到堆首的元素,而不能看到堆中的元素。索引堆弥补了这个缺点
- 2、最小生成树算法和最短路径算法都可以使用索引堆进行优化
广义队列:
- 1、支持队列接口方法的都可以认为是队列;
- 2、栈也可以理解为一个队列;
- 二分搜索树中前序遍历的递归算法和层序遍历算法的逻辑是一致的,区别只在于使用了不同的数据结构栈和队列)
- 图论中的DFS(深度优先遍历,等效前中后序遍历)和BFS(广度优先遍历,等效于层序遍历)的区别实际和上面一样,本质就是栈和队列的区别
LeetCode上优先队列相关的题目
上面题目的题解
347.前K个高频元素
import java.util.*;
class Solution {
class PII {
int num, freq;
public PII(int num, int freq) {
this.num = num;
this.freq = freq;
}
}
public int[] topKFrequent(int[] nums, int k) {
Map<Integer, Integer> mapNumFreq = new HashMap<>();
PriorityQueue<PII> pq = new PriorityQueue<>((o1, o2) -> o1.freq - o2.freq);
for (int num : nums) {
if (mapNumFreq.get(num) == null) {
mapNumFreq.put(num, 1);
continue;
}
mapNumFreq.put(num, mapNumFreq.get(num) + 1);
}
for (Integer key : mapNumFreq.keySet()) {
pq.add(new PII(key, mapNumFreq.get(key)));
if (pq.size() > k) pq.remove(); // 维持优先队列长度为k
}
int[] res = new int[k];
int cnt = 0;
while (!pq.isEmpty()) res[cnt++] = pq.remove().num;
return res;
}
}
215.数组中的第K个最大元素
class Solution {
public int findKthLargest(int[] nums, int k) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
for (int num : nums) {
pq.add(num);
if (pq.size() > k) pq.remove();
}
return pq.remove();
}
}
451.根据字符出现频率排序
class Solution {
class PII {
char c;
int freq;
public PII (char c, int freq) {
this.c = c;
this.freq = freq;
}
}
public String frequencySort(String s) {
char[] cs = s.toCharArray();
Map<Character, Integer> mapCFreq = new HashMap<>();
for (char c : cs) {
if (mapCFreq.get(c) == null) {
mapCFreq.put(c, 1);
continue;
}
mapCFreq.put(c, mapCFreq.get(c) + 1);
}
List<PII> list = new ArrayList<>();
for (char c : mapCFreq.keySet()) list.add(new PII(c, mapCFreq.get(c)));
Collections.sort(list, (o1, o2) -> o2.freq - o1.freq); // 自定义比较器
char[] res = new char[s.length()];
int cnt = 0;
for (PII pii : list) for (int i = 0; i < pii.freq; i++) res[cnt++] = pii.c;
return new String(res);
}
}
前面都是保持大小为k的优先队列,这里是把元素全部都加入到优先队列,取地时候取前k个,道理是一样的。当要求顺序的时候最好选第2种方案
import java.util.*;
class Solution {
class PII {
String word;
int freq;
public PII(String word, int freq) {
this.word = word;
this.freq = freq;
}
}
public List<String> topKFrequent(String[] words, int k) {
Map<String, Integer> mapWordFreq = new HashMap<>();
for (String word : words) {
if (mapWordFreq.get(word) == null) {
mapWordFreq.put(word, 1);
continue;
}
mapWordFreq.put(word, mapWordFreq.get(word) + 1);
}
PriorityQueue<PII> pq = new PriorityQueue<>((o1, o2) -> {
if (o1.freq == o2.freq) return o1.word.compareTo(o2.word); // 频率相同按照字母顺序排序
else return o2.freq - o1.freq;
});
for (String word : mapWordFreq.keySet()) {
pq.add(new PII(word, mapWordFreq.get(word)));
}
List<String> res = new ArrayList<>();
while (res.size() < k) res.add(pq.remove().word);
return res;
}
}
class Solution {
class PII {
int index;
int[] point;
public PII(int index, int[] point) {
this.index = index;
this.point = point;
}
}
public int[][] kClosest(int[][] points, int k) {
Double[] dis = new Double[points.length];
int m = 0;
for (int[] point : points) dis[m++] = Math.sqrt(point[0] * point[0] + point[1] * point[1]);
PriorityQueue<PII> pq = new PriorityQueue<>((o1, o2) -> dis[o1.index].compareTo(dis[o2.index])); // 根据距离比较的优先队列
for (int i = 0; i < points.length; i++) {
pq.add(new PII(i, points[i]));
}
int[][] res = new int[k][2];
int cnt = 0;
while (cnt < k) res[cnt++] = pq.remove().point;
return res;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号