Redis数据结构(三):双向链表和压缩链表
Redis数据结构系列:
常用的操作命令
Redis对外的数据结构中,List是一种常用的数据类型,其在底层存储的数据对应的是双向链表和压缩链表; 在分析这两种链表之前我们先来复习一下Redis中List数据的基本操作。
- lpush
将一个或多个值插入到列表头部。 如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作。 当 key 存在但不是列表类型时,返回一个错误。
LPUSH KEY_NAME VALUE1.. VALUEN
- rpush
Redis Rpush 命令用于将一个或多个值插入到列表的尾部(最右边)。
RPUSH KEY_NAME VALUE1..VALUEN
- lpop
移出并获取列表的第一个元素;
Lpop KEY_NAME
- lrange
返回列表中指定区间内的元素,区间以偏移量START和END指定, 其中 0 表示列表的第一个元素、1 表示列表的第二个元素、-1 表示列表的最后一个元素、-2 表示列表的倒数第二个元素 ,以此类推;
LRANGE KEY_NAME START END
- lrem
根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素
-
- count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
- count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
- count = 0 : 移除表中所有与 VALUE 相等的值。
LREM key count VALUE
- lset
通过索引来设置元素的值
LSET KEY_NAME INDEX VALUE
这里列举的只是最常用的几个真的List的命令,还有一下命令请自行查询,不属于本文章的重点内容;
双向链表
如果Redis列表对象保存的所有字符串对象值的长度有超过64字节或者列表对象保存元素数量大于等于512个的时候,就采用linkedlist(双向链表)格式存储
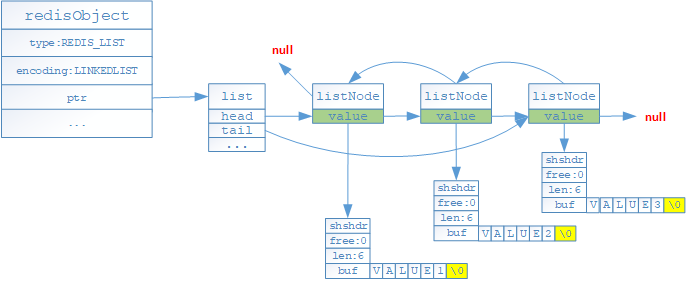
每个节点都是一个listNode,拥有前驱节点,后继节点和值。这就是C语言中的双向链表
typedef struct listNode { struct listNode *prev; //前驱节点,如果是list的头结点,则prev指向NULL struct listNode *next;//后继节点,如果是list尾部结点,则next指向NULL void *value; //万能指针,能够存放任何信息 } listNode;
只要有多个节点就可以组成一个链表了,但是redis再在外面封装了一层,也就是使用adlist.h/list来实现
typedef struct list { listNode *head; //链表头结点指针 listNode *tail; //链表尾结点指针 unsigned long len; //链表长度计数器 //下面的三个函数指针就像类中的成员函数一样 void *(*dup)(void *ptr); //复制链表节点保存的值 void (*free)(void *ptr); //释放链表节点保存的值 int (*match)(void *ptr, void *key); //比较链表节点所保存的节点值和另一个输入的值是否相等 } list;
通过代码可以看出reids中的双向链表增加了链表长度计数器的成员变量,同时封装了保存和释放节点的函数;
压缩链表
ziplist是个经过特殊编码的双向链表,它的设计标是为了提存储效率。ziplist可以用于存储字符串或整数, 其中整数
是按真正的二进制编码的, 并不是编码成字符串序列。 它能以O(1)的时间复杂度在表的两端提供push和pop操作;
当一个哈希键只包含少量键值对,并且每个键值对的键和值要么就是小整数,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做哈希键的底层实现,ziplist结构如下:
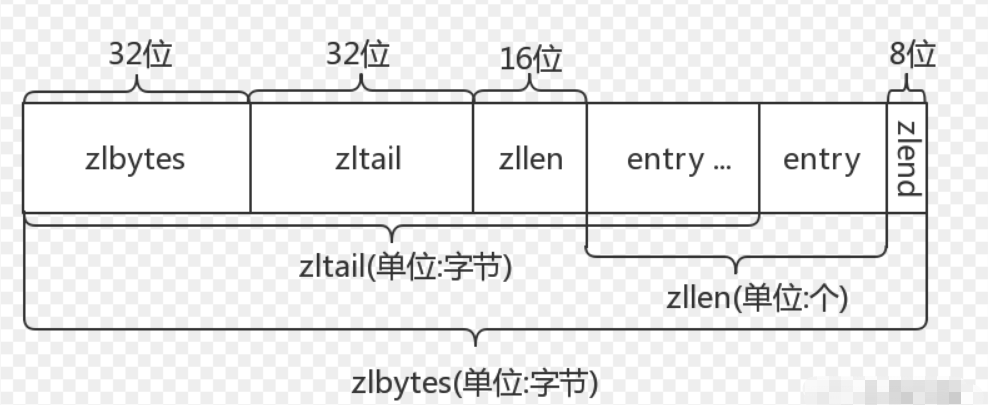
- zlbytes:记录压缩链表占据的字节数,包括自身的4个字节,用于内存重分配
- zltail:尾节点的偏移量,利于实现尾部pop操作
- zllen:节点数,最多2^16-2,若超过范围则必须转换为多个压缩链表
- entry:节点
- zlend:记录压缩链表的尾部,设置为特殊值0xf
ziplist中的节点结构
<prevlen> <encoding> <entry-data>
-
- prevlen:存储上个节点的长度,用以由后往前回到上一个节点
- encoding:节点的content属性所保存数据的类型以及长度
- entry-data:节点数据
参考链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号