
SWIM:一种可扩展的弱一致性的传染风格的进程组成员协议
Abstract
一些分布式的p2p的应用在整个过程中需要知道进程组成员的弱一致性信息。SWIM是一个通用的软件模型,他能够为大规模的进程组提供服务。由于传统心跳协议的不可伸缩性促使了SWIM的出现,因为传统心跳协议要么增加了网络负载,随着成员的规模程2次方增加,要么增加响应时长或者误检测出进程奔溃的频率。本文报导了在大型商用PC集群上的SWIM子系统的设计,实现和性能。
不像传统的心跳协议,SWIM将成员协议的故障检测和成员更新信息传递功能分离开来。进程之间的监控是通过一个有效的p2p的周期随机探测协议。每个进程失败被检测到的预期时间和每个成员的预期消息负载都和成员的规模无关。成员变化信息,比如进程加入,退出和故障都是通过ping消息和确认消息捎带进行传递。这是一个非常健壮和快速传染风格(也是传染的后者流言蜚语类型)的传递。
SWIM系统中的故障检测错误率是通过修改协议允许组成员在宣布它失败之前质疑进程(这允许系统发现和纠正错误的故障检测)来降低的。最后,协议保证一个检测故障的确定的时间边界。
从SWIM原型的实验结果已经给出。我们讨论一个WAN规模的可扩展性设计。
1、Introduction
一些大规模的点对点分布式进程组运行在因特网上,依赖于一个分布式的成员维护子系统。现有的中间件系统使用包含可靠多播和传染风格的信息传播的成员协议。这些协议依次使用在一些应用中,比如分布式数据库,它需要协调最近断开的更新,发布订阅系统和大规模点对点系统。其他出现的应用比如大规模协同游戏和其他协作的分布式应用的性能严重的依赖于使用的成员维护协议的可靠性和可升缩性。
简单的说,一个成员管理协议提供每个进程(“成员”)一个本地维护的组内非故障进程的列表。协议保证成员列表会随着新成员的加入,或者退出(自愿或者通过故障)而被更新。应用直接通过地址空间或者回调接口或者API使用成员列表。应用可以自由的按需使用列表的内容,比如基于gossip的传播协议会使用这个列表来周期性的挑选目标节点来传播消息。
通过几个性能指标来衡量成员子系统的可靠性和可伸缩性。成员变化发生后必须在组内快速的传播。底层网络的异步和不可靠性会导致消息的丢失,导致进程故障的错误检测,因为一个进程丢失消息和一个进程故障时很难区分的。这个误报率必须很低。最后,协议必须是p2p的(不能依赖一个中心服务),并且在网络和进程间有很低的消息和计算负载。
一个超过几十个进程规模的组上的成员协议是很难的,因为它会影响应用的性能。就像在另一篇文章中所述的,在这些组上的性能很差的主要症状是要么增加进程故障检测的误报率,要么增加故障检测的时间。不可伸缩的传统成员维护协议的另一个症状是成2次方的消息负载增长。应用严重依赖成员子系统的例子是虚拟同步多播协议。传统的实现在超过几十个成员规模上会遭受很严重的性能下降和分区。
本文介绍了在SWIM项目中工作成果,实现了一个成员子系统,该系统提供稳定的故障检测时间,稳定的误报率和每个成员的低消息负载,这使得分布式应用可以很好的使用它来进行扩展。我们专注于一个组成员的弱变量,在同一时刻,组内不同成员的成员列表不要求是一致的。通过增强成员子系统可以实现更强的保证,比如可以通过一个有序的周期性检查成员列表进程来提供几户同步的成员列表。然而,与弱一致性不一样,强一致性规范有基本的伸缩限制。
传统的分布式成员算法是通过心跳来实现的。每个进程周期性的发送递增的心跳计数到外部网络。如果一定时间收不到进程的心跳就会认为它已经故障了。然而实际的心跳受到服务扩展性的限制。发送所有的心跳到一个中心节点会导致热点情况。像所有成员发送心跳(通过网络多播或者gossiping)导致网络和组的消息负载随着组规模程2次方增长。如果心跳沿着一个逻辑环发送,当有多个故障时会导致不可预测的故障检测时间。不幸的是,随着组规模的增长,出现多个故障的可能性也在增长。
关于基于心跳的成员维护机制的固有的不可扩展的原因在文档[12]中有进一步讨论。本文提出了一种替代心跳,基于成员间随机探测的分布式随机故障检测协议。数学分析表名随着组规模的上升,协议的属性,(期望的)故障检测时间,误报率和每个成员的消息负载,都独立于组的规模。相对于基于all-to-all的心跳协议,每个成员的故障探测时间或者网络带宽使用(或者误报率)基于线性变量(组规模),这是一个提升。
文档[12]的工作成果表名通用类型的all-to-all心跳协议的可扩展性源于隐式的融合成员探测规范的两个主要功能:1)成员更新传播:传播由于成员加入,离开或者故障引起的成员变更;2)故障检测:检测现有成员是否故障。通过设计一个有效的非多播的故障检测器可以消除多播心跳的开销,并且只有成员变更发生时才使用传播组件。成员传播组件可以通过硬件多播或者传染模式实现。
虽然[12]提出了一个故障检测协议和理论分析,我们的工作着眼于将成员传播组件建成一个工作成员的子系统。此外,最终的协议通过减少误报率和在单个进程的故障检测时间给予更强的确定性保证的机制进行增强。
SWIM系统提供一个成员基础:
- 每个组成语有一个常量的消息负载
- 集群中非故障进程检测到一个进程故障在一个(期望的)常量时间内。
- 一个非故障进程检测到另一个进程故障的本地时间有一个明确的边界(组大小的函数)
- 以传染模式([2,8]中的gossip-style或者epidemic-style)传播成员更新信息,包括故障信息。传递延迟随着成员数增长缓慢(对数)
- 通过在“声明”一个进程故障之前进行“怀疑”的机制来降低误报率
虽然1和2是[12]中故障检测协议的属性,但是3-5是本文的后续工作。运行在PC集群上的SWIM实现原型的实验结果进行了讨论。SWIM协议也可以扩展到工作在广域网(WAN)或者虚拟专用网络(VPN),我们在Section 6进行了简单的介绍。
本文后续组织如下:section 2简要介绍了这个领域的前人研究和来自[12]的可升缩的故障检测协议的基础。Section 3描述了基本的SWIM协议,Section 4改进协议。Section 5展现了实现原型的实验结果。Section 6进行总结。
2. Previous Work
在传统的分布式all-to-all心跳故障检测算法中,每个组成员定期发送一个“心跳”消息(有一个递增计数器)到所有的其他组成员。非故障成员Mj连续几个心跳周期没有收到成员Mi心跳时,会认为Mi已经发生故障。
分布式的心跳机制保证一个故障成员总是会被任何非故障成员检测到(它故障之后一个时间段),因为一个已经奔溃的成员会停止发送心跳消息。然而,这些协议的准确性和可扩展性保证各有差异,这依赖于实际使用的传递心跳的机制。
在最简单的实现中,每个心跳都广播给组中所有其他成员。这会导致每秒θ(n^2/T)的消息负载(尽管使用了IP广播),T是分布式应用要求的故障检测时间。Renesse在[16]中提出了一种通过健壮的gossip-style协议来传播心跳的方式。在这个协议中,每个tgossip时间单元,每个成员进行传播给一些随机的目标,θ(n)-最近从其他成员处接收到心跳计数器的数量。虽然gossiping减少了误报率,但是通常需要一个新的心跳计数,期望上θ[log(n)∙tgossip]时间单元到达任意其他组成员。为了满足应用指定的检测时间,协议每秒产生θ((n^2∙log(n))/∙tgossip)字节的网络负载。使用批量消息来解决这个问题受到UDP包大小的限制,例如50个成员的5B心跳(IP地址和数量)已经产生250B,然而SWIM产生的包最多只有135B,无论组多大。
将心跳通知到所有的组成员会导致成2次方增长的网络负载。这可以问题通过将故障检测操作从成员更新传播中分离开来而避免。
已经有一些层次的成员系统被提出,比如Congress[1]。这属于一类更广泛的方案,该方案中每个进程只心跳到一个子进程组。这类协议需要仔细的配置和维护成员信息流动的轨迹,并且协议的准确性依赖于图的鲁棒性。相比之下,SWIM的设计避免了虚拟图的开销。
SWIM对于上面描述的不伸缩性问题的解决方案基于(a)设计一个分开的故障检测与成员更新信息传递组件,和(b)使用非心跳的策略来进行故障检测。
在转移到描述SWIM协议细节之前,我们首先奠定理解分布式故障检测器协议的关键的效率和可升缩性特征的基础。通过[6,7,12,16]的研究已经可以辨别分布式故障检测器协议的基本属性(从理论和实际的角度),和同时不可能满足他们的结果。结果的权衡通常是根据分布式应用需要的安全性和可用性来决定的。这些属性是[12]:
- Strong Completeness:任何成员的奔溃故障会被所有非故障成员检测到[6];
- 故障检测的速度:一个成员故障到它被一些非故障成员检测到的时长
- 准确性:故障检测的误报率
- 网络消息负载:每秒由协议产生的字节数
[6]证明了在一个异步网络上建立一个准确(没有错误的检测)且Strong Completeness的故障检测器是不可能的。然而,由于典型的分布式应用依赖于一直持有(为了维护动态组的时间信息)的Strong Completeness,包括基于心跳方案的大多数故障检测器保证这个属性,同时试图保持较低的误报率。SWIM采用相同的方式。
在[12]中,一个简单的计算表明了在满足指定每个成员的故障检测率(记为PM(t)),和n个成员组大小的检测时间T的情况下最小的网络负载(每秒字节数)。计算出来的负载时n∙(log(PM(T)))/(log(pml)),pml是底层网络的包丢失概率。
虽然这个计算结果是在理想的情况下,即每个消息的独立的消息丢失概率(pml),计算出来的,它可以作为一个很好的比较不同故障检测协议的基线。例如,Section2中讨论的all-to-all的心跳协议有一个与组规程呈线性变化的次最优因子。
3. The Basic SWIM Approach
如前所述,SWIM有两个组件:
- 一个故障检测器组件:用来检测成员故障
- 一个传播组件:用来传递最近有成员加入,离开或者故障的消息
我们现在描述基本的SWIM协议。基本协议使用基于[12]的故障检测协议的随机探测方式(Section 3.1)并且通过网络广播传播成员更新信息(Section 3.2)。SWIM协议通过提炼这个最初设计开发成功(Section 4)。
3.1. SWIM Failure Detector
SWIM故障检测算法[12]使用两个参数:协议周期T’(时间单元)和整数k—故障检测子集的大小。协议不要求成员之间同步时钟,并且协议的属性保证T’是否是组成员的平均协议周期。

图1说明了协议在任意一个成员Mi上的工作过程。在每个协议周期的T’时间单元(Mi的本地时钟)内,从Mi的成员列表中随机选中一个Mj,并且发送一个ping消息给它。Mi然后等待赖在Mj的ACK。如果在指定的超时时间(通过消息的往返时间决定,通常选择小于协议周期)内没有收到ACK,Mi间接探测Mj。Mi随机选择择k个成员并且都发送ping-req(Mj)消息。每一个成员(非故障的)收到这个消息后,ping Mj,并且转发Mj的ACK(如果收到)给Mi。在协议周期结束的时候,Mi检查是否收到任何ack,不论是直接来自Mj还是间接通过那k个成员。如果没有收到,它声明Mj,已经故障,并且通过传播组件处理这个更新。
在图1的示例中,只要这k个成员中的一个在完成这个周期时认为Mj是存活的,则Mi在这个协议周期会认为Mj是故障的。
用于启动间接探测的预先指定的超时时间基于分布式网络的往返时间进行估计,例如平均值或者99%的用时。注意协议周期T’必须至少是往返时间估计的三倍。在我们的实验中,使用往返时间的评价值来设置超时时间,并且我们的协议周期远远大于这个值。
协议的每个消息都包含启动者Mi上的唯一的协议周期序列号。注意ping,ping-req,ack消息的大小有一个常亮的边界值,并且独立于组大小。
上述协议的第二部分使用一个间接的子成员探测小组来重新ping和ack。使用这种方法而不是直接发送k个ping消息给Mj,或者直接返回ping-req的ack给Mi,避免受Mi和Mj之间的网络堵塞的影响。堵塞可能导致丢失原始的ping消息或者它的ack。
这个故障检测协议在[12]中已经分析过。这里我们简单的总结下分析结果:
- 如果每个成员有一个大小为n的成员列表,并且其中有qf是非故障的,则一个协议周期中任意一个成员被选为ping目标的概率为
 ,它下降的很快(随着n—>∞)到
,它下降的很快(随着n—>∞)到
-
因此,任意故障的成员和它被组内其他进程检测到的预期时间最多是
 。根据应用指定的期望检测时间,这给出了一个协议周期长度的估算值。
。根据应用指定的期望检测时间,这给出了一个协议周期长度的估算值。 -
如果
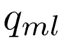 是及时传递一个包的概率,所有传送的包都是独立的,在一个协议周期内任何一个非故障成员会被错误的检测为故障的概率为
是及时传递一个包的概率,所有传送的包都是独立的,在一个协议周期内任何一个非故障成员会被错误的检测为故障的概率为
-
根据应用要求的误报率,这给出了一个k的配置值。
-
这个故障检测器满足Strong Completeness:一个故障成员在每个非故障成员上最终会被选为一个ping目标,并且从它的成员列表中删除。
-
由协议引入的每个成员的消息负载是一个常量,它不随组大小变化,并且所有成员都是对称的。这个负载可以通过k的估算值计算出来。
- 这些属性(除了渐进值)都不依赖于组大小n
3.2. Dissemination Component and Dynamic Mem- bership
在检测到一个组成员故障后,进程只是简单的广播Mj失败的消息到剩下的组成员中。一个成员接收到这个消息后将Mj从它的本地成员列表中删除。
新加入成员或者主动离开成员的信息以相似的方式广播。然而,对于一个加入的进程,他必须知道至少一个组内的联系成员。这可以通过一些方式实现:如果组关联到一个众所周知的服务器或者IP多播地址,所有的加入可以直接连接相关地址。在缺乏这样的基础设施的情况下,加入消息可以广播出去,组成员接收到之后可以决定(通过抛硬币)是否响应。另外,为了避免多个成员响应,可以在组内维护一个静态的协调器来处理加入请求。实际上,存在多个协调器并不影响协议的正确性,只会导致多个加入请求响应。通过传播组件,随着时间的推移可以发现和解决多个协调器。在当前的SWIM版本中,我们选择维护一个协调器,尽管没有理由排除任何其他的策略。
4. A More Robust and Efficient SWIM
Section 3描述了基本的SWIM协议,它使用网络多播来传递成员更新信息(成员加入,离开和故障)。然而,网络多播原语比如IP多播等,只是最大努力——消息丢失可能导致任何成员的任意的和相关未接收成员关系变化。在Section 4.1中我们描述了一个通过故障检测协议发送的ping和ack消息附带成员更新信息的传递组件。这完全消除了由于传递组件(通过)导致的额外的数据包生成。SWIM只生成ping,ping-req和ack数据包,从而为每个成员提供一个常量的消息负载。这种方式导致一个传染风格的信息传递,使得数据包丢失的鲁棒性提供和低延迟。
基本的SWIM协议其计算的准确性受慢进程(例如,由于缓冲区溢出丢失大量数据包)声明一些非故障进程已经故障的影响。这也有可能是进程受到短时间的波动,比如一个高负载的机器。这导致进程没有机会准时的响应接收到的ping消息,而被错误的声明为故障。Section 4.2提出了一种猜疑机制,一个进程没有响应ping消息,就像Section 3描述的那样,不会被立即声明为“故障”。相反,进程声明它是“可疑的”,并且这个信息使用传播组件扩散到组内。在一个预设的超时时间(在Section 5中讨论如何设值)之后,被猜疑的进程被声明为“故障”并且这个消息传播到组内。然而,如果在这个超时过期之前,被猜疑的进程响应了一个ping请求,关于它还“或者”的消息被传播的组内。这个进程将会在不同成员的成员列表中重新被激活,而无需离开或者重新加入组。这个预先指定的超时时间通过增加故障检测时间而降低误报率。
基本的SWIM故障检测协议保证最终任意一个故障进程Mi会被每个非故障组成员Mi检测到。然而,它没有保证任意一个故障成员Mi和它被另一个任意的成员Mj(基于Mj的本地协议数)检测到的时长。Section 4.3描述了一个修改的SWIM故障检测协议,它保证时间有界的完整属性;故障发生和它被Mj检测到之间的时长不会超过两倍的组大小(协议周期数量)。
4.1. Infection-Style Dissemination Component
基本的SWIM协议传递成员更新消息通过使用原始的多播。在大多数网络和操作系统中,硬件多播和IP多播都是可用的,但是都基本不会开启,例如由于管理的原因。为了传播成员更新消息到所有的组成员,基本的SWIM协议不得不使用昂贵的广播或者低效的点对点消息机制。更进一步,多播是不可靠的,成员变换只能尽最大努力传递给组成员。
相反,增强的SWIM协议完全消除了使用额外的原始多播。它通过在故障检测协议生成的ping,ping-req和ack消息上携带信息来传递。我们称为传染式的传播机制,信息传播类似于社会中八卦的传播,或者在普通人群中传播[8]。注意传播机制的实现并不生成任何额外的数据包(例如多播)——所有“消息”都通过搭载在故障检测组件的数据包上传播。
Bailey[2]给出了包含一个初始感染成员的大小为n的均匀混合的组的传染速度的确定分析。在每个单位时间内接触率为β的情况下,(期望的)感染成员数x(初始为1)和时间t的关系可以得到:
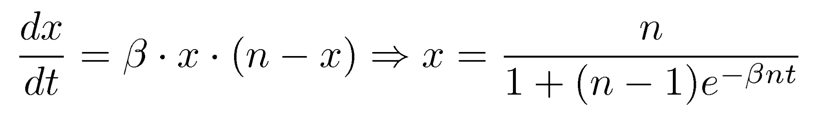
在我们的传染式的传播组件中,通过ping和ack消息传递成员更新信息的速度也能以一种相似的方式分析。协议的周期当做一个时间单位,接触率β是任何一对感染与未感染成员联系的概率,并且等于
 。这告诉我们
。这告诉我们 。
。
这样一个传染进程以指数级在组内快速传播。在 轮协议周期后,这里λ是一个参数,期望的受传染的成员是
轮协议周期后,这里λ是一个参数,期望的受传染的成员是 。在
。在 协议周期后通过传染风格携带传递的成员更新信息会到达
协议周期后通过传染风格携带传递的成员更新信息会到达 个组成员。简化一下,随着n增长(—>∞),x的估值为
个组成员。简化一下,随着n增长(—>∞),x的估值为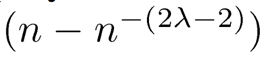 。将λ设为一个很小的常量足以满足可靠的传播——即使在很小的组大小下也是真的,就像我们在Section5中的实验所示。
。将λ设为一个很小的常量足以满足可靠的传播——即使在很小的组大小下也是真的,就像我们在Section5中的实验所示。
文献包含了一些其它传入风格[4,8,13]的分析,关于他们的可靠性概率有着基本相似的结论。这些分析也表名传染风格的传播可以弹性从处理故障和网络消息丢失,就像流行病的传染。我们的实现结果也展示了这些特性。
实现上是顺序的。SWIM协议层在每个组成员Mi上维护一个最近的成员更新的缓存,以及每个缓存元素的一个本地计数。该本地计数表名该元素到目前为止被Mi上携带的次数,并用来选择下次携带哪个元素。每个元素最多可以被携带次。如果缓存区的大小大于在单个ping消息(或者ack)上能够携带的元素最大数量,选择被传递次数更少的元素。由于协议的周期时固定的,并且成员变化的速率可能暂时高过传播速率,这是必要的。在这种情况下,更”年轻“的缓存元素可以保证所有成员变化传染至少几个成员——当成员变化速度停顿时,这些变化会通过剩下的组成员传播。
我们对这个协议的实现维护两个组成员列表——一个列表是那些没有被声明为故障的组成员,另一个是最近已经故障的成员。目前,从这两个列表中选取相同数量的缓存元素来进行携带,但是该方案可以推广到适应进程加入,离开和故障率的相对变化。
4.2. Suspicion Mechanism: Reducing the Fre- quency of False Positives
在到目前为止描述的SWIM故障检测协议中,如果一个非故障成员Mj(错误的)被另一个成员Mi错误的检测为已经发生故障,无论是由于网络包丢失或者因为Mj睡眠了一段时间,还是因为Mi是一个慢进程,Mj会在组内声明为已经故障。换句话说,一个完全健康的进程Mj遭受了非常重的惩罚,在被错误的检测为故障后强制退出组。这导致一个很高的误报率。
我们通过修改SWIM,无论何时基本的SWIM故障检测协议检测到一个故障都运行一个子协议降低了这种影响,该子协议称为猜疑子协议。
猜疑子协议工作流程如下。考虑成员Mi在当前协议周期选择成员Mj作为ping目标,并且运行基本的SWIM故障检测周期。如果Mi没有接收到确认消息,不论是直接或者间接的探测子集,它并不声明Mj是故障的。相反,Mi在本地成员列表中标记Mj为可疑的。另外,一个{Suspect Mj:Mi Suspect Mj}消息通过传播组件在组内传递开来。任何组成员Ml收到该消息也标记Mj为可疑的。可以的成员待在成员列表中并且在SWIM故障检测协议选择ping目标时被当做一个非故障成员。
如果一个成员Ml在基本的SWIM协议过程中成功的ping一个可疑的成员Mj,它取消成员列表中之前Mj的可以标记,并且通过传播组件(在我们的系统中使用传染风格)传递{Alive Mj:Ml konws Mj}消息。这样一个Alive的消息取消接受Mj可疑的成员的列表中的可疑标记。注意,如果成员Mj收到猜疑它自己的信息,他可以传递一个Alive的消息来声明它没有故障。
超过指定的超时时间后,成员列表中被猜疑的记录过期。如果Mj在成员Mh上是可疑的,并且在收到Alive消息之前已经超时,Mh声明Mj已经故障,并且将其从本地成员列表中删除,并开始通过传播组件传递{Confirm Mj:Mh declares Mj as faulty}消息。这个消息会覆盖之前的Suspect或者Alive消息,并且从所有接受这的成员列表中删除Mj。
这个机制降低(并未消除)了故障检测的误报率。注意原始协议的Strong Completeness属性继续保持。处理猜疑一个故障进程Mj的失败可能会延长故障检测时间,但是最终被检测到是可以保证的。
从上面的讨论中,Alive消息覆盖了Suspect消息,Confirm消息覆盖了Suspect和Alive消息,在这种影响下,本地成员列表对可以元素Mj保持一致。然而,一个成员在他的生命周期中可能被猜疑和解除猜疑多次。这些多版本的Suspect和Alive消息(都关联同一个成员Mj)需要通过唯一的标识符区分。这个标识符通过使用成员列表中每个元素的虚拟的incarnation number属性来提供。Incarnation number是全局的。一个成员Mi的incarnation number当它加入时初始化为0,它只可以被Mi增加,当它收到它被猜疑的信息时,Mi生成一个拥有它标识符和一个自增incarnation number的Alive消息,并且通过传播组件传递到组内。
因此,Suspect,Alive和Confirm消息包含成员的incarnation number和它的标识符。这些消息的优先次序和他们对成员列表的影响被指定如下:
- {Alive Ml, inc=i} overrides
—{Suspect Ml, inc=j},i>j
—{Alive Ml, inc=j},i>j
- {Suspect Ml, inc=i} overrides
—{Suspect Ml, inc=j},i>j
—{Alive Ml, inc=j},i≥j
- {Confirm Ml, inc=i} overrides
—{Suspect Ml, inc=j},any j
—{Alive Ml, inc=j},any j
很容易看到这些消息的优先次序和覆盖维护故障检测组件所需要的正确属性。熟悉adhoc路由协议例如AODV的读者会注意到使用序列号和我们的incarnation number机制之间的相似性。
传播组件的偏好规则和传染风格也包含了一个进程被多个进程怀疑。偏好规则不依赖于猜疑的来源,并且如果有多了个来源,传染模式传递一个消息(Suspect,Alive或者Confirm)非常迅速,且每个进程的开销与来自一个传染源的开销完全一样。
4.3. Round-Robin Probe Target Selection: Provid- ing Time-Bounded Strong Completeness
在Section 3中描述的基本的SWIM故障检测协议在一个平均常量的协议周期内检测到故障。及时每个进程故障被保障最终会被每个非故障进程检测到(eventual Strong Completeness),一个病态的ping目标的选择会导致组内任何地方第一次检测到该异常时有很大的延迟。极端情况下,这个延迟可能是无界的,由于故障的进程用于不会被其他非故障进程选为ping目标。
这可以通过如下修改协议来解决。故障检测协议在成员Mi上通过维护一个当前成员列表的已知元素的列表(直观的,一个数组),并且不是随机的从这个列表中选取ping目标,而是轮训方式。相反,一个新成员加入时,随机的选择一个位置,并插入列表中。当完成整个列表的遍历时,Mi上以一种随机重排的方式重新安排成员列表。
考虑Mi上如上修改的SWIM协议的执行。一旦另一个成员Mj包含在Mi的成员列表中,在每次遍历Mi的成员列表时都会被选作ping目标。如果成员列表的大小不超过ni,成功的选择相同目标最多需要(2·ni-1)个协议周期。它限制了任何故障进程成员Mi的故障检测时间的最坏情况,因此它满足Time Bounded Completeness 属性。
原始协议的平均故障检测时间通过这个优化保留下来,因为在不同成员上的随机的成员列表导致每个成员一个相似的分布式ping目标选项。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号