
最强半自动化抓鸡工具打造思路
一、说明
你向别人说你是搞安全的,外行人会问你能盗QQ吗内行人会问你能拿站吗,在很长一段时间里只能反复尴尬地回答不能,然后外行人就对你兴趣缺缺内行人也对你兴致缺缺。
大概2010年以前尤其2005年以前,一是厂商并没有那么重视安全所以漏洞很多二是用户也缺乏安全意识有补丁也很少打,造成的结果就是漏洞很多且长时间内都可利用。基于这种情况很容易地就可以编写一款自动化工具然后在很长时间内都能用来攻破大量系统,但在现在漏洞密度越来越小利用难度越来越高0day/1day时间越来越短的环境下,这种模式越来越难以持续了。新人们不能不比老人们当年我学几天就拿下xxx实在不是人的水平低了而是外部安全水平高了。
你说得很有道理但是谁在意呢,正如妹子问你有没有房,你说房价涨得太快啦老家刚装修啦,那就是没有嘛。想了一想搞安全要求能拿站应该不算过分,环境怎么样是我们自己要去处理的问题而不是只要求结果的领导们要了解的问题。难道老人们水水就叫能拿站新人就毫无捷径可走被贴上一代不如一代的标签吗。想了一想,正如刚改革开放只要稍微努力都能奔小康现在搞IT还有希望跨阶层,只要把自动化发挥到极致轻松抓鸡还是有可能。
二、自动化攻击思路
集成化思路其实在很多地方都存在,比如cvedetails上会尽量列出关联的exploit,再如shodan和zoomeye上搜索主机会列出相关CVE,又如AutoSploit就直接是一个抓鸡工具。
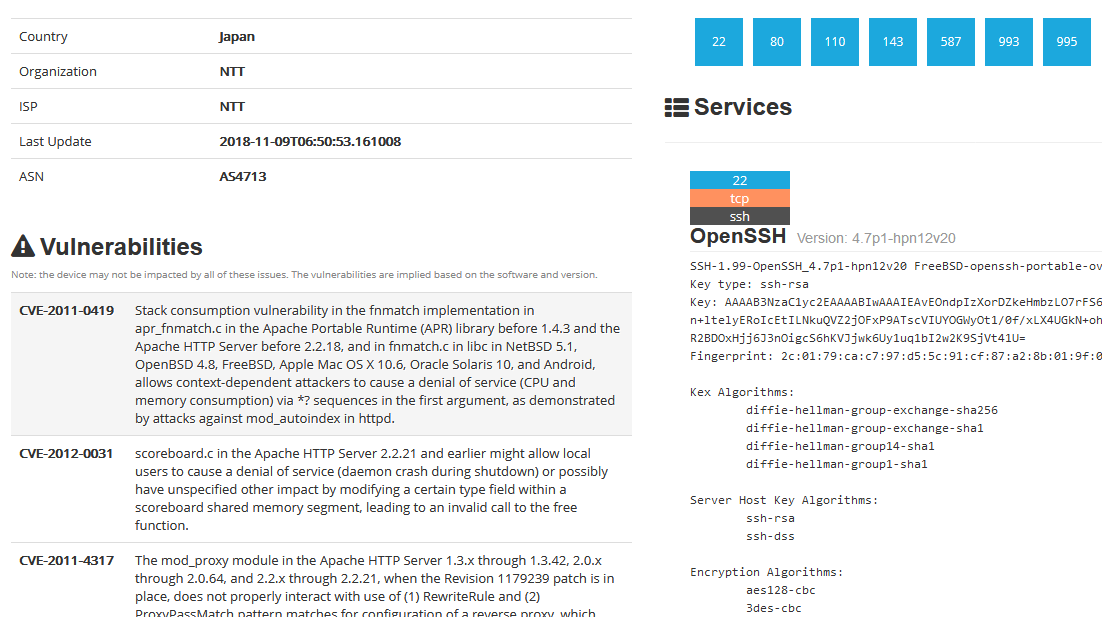
cvedetails首先有些exp并没有列到对应的cve条目上(不懂为什么),其次在真正的渗透中我们需要自己扫描ip存在的服务。
shodan和zoomeye主是列出了主机相关的cve。并没有直接列出exp。
autosploit为了实现自动化,只能使用特定格式的msf模块,一些可以攻击的百规范化exp都被舍弃了。
结命以上各工具优缺点,我们这里选实现的“IP-服务-CVE-EXP”三步,舍弃掉最后攻击一步。
其实从标题“抓鸡”可知最初而言是希望能实现autosploit那样的自动化攻击,但实现过程中发现存在想得太简单,不是别人只想到集成而没想到自动化而是有很多问题。所以本文“抓鸡”是标题党,“最强”也是标题党,后来补上去的“半自动化”也是标题党,程序只算能运行起来。不过对于采集CVE、MSF模块和exploitdb的exp及进一步的应急响应都还算有些意义。
2.1 指定ip查找exp
经过以下三步,得出最终IP及可用EXP(由IP确认EXP)
| 步骤 | 输入 | 处理 | 输出 |
| 第一步 | IP | Shodan/Nmap | IP开放的服务及版本 |
| 第二步 | IP开放的服务及版本 | cvedetails类似数据库 | 服务及版本存在的CVE |
| 第三步 | 服务及版本存在的CVE | metasploit/exploit-db | CVE对应的exp |
2.2 使用最新exp找出适用该exp的ip
经过以下三步,得出最终IP及可用EXP(由EXP确认IP)
| 步骤 | 输入 | 处理 | 输出 |
| 第一步 | 最新的exp | metasploit/exploit-db | exp相关cve |
| 第二步 | exp相关cve | cvedetails类似数据库 | cve影响的服务及版本 |
| 第三步 | cve影响的服务及版本 | Shodan | 存在服务及版本的IP |
三、数据库建设思路
在上一节中,我们提到了以下几项:shodan、cvedetails、metasploit和exploit-db。
3.1 否定联网方式
首先,联网方式受网速限制。这些网站都是国外网站速度相对不稳定,几个网站依次访问耗时会较长。
其次,联网方式受网站保护策略限制。频繁该问IP有可能被封掉(虽然测试中尚未发现),其次像exploit-db查询需要验证码。
再次,联网方式受网站排版限制。比如cvedetails查询一个产品存在的cve列出的先是一个匹配产品汇总表,点进去再是一个漏洞年份汇总表,再点进去才是CVE列表,要走好几步这是很麻烦的。


除了shodan必然需要联网使用,cvedetails、metasploit和exploit-db都不适宜联网方式。
3.2 否定metasploit和exploit-db使用管道形式
在kali上metasploit通过启动msfconsole然后使用search命令可以进行搜索,但使用msfconsole的都会感觉到其启停是比较耗费资源和时间的,所以启动msfconsole查询然后通过管道获取结果的形式并不好。
在kali上可以使用searchsploit命令查找exploit-db的exp,这资源和时间都算可接受,但是一定要安装好exploit-db才能用这限制很大也不是很理想。
3.3 数据库建设思路
在否定联网方式和否定管道形式后,剩下的只能建设本地数据库,而建设又可以分为在线建设和离线建设两种思路。
在线建设就是一个个页面去访问页面然后解析入库,这种方式一是花费时间长,二是在实践时中间常因为请求超时和解码有误而使程序中断,三是这种暴力的形式容易被封IP(metasploit最敏感,exploit最宽容;在被封IP时你可以感受到动态IP也有好处)。基于以上原因能离线建设就离线建设。
| 数据库 | 建设方式 | 更新方式 | url |
| cve数据库 | cvedetails虽然没提供离线下载,但cvedetails的cve数据来源于nvd,nvd提供cve离线下载。离线建设 | 每日下载nvdcve-modified.xml更新数据库 | https://nvd.nist.gov/vuln/data-feeds |
| metasploit数据库 | metasploit在github有托管。离线建设。 | metasploit实在太容易封ip,git同步项目后重新遍历采集 | https://github.com/rapid7/metasploit-framework |
| exploitdb数据库 | exploitdb在github也有托管,但是cve只向exploitdb合作者提供而cve是程序的关键,所以只能使用在线建设 | 仍然只能在线追踪 | https://www.exploit-db.com/ |
关于更新还有以下几个关键点:
cvedetails在排列cve时只是简单地order by cve desc,这导致的问题就是排在最前面的cve并不一定是最新的cve,比如CVE-2018-1002209(2018-07-25发布)会排在CVE-2018-19115(2018-11-08发布)前面,所以cvedetails并不适合用来采集更新。
由于cve数据库使用nvdcve-modified.xml进行更新,这就要求必须每天都执行更新程序不然cve就会不完整。nvdcve-modified.xml一是包含新发布的cve二是包含旧cve的更改,如果要保证cve的完整性需要重新下载搁置更新的年份的xml重新读取,如果要保证参考等的完整性那就要删除数据库全部重新解析入库(还是要时间的大概半天)。
metasploit一个模块发布后一般不会再改动,所以我们以module_name为关键字,每次git pull同步后如果已存在就放弃插入如果尚未存在就插入,这能很好地保证metasploit数据库的完整性。单纯exploit模块整个过程大概只需要半个小时。
exploitdb在线建设花费比较长的时间,一是在线不断请求耗时二是虽然比较宽容但连接太久也会被禁,断断续续整个采集过程大概需要一周。
exploitdb以edbid为关键字,更新时依次访问exploitdb的remote、webapps、local、dos四大页面该页面,从头开始解析如果查到已存在expid则终止往下读取。remote等一个页面大概能显示一到三个月内的exp,在此时间范围内能弥补缺失的记录如果超出一页那么那些记录也将不会补追补。当然你也可以在remote等中一页页地追踪下去但考虑以下两点这里不这么实现,但这里一是考虑一个月时间已经比较长,二是edbid是递增的可以自由地设置采集的edbid的区间。
3.4 数据库选择
首先,是选关系型数据库还是非关系型数据库,根据实际来看使用关系型数据库当有子查询时速度很慢,建索引也还是比较耗时间,所以可能非关系型数据库会快些。但是我需要同步到elk但elk不支持从非关系型读取数据,所以只能使用非关系型数据库。另外如果你要自己改成非关系型数据库那工作量比较大。
其次,选择关系型数据库后还要确定具体选哪个数据库,其实不扯到高可用这些东西仅就使用来说关系型数据库都差别不大,开始想用sqlite但同步到elk时一直报错处理不了,后来很慢想oracle可能快一些但太耗资源电脑运行不起,所以就用mysql。你自己要改成其他数据库,连接语句和sql语句稍微修改应该就可以了。
3.5 数据库表设计
3.5.1 cve表设计
cve_records表各字段如下:
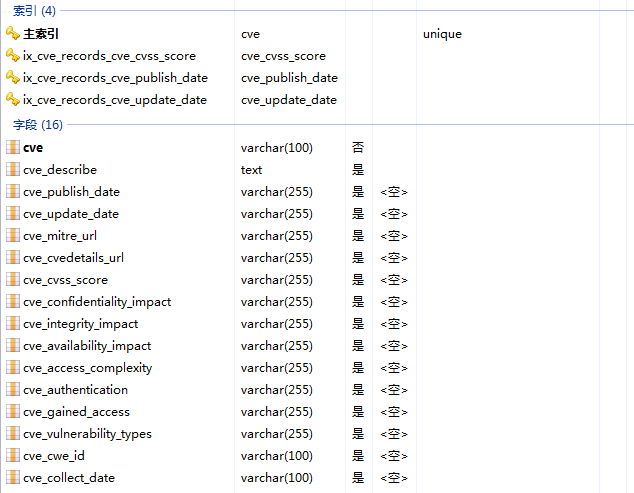
对应cvedetails以下部份:
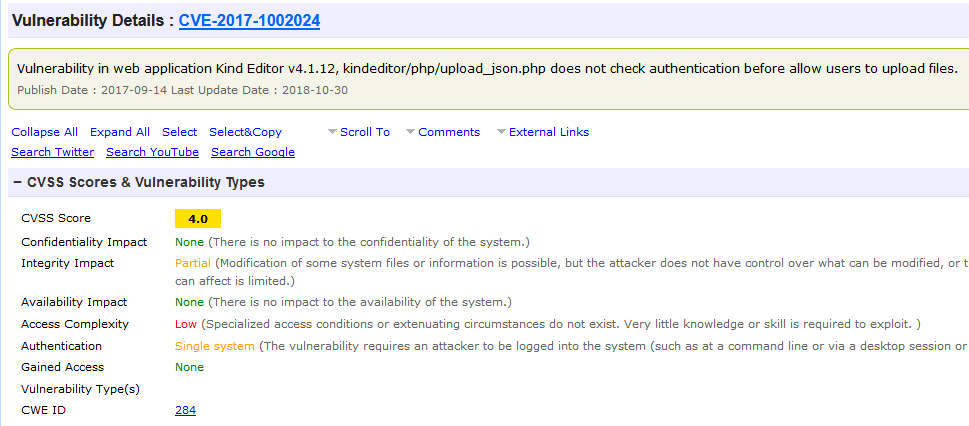
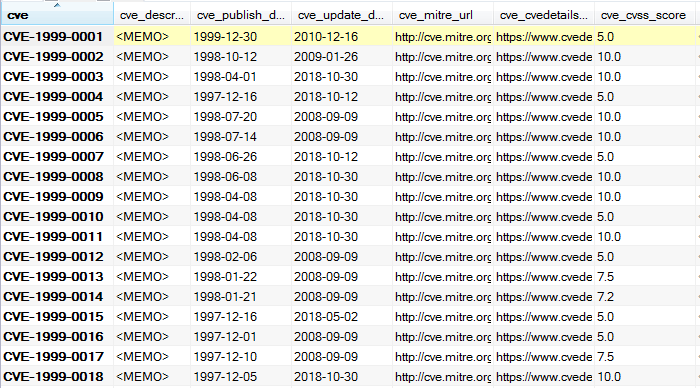
最终数据示例如下:
cve_affect_records表用于记录受cve影响的产品,各字段如下:
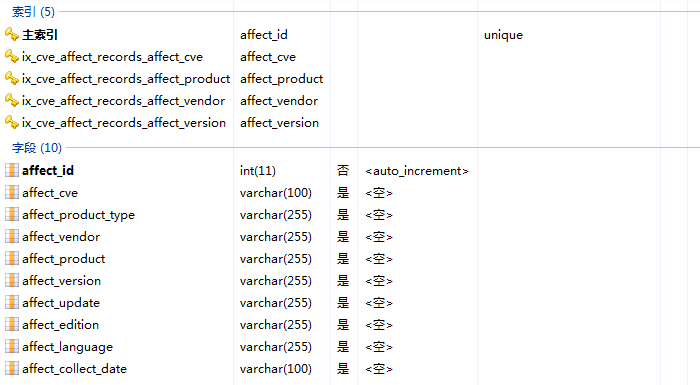
对应cvedetails以下部份:
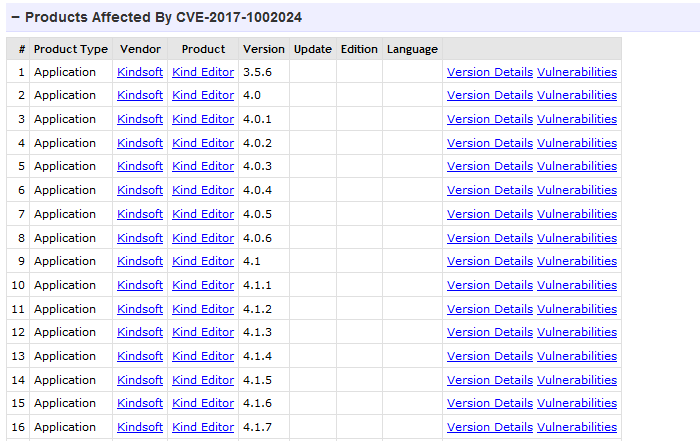
最终收集数据示例如下:
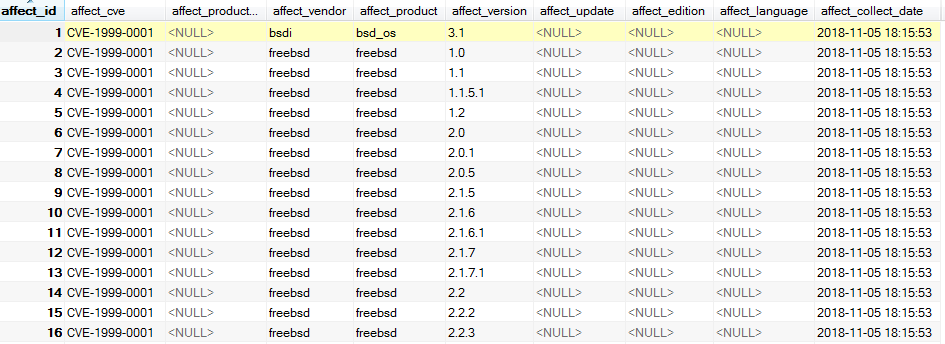
cve_refer_records表用于记录cve的参考链接,各字段如下:

对应cvedetails以下部分:

最终收集数据示例如下:

3.5.2 msf表设计
msf_records表各字段如下:
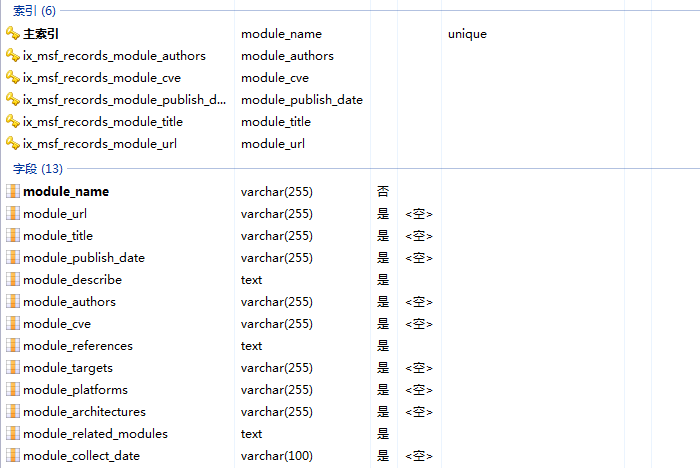
对应模块查看页面的那几项内容:

最终收集数据示例如下:
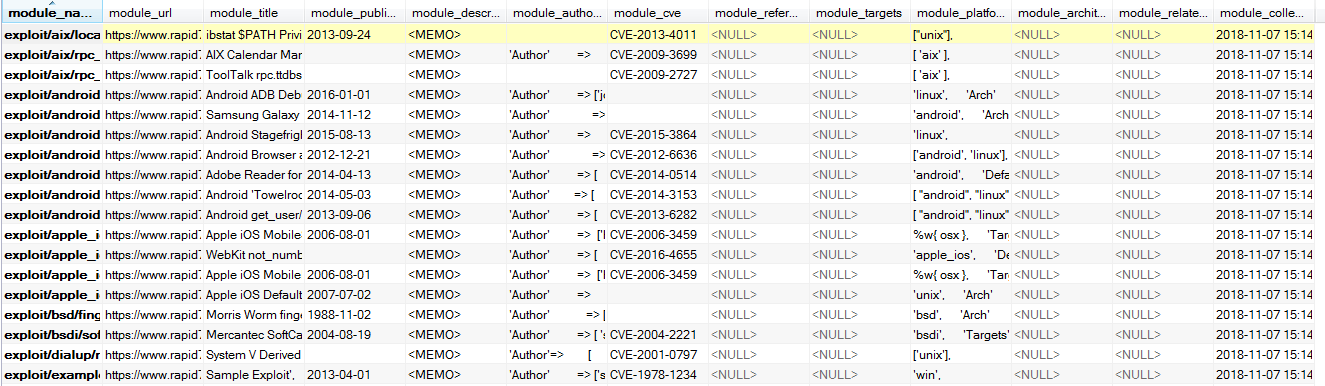
3.5.3 edb表设计
edb_records表各字段如下:
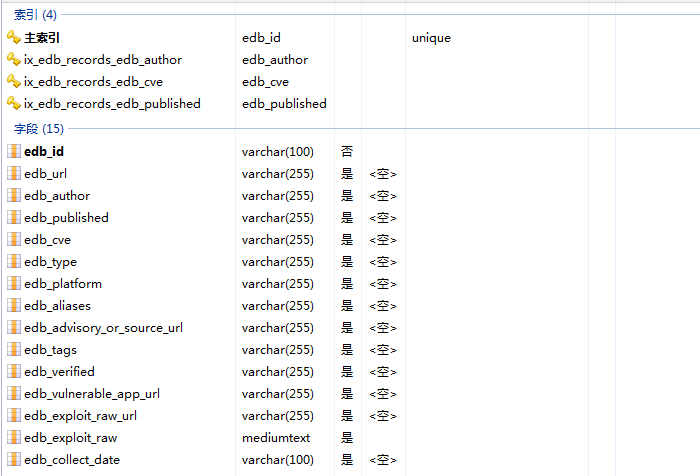
对应edb查看页面如下几项内容:
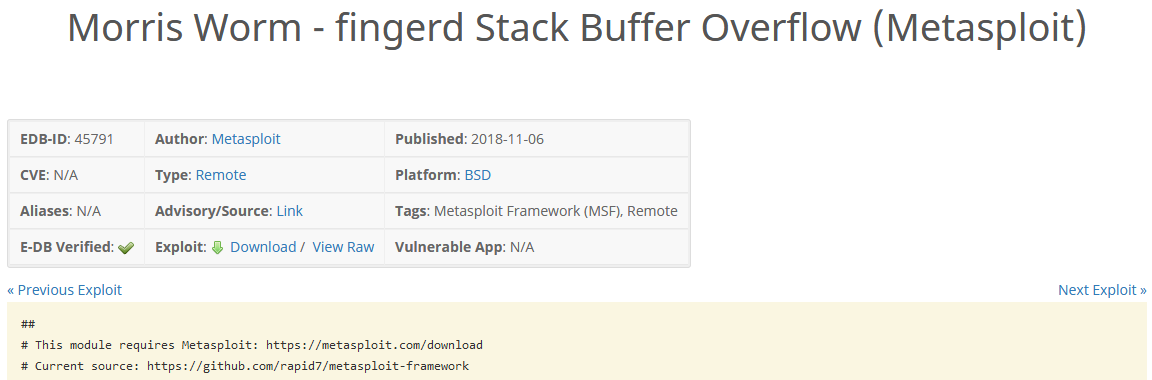
最终收集数据示例如下:

四、程序说明
4.1 程序使用说明
程序写了两周,实现效果也不是很好不是很有心情仔细说明,另外文件中也有一定注释。
配置好setting相关项,运行cve_offline_parse.py,就会收集cve数据
配置好setting相关项,运行msf_offline_parse.py,就会收集msf模块数据
配置好setting相关项,运行edb_online_parse.py,就会收集edb模块数据
项目文件结构整体如下:
|-config| | |-setting.py----程序配置文件,自己使用时主要修改这个文件 | |-dao| | |-src_db_dao.py----存放各dao数的文件 | |-model| | |-src_db_model.py----存放数据库表对应的model的文件 | |-cve_offline_parse.py----通过下载nvd的xml解析入库cve的文件 | |-cve_online_parse.py----原本设计通过读取cvedetails解析入库cve的文件,实际不使用 | |-daily_trace_report.py----检查cve、msf、edb更新情况并发送通知邮件的文件 | |-edb_online_parse.py----通过遍历www.exploit-db.com解析入库exp的文件 | |-exploit_tool.py----所谓的“半自动化抓鸡工具”实现文件 | |-msf_offline_parse.py----通过git同步github的metasploit-framework解析入库模块的文件 | |-msf_online_parse.py----原本设计通过遍历www.rapid7.com/db/modules解析入库模块的文件,实际只用其追踪更新功能。 | |-search_engine.py----shodan搜索实现文件
说明:2018.12.08发现exploit-db网站升级,新写edb_online_parse_new.py替代旧的edb_online_parse.py。
4.2 运行环境
语言:python3
额外安装库:pip install requests requests-html pymysql sqlalchemy shodan beautifulsoup4
4.3 程序源代码
代码比较多,直接上github(db目录是我收集好的数据解压出来导入mysql即可):https://github.com/PrettyUp/expdb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号