
Python3+SQLAlchemy+Sqlite3实现ORM教程
一、安装
Sqlite3是Python3标准库不需要另外安装,只需要安装SQLAlchemy即可。本文sqlalchemy版本为1.2.12
pip install sqlalchemy

二、ORM操作
除了第一步创建引擎时连接URL不一样,其他操作其他mysql等数据库和sqlite都是差不多的。
2.1 创建数据库连接格式说明
sqlite创建数据库连接就是创建数据库,而其他mysql等应该是需要数据库已存在才能创建数据库连接;建立数据库连接本文中有时会称为建立数据库引擎。
2.1.1 sqlite创建数据库连接
以相对路径形式,在当前目录下创建数据库格式如下:
# sqlite://<nohostname>/<path> # where <path> is relative: engine = create_engine('sqlite:///foo.db')
以绝对路径形式创建数据库,格式如下:
#Unix/Mac - 4 initial slashes in total engine = create_engine('sqlite:////absolute/path/to/foo.db') #Windows engine = create_engine('sqlite:///C:\\path\\to\\foo.db') #Windows alternative using raw string engine = create_engine(r'sqlite:///C:\path\to\foo.db')
sqlite可以创建内存数据库(其他数据库不可以),格式如下:
# format 1 engine = create_engine('sqlite://') # format 2 engine = create_engine('sqlite:///:memory:', echo=True)
2.1.2 其他数据库创建数据库连接
PostgreSQL:
# default engine = create_engine('postgresql://scott:tiger@localhost/mydatabase') # psycopg2 engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase') # pg8000 engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')
MySQL:
# default engine = create_engine('mysql://scott:tiger@localhost/foo') # mysql-python engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo') # MySQL-connector-python engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo') # OurSQL engine = create_engine('mysql+oursql://scott:tiger@localhost/foo')
Oracle:
engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname') engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')
MSSQL:
# pyodbc engine = create_engine('mssql+pyodbc://scott:tiger@mydsn') # pymssql engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')
2.2 创建数据库连接
我们以在当前目录下创建foo.db为例,后续各步同使用此数据库。
在create_engine中我们多加了两样东西,一个是echo=Ture,一个是check_same_thread=False。
echo=Ture----echo默认为False,表示不打印执行的SQL语句等较详细的执行信息,改为Ture表示让其打印。
check_same_thread=False----sqlite默认建立的对象只能让建立该对象的线程使用,而sqlalchemy是多线程的所以我们需要指定check_same_thread=False来让建立的对象任意线程都可使用。否则不时就会报错:sqlalchemy.exc.ProgrammingError: (sqlite3.ProgrammingError) SQLite objects created in a thread can only be used in that same thread. The object was created in thread id 35608 and this is thread id 34024. [SQL: 'SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \nFROM users \nWHERE users.name = ?\n LIMIT ? OFFSET ?'] [parameters: [{}]] (Background on this error at: http://sqlalche.me/e/f405)
from sqlalchemy import create_engine engine = create_engine('sqlite:///foo.db?check_same_thread=False', echo=True)

2.3 定义映射
先建立基本映射类,后边真正的映射类都要继承它
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()

然后创建真正的映射类,我们这里以一下User映射类为例,我们设置它映射到users表。
首先要明确,ORM中一般情况下表是不需要先存在的反而为了类与表对应无误借助通过映射类来创建;当然表已戏存在了也无可以,在下一小结中你可以自己决定如果表存在时要如何操作是重新创建还是使用已有表,但使用已有表你需要确保和类的变量名与表的各字段名要对得上。
from sqlalchemy import Column, Integer, String # 定义映射类User,其继承上一步创建的Base class User(Base): # 指定本类映射到users表 __tablename__ = 'users' # 如果有多个类指向同一张表,那么在后边的类需要把extend_existing设为True,表示在已有列基础上进行扩展 # 或者换句话说,sqlalchemy允许类是表的字集 # __table_args__ = {'extend_existing': True} # 如果表在同一个数据库服务(datebase)的不同数据库中(schema),可使用schema参数进一步指定数据库 # __table_args__ = {'schema': 'test_database'} # 各变量名一定要与表的各字段名一样,因为相同的名字是他们之间的唯一关联关系 # 从语法上说,各变量类型和表的类型可以不完全一致,如表字段是String(64),但我就定义成String(32) # 但为了避免造成不必要的错误,变量的类型和其对应的表的字段的类型还是要相一致 # sqlalchemy强制要求必须要有主键字段不然会报错,如果要映射一张已存在且没有主键的表,那么可行的做法是将所有字段都设为primary_key=True # 不要看随便将一个非主键字段设为primary_key,然后似乎就没报错就能使用了,sqlalchemy在接收到查询结果后还会自己根据主键进行一次去重 # 指定id映射到id字段; id字段为整型,为主键,自动增长(其实整型主键默认就自动增长) id = Column(Integer, primary_key=True, autoincrement=True) # 指定name映射到name字段; name字段为字符串类形, name = Column(String(20)) fullname = Column(String(32)) password = Column(String(32)) # __repr__方法用于输出该类的对象被print()时输出的字符串,如果不想写可以不写 def __repr__(self): return "<User(name='%s', fullname='%s', password='%s')>" % ( self.name, self.fullname, self.password)
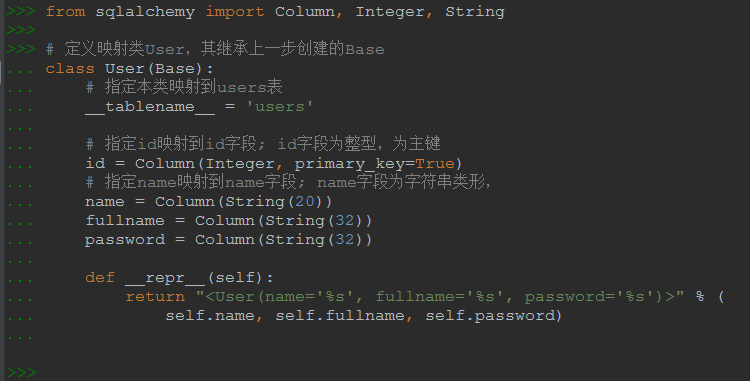
在上面的定义我__tablename__属性是写死的,但有时我们可能想通过外部给类传递表名,此时可以通过以下变通的方法来实现:
def get_dynamic_table_name_class(table_name): # 定义一个内部类 class TestModel(Base): # 给表名赋值 __tablename__ = table_name __table_args__ = {'extend_existing': True} username = Column(String(32), primary_key=True) password = Column(String(32)) # 把动态设置表名的类返回去 return TestModel
2.4 创建数据表
# 查看映射对应的表 User.__table__ # 创建数据表。一方面通过engine来连接数据库,另一方面根据哪些类继承了Base来决定创建哪些表 # checkfirst=True,表示创建表前先检查该表是否存在,如同名表已存在则不再创建。其实默认就是True Base.metadata.create_all(engine, checkfirst=True) # 上边的写法会在engine对应的数据库中创建所有继承Base的类对应的表,但很多时候很多只是用来则试的或是其他库的 # 此时可以通过tables参数指定方式,指示仅创建哪些表 # Base.metadata.create_all(engine,tables=[Base.metadata.tables['users']],checkfirst=True) # 在项目中由于model经常在别的文件定义,没主动加载时上边的写法可能写导致报错,可使用下边这种更明确的写法 # User.__table__.create(engine, checkfirst=True) # 另外我们说这一步的作用是创建表,当我们已经确定表已经在数据库中存在时,我完可以跳过这一步 # 针对已存放有关键数据的表,或大家共用的表,直接不写这创建代码更让人心里踏实

从上边的讨论可以知道,我们可以定义model然后根据model来创建数据表(当然也可以不创建),那可不可以反过来根据已有的表来自动生成model代码呢,答案是可以的,使用sqlacodegen。
sqlacodegen安装操作如下:
# 如果网络通,直接pip安装 pip install sqlacodegen # 如果网络不通,先在网络通的机器上使用pip下载sqlacodegen及期依赖包 pip download sqlacodegen # 上传到真正要安装的机器后再用pip安装,依赖包也会自动安装。版本可能会变化改成自己具体的包名 pip install sqlacodegen-2.1.0-py2.py3-none-any.whl
sqlacodegen生成model操作如下:
# linux应该被安装在/usr/local/bin/sqlacodegen # mysql+pymysql示例 # 可使用--tables指定要生成model的表,不指定时为所有表都生成model # 可使用--outfile指定代码输出到的文件,不指定时输出到stdout # 注意只有当表有主键时sqlacodegen才生成如下的class,不然会使用旧的生成Table()类实例的形式 # 更多说明可使用-h参看 sqlacodegen mysql+pymysql://user:password@localhost/dbname [--tables table_name1,table_name2] [--outfile model.py]
如我的一个示例操作如下,成功为指定表生成model:

sqlacodegen需要执行命令,在DB环境管控严格的情况下此路不通,那还有没有别的方法呢,这时可以使用Automap。以下直接操官方的例子:
from sqlalchemy.ext.automap import automap_base from sqlalchemy.orm import Session from sqlalchemy import create_engine Base = automap_base() # 进行连接, 假设数据库中有t_user和t_address两张表 engine = create_engine("sqlite:///mydatabase.db") # 进行映射,sqlalchemy需要2.x版本 Base.prepare(autoload_with=engine) # 左边的TUser和TAddress是我们映射的类名,你可以随自己的需要起 # 右边的t_user和t_address是数据库里真实存在的表的表名 # t_user和t_address要符合第一范式,即需要有主键 TUser = Base.classes.t_user TAddress = Base.classes.t_address session = Session(engine) # rudimentary relationships are produced session.add(TAddress(email_address="foo@bar.com", user=User(name="foo"))) session.commit() # collection-based relationships are by default named # "<classname>_collection" u1 = session.query(TUser).first() print (u1.address_collection)
2.5 建立会话
增查改删(CRUD)操作需要使用session进行操作
from sqlalchemy.orm import sessionmaker # engine是2.2中创建的连接 Session = sessionmaker(bind=engine) # 创建Session类实例 session = Session()

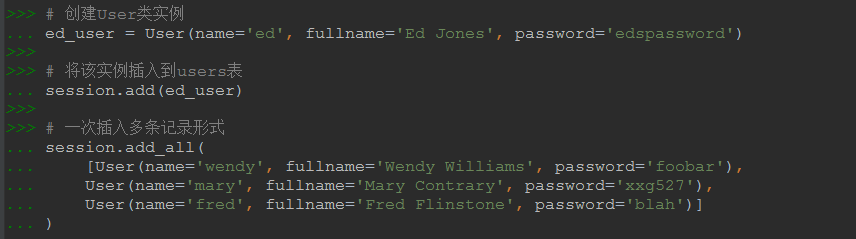
2.6 增(向users表中插入记录)
# 创建User类实例 ed_user = User(name='ed', fullname='Ed Jones', password='edspassword') # 将该实例插入到users表 session.add(ed_user) # 一次插入多条记录形式 session.add_all( [User(name='wendy', fullname='Wendy Williams', password='foobar'), User(name='mary', fullname='Mary Contrary', password='xxg527'), User(name='fred', fullname='Fred Flinstone', password='blah')] ) # 当前更改只是在session中,需要使用commit确认更改才会写入数据库 session.commit()
2.7 查(查询users表中的记录)
2.7.1 查实现
query将转成select xxx from xxx部分,filter/filter_by将转成where部分,limit/order by/group by分别对应limit()/order_by()/group_by()方法。这句话非常的重要,理解后你将大量减少sql这么写那在sqlalchemy该怎么写的疑惑。
filter_by相当于where部分,外另可用filter。他们的区别是filter_by参数写法类似sql形式,filter参数为python形式。
更多匹配写法见:https://docs.sqlalchemy.org/en/13/orm/tutorial.html#common-filter-operators
our_user = session.query(User).filter_by(name='ed').first() our_user # 比较ed_user与查询到的our_user是否为同一条记录 ed_user is our_user # 只获取指定字段 # 但要注意如果只获取部分字段,那么返回的就是元组而不是对象了 # session.query(User.name).filter_by(name='ed').all() # like查询 # session.query(User).filter(User.name.like("ed%")).all() # 正则查询 # session.query(User).filter(User.name.op("regexp")("^ed")).all() # 统计数量 # session.query(User).filter(User.name.like("ed%")).count() # 调用数据库内置函数 # 以count()为例,都是直接func.func_name()这种格式,func_name与数据库内的写法保持一致 # from sqlalchemy import func # session.query(func.count(User3.name)).one() # 字段名为字符串形式 # column_name = "name" # session.query(User).filter(User3.__table__.columns[column_name].like("ed%")).all() # 获取执行的sql语句 # 获取记录数的方法有all()/one()/first()等几个方法,如果没加这些方法,得到的只是一个将要执行的sql对象,并没真正提交执行 # from sqlalchemy.dialects import mysql # sql_obj = session.query(User).filter_by(name='ed') # sql_command = sql_obj.statement.compile(dialect=mysql.dialect(), compile_kwargs={"literal_binds": True}) # sql_result = sql_obj.all()
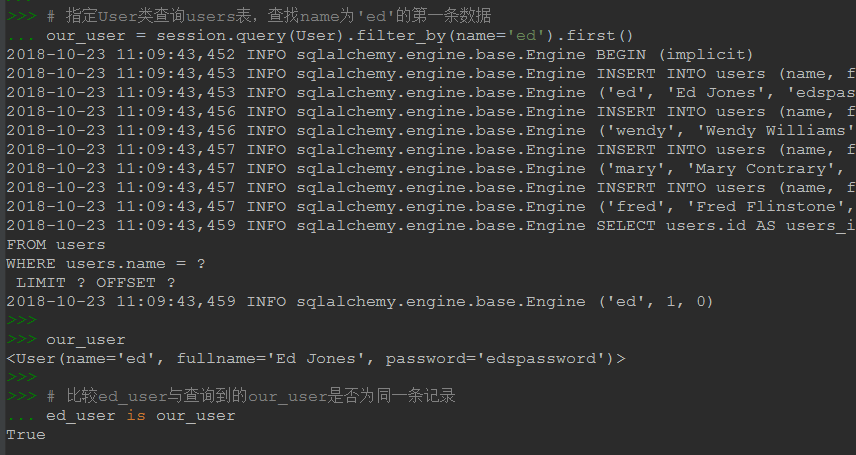
另外要注意该链接Common Filter Operators节中形如equals的query.filter(User.name == 'ed'),在真正使用时都得改成session.query(User).filter(User.name == 'ed')形式,不然只后看到报错“NameError: name 'query' is not defined”。
2.7.2 参数传递问题
我们上边的sql直接是our_user = session.query(User).filter_by(name='ed').first()形式,但到实际中时User部分和name=‘ed’这部分是通过参数传过来的,使用参数传递时就要注意以下两个问题。
首先,是参数不要使用引号括起来。比如如下形式是错误的(使用引号),将报错sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such column
table_and_column_name = "User" filter = "name='ed'" our_user = session.query(table_and_column_name).filter_by(filter).first()
其次,对于有等号参数需要变换形式。如下去掉了引号,对table_and_column_name没问题,但filter = (name='ed')这种写法在python是不允许的
table_and_column_name = User # 下面这条语句不符合语法 filter = (name='ed') our_user = session.query(table_and_column_name).filter_by(filter).first()
对参数中带等号的这种形式,现在能想到的只有使用filter代替filter_by,即将sql语句中的=号转变为python语句中的==。正确写法如下:
table_and_column_name = User filter = (User.name=='ed') our_user = session.query(table_and_column_name).filter(filter).first()
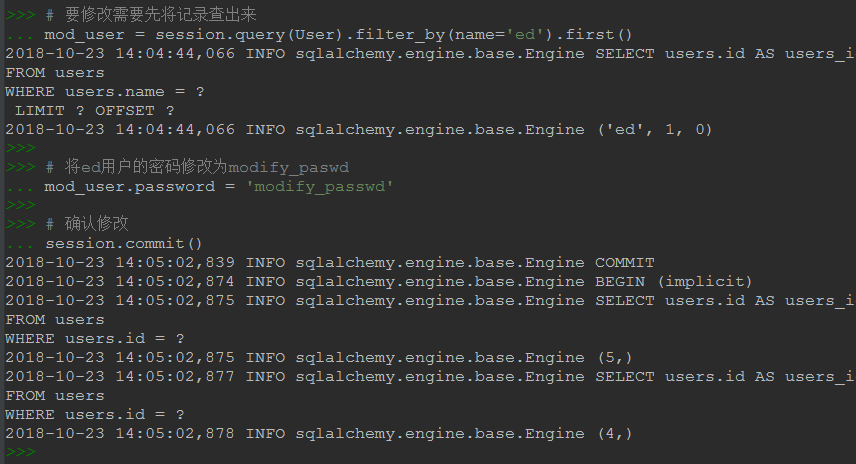
2.8 改(修改users表中的记录)
# 要修改需要先将记录查出来 mod_user = session.query(User).filter_by(name='ed').first() # 将ed用户的密码修改为modify_paswd mod_user.password = 'modify_passwd' # 确认修改 session.commit() # 但是上边的操作,先查询再修改相当于执行了两条语句,和我们印象中的update不一致 # 可直接使用下边的写法,传给服务端的就是update语句 # session.query(User).filter_by(name='ed').update({User.password: 'modify_passwd'}) # session.commit() # 以同schema的一张表更新另一张表的写法 # 在跨表的update/delete等函数中指定synchronize_session='fetch'表示先进行一次查询再更新/删除,synchronize_session=Fale表示直接更新/删
# 而且,比如update table_name where id = 10, 并不是先查一下where id = 10,而是把表中所有的id值遍历查一轮,这导致当记录数以十万百万计时update会非常慢,暂不能理解其精髓建议update都直接synchronize_session=False # 一定要指定,不然报错Specify 'fetch' or False for the synchronize_session parameter # session.query(User).filter_by(User.name=User1.name).update({User.password: User2.password}, synchronize_session=False) # 以一schema的表更新另一schema的表的写法 # 写法与同一schema的一样,只是定义model时需要使用__table_args__ = {'schema': 'test_database'}等形式指定表对应的schema
2.9 删(删除users表中的记录)
# 要删除需要先将记录查出来 del_user = session.query(User).filter_by(name='ed').first() # 打印一下,确认未删除前记录存在 del_user # 将ed用户记录删除 session.delete(del_user) # 确认删除 session.commit() # 遍历查看,已无ed用户记录 for user in session.query(User): print(user) # 但上边的写法,先查询再删除,相当于给mysql服务端发了两条语句,和我们印象中的delete语句不一致 # 可直接使用下边的写法,传给服务端的就是delete语句 # session.query(User).filter_by(name='ed').first().delete()

2.10 where过滤条件写法
-- 单一条件 where column_name = 'value' ---- .filter(Class.column_name == "value") where column_name is null ---- .filter(Class.column_name.is_(None)) where column_name is not null ---- .filter(Class.column_name.isnot(None)) -- 组合条件,与或 from sqlalchemy import and_,or_ where column_name1 = 'value1' and column_name2 = 'value2' ---- .filter(and_(Class.column_name1 == "value1", Class.column_name2 == "value2")) where column_name1 = 'value1' or column_name2 = 'value2' = 'value' ---- .filter(or_(Class.column_name1 == "value1", Class.column_name2 == "value2"))
2.11 直接执行SQL语句
虽然使用框架规定形式可以在一定程度上解决各数据库的SQL差异,比如获取前两条记录各数据库形式如下。
# mssql/access
select top 2 * from table_name;
# mysql
select * from table_name limit 2;
# oracle
select * from table_name where rownum <= 2;
但框架存消除各数据库SQL差异的同时会引入各框架CRUD的差异,而开发人员往往就有一定的SQL基础,如果一个框架强制用户只能使用其规定的CRUD形式那反而增加用户的学习成本,这个框架注定不能成为成功的框架。直接地执行SQL而不是使用框架设定的CRUD虽然不是一种被鼓励的操作但也不应被视为一种见不得人的行为。
# 正常的SQL语句
sql = "select * from users"
# sqlalchemy使用execute方法直接执行SQL
records = session.execute(sql)
三、ORM的作用(20200313更新)
说实话在很长一段时间里,我总感觉直接写sql挺简单明了的,ORM一顿操作下来似乎还增加了工作量。百度了半天也没找到感觉能解释为什么那么多人推崇他的原因,请教一位做开发的同学。
他说在面象对象编程中我们常把一个对象定义成一个类,没有ORM时,从数据库读取数据要写代码把记录转成对象(如User.username = row[0][0])、向数据库插入数据要写代码把对象转成记录(如column_username=User.username),每次读/写都要转一次就很麻烦。另外多表关联的时候直接的sql拼接会显得很复杂,ORM的写法更直观(这点暂时还没切身感受)。
参考:
https://docs.sqlalchemy.org/en/latest/orm/tutorial.html
https://stackoverflow.com/questions/34675604/sqlacodegen-generates-mixed-models-and-tables

 浙公网安备 33010602011771号
浙公网安备 33010602011771号