
Solr安装使用教程
一、安装
1.1 安装jdk
solr是基于lucene而lucene是java写的,所以solr需要jdk----当前安装的solr-7.5需要jdk-1.8及以上版本,下载安装jdk并设置JAVA_HOME即可。
jdk下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
1.2 安装solr
下载solr,然后解压即可,windows和linux都可以下.tgz(.tgz本质是.tar.gz)和.zip解压出来都一样的。
solr下载地址:http://lucene.apache.org/solr/downloads.html
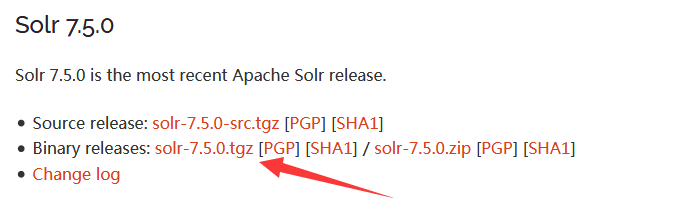
要注意图中的链接是下载页面的链接并不是solr文件的链接,直接wget链接就报gzip: solr-7.5.0.tgz: not in gzip format或End-of-central-directory signature not found.了。
1.3 设置系统资源限制
设置最大进程数t和打开文件数为65000(可能其他一些资源也要修改但我安装时没见有其他问题,文档也没看到专门说明)
ulimit -u 65000
ulimit -n 65000
二、solr基本用法
对于没用过的新手而言,首先最关心的是怎么运行起来看这东西长什么样其他什么高级用法后而再说,这里我们就来做这件事。
2.1 启停
进入解压后文件的bin目录,执行:
# 启动 ./solr start # 停止 ./solr stop
solr默认拒绝以root身份启动,root加-force选项可以启动,但后续进行操作(如创建核心等)还是会有问题,推荐使用普通用户动。
启动完成后默认监听8983端口,访问可见界面如下

2.2 solr核心(core)创建与删除
在上面启动起来的页面可以看到solr就是就是这么一个界面简陋的东西----页面简单(没几个页面)加布局丑陋。
solr中一个核心(core)相当于一个搜索引擎,然后上传文件时也是上传到指定核心;solr可以建立多个solr。solr默认没有core,我们先来创建一个core。
通过命令创建和删除core:
# 创建core,-c指定创建的core名 ./solr create -c test_core1 # 删除core,-c指定删除的core名 ./solr delete -c test_core1
完成后回刷新solr界面,点击下拉“Core Selector”即可看到刚才建立的core,选择core即可进入core的管理界面,如下图。
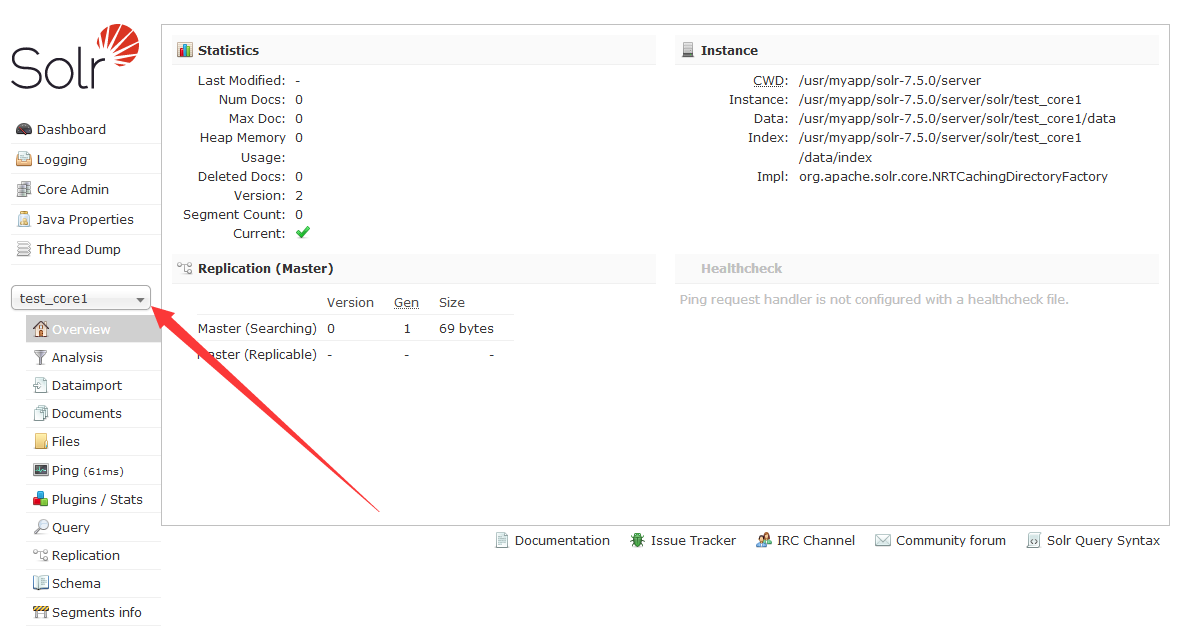
2.3 上传文件创建索引
上一步相当于我们的搜索引擎系统创建完闭,但此是搜索引擎中是没有内容的,我们这里就给它上传文件。以example/exampledocs下文件为例
./post -c test_core1 ../example/example
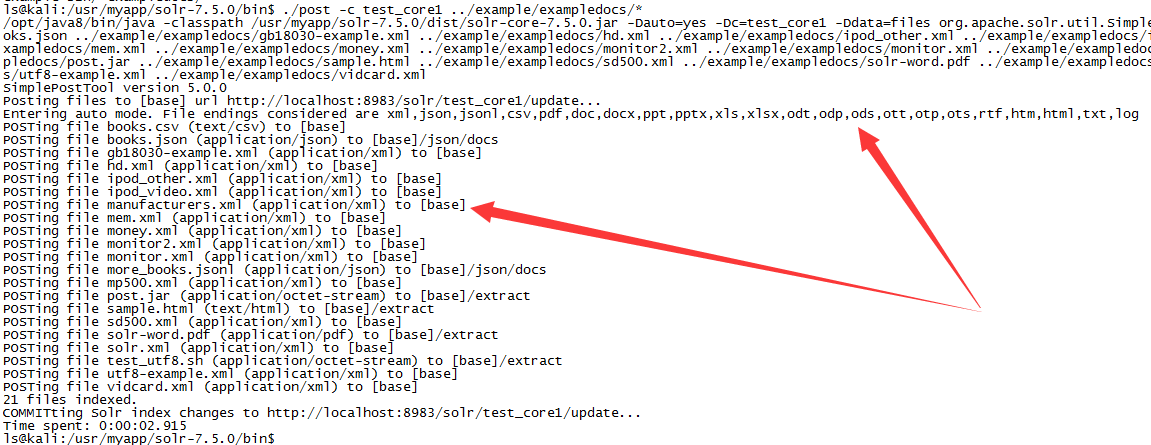
2.4 查询
完成后切换到Query页面,直接点击”Execute Query“按钮,在右侧即出现一些已建立的索引
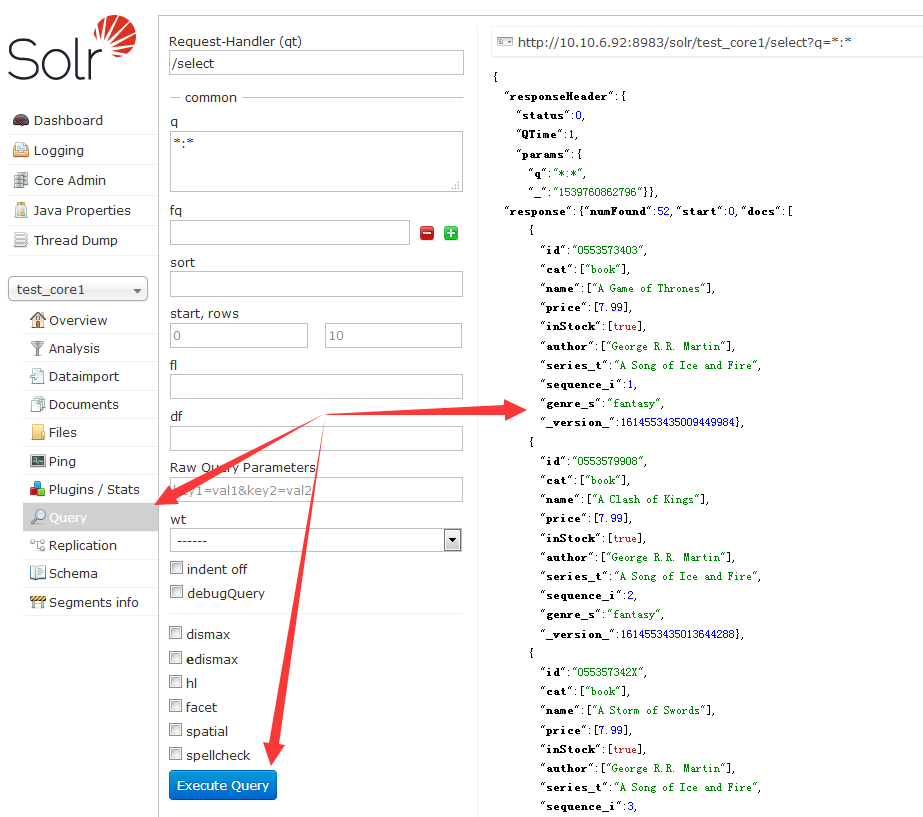
查询页面各参数说明如下:
| 参数 | 描述 |
|---|---|
| q | 这是Apache Solr的主要查询参数,只输入值有时不能搜索,使用键值形式最稳妥 |
| fq | 这个参数表示Apache Solr的过滤器查询,将结果集限制为与此过滤器匹配的文档。 |
| start | start参数表示页面的起始偏移量,此参数的默认值为0。 |
| rows | 这个参数表示每页要检索的文档的数量。此参数的默认值为10。 |
| sort | 这个参数指定由逗号分隔的字段列表,根据该列表对查询的结果进行排序。 |
| fl | 这个参数为结果集中的每个文档指定返回的字段列表。 |
| wt | 这个参数表示要查看响应结果的写入程序的类型。 |
2.4 solr有什么用
经常听说solr是一个全文搜索引擎,效果类似百度、谷歌。我对这句话的理解是我们可以向slor传一个文档它就会对文档进行分词,然后对每个词建立索引,然后我们搜索某个词就会出现所有出现过这个词的位置。
然而正如大多数it概念都是炒作认识其本质会大失所望一样,solr的”全文索引“和”类似百度“也是个炒作的概念(如果我没理解错的话)。
2.4.1 solr不支持非结构化数据
我们看到solr声称支持”xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log“等一堆格式,但其所谓的支持并不是我们认为中的”读取文件/分词/和索引“,只是支持把文件传上去然后给文件名建个索引----那我觉得solr完全可以直接声称自己支持所有文件格式。
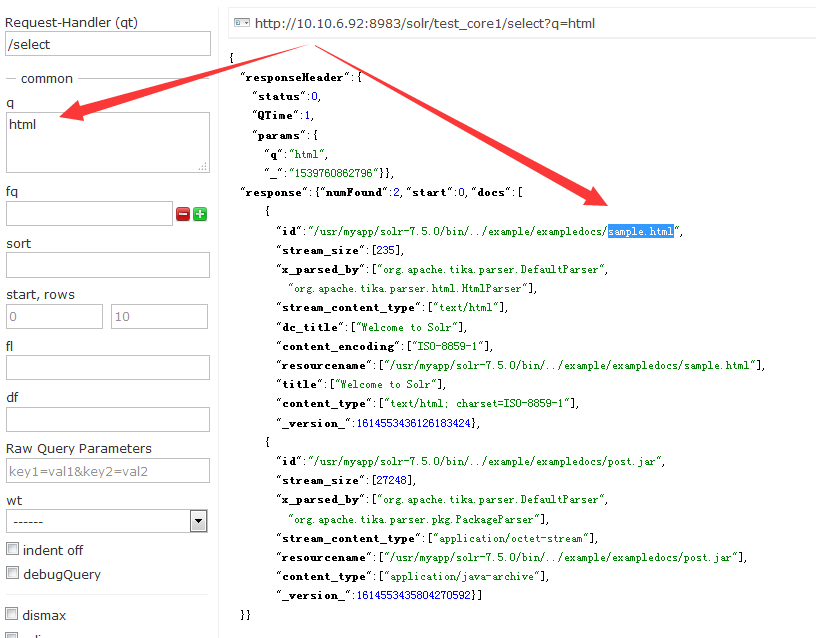
上传的文件中有个sample.html文件,我们输入html查找一下,返回结果如下。相当于就是一个文件(属性)的索引,html文件内容的索引?对不起那里没有的。(这就是所谓的支持html?)
2.4.2 solr只支持固定格式的结构化数据
solr虽然不支持html/txt/pdf等非结构化文件内容的索引,但如果支持xml/json等结构化文件也还行啦。
不好意思我们上传了的xml/json文件内容确实是建立了索引,但是其格式得固定的。
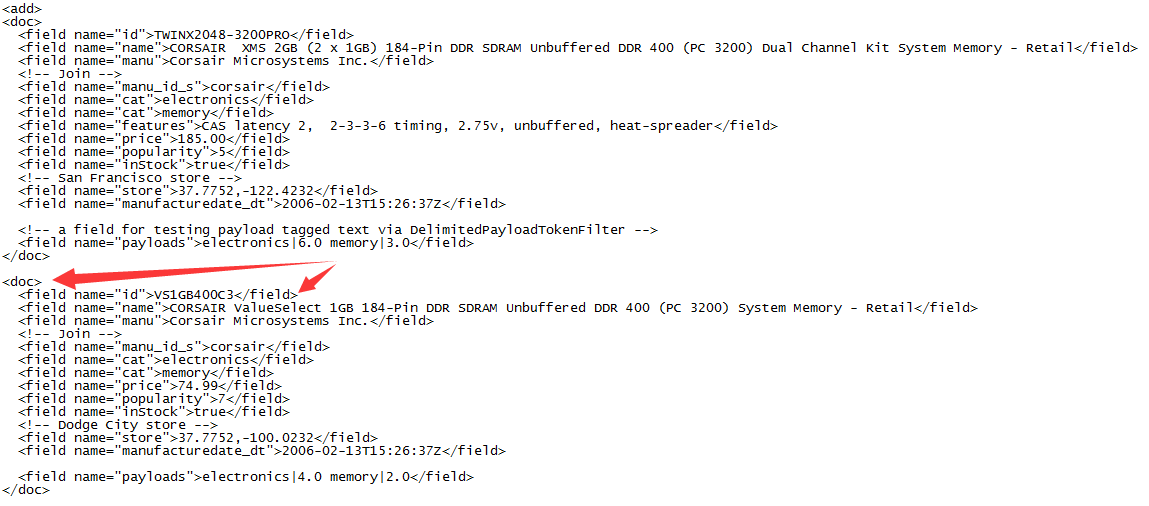
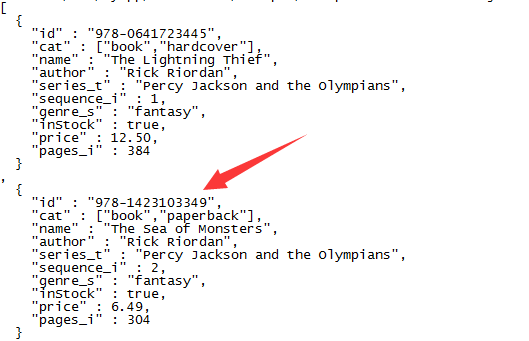
上图id为978-1423103349的索引在solr web页面返回结果如下,就相当原样输出。
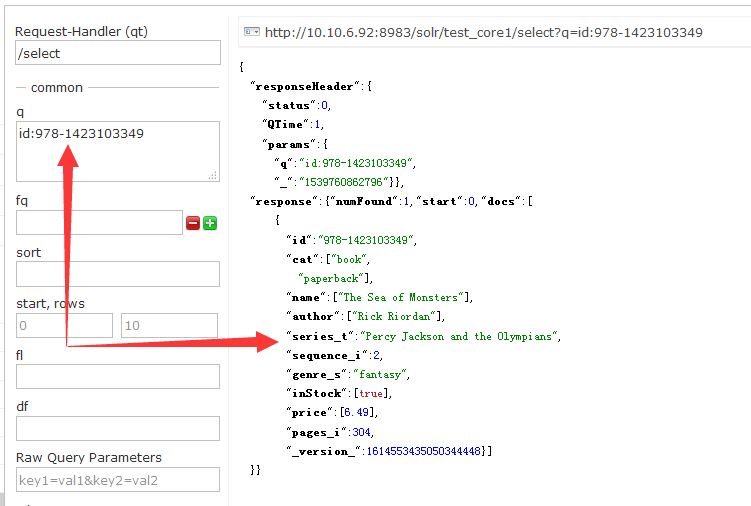
总的就是说需要明确给出id值,而且所有索引域都是自己都是起好名字,然后设定好值。
2.4.3 solr用在哪里
当然txt等非结构化文件也不是完全没可能导入,比如采用这种方法将txt文件以行为单位进行切割,然后为给每行生成一个id这样改造成结构化后就能导入了。
但这种还是将非结构化转成结构化,非结构化还是无法直接导入;所以solr根本不是百度而是个数据库(比如mysql或者更像NoSQL),百度就不要再想了。
solr的的使用一是使用代码将结构化数据转为结构化数据后导入数据,二是从数据导入数据。但solr就像个数据库那为什么不直接用数据库呢,何必新弄出个东西?solr可以和hadoop配合?hive不更好能和haddop配合吗?所以,我现在也不是很懂solr有什么意义。
在日志监测系统ELK中,Logstash负责读取和格式化(结构化)各种数据发送给ElasticSearch,ElasticSearch就和solr是一样的东西,而kibana从ElasticSearch读取数据进行展示。
参考:
http://lucene.apache.org/solr/guide/7_5/solr-tutorial.html#solr-tutorial

 浙公网安备 33010602011771号
浙公网安备 33010602011771号