
MySQL基本使用教程
一、结构类操作
1.1 连接数据库
1.1.1 命令连接数据库
# 基础格式
mysql [OPTIONS] [database_name]
# 常用参数格式
mysql [-h<ip>] [-u<username>] [-p<password>] [-P<port>] [-e<command>] [database_name]
说明:选项及其参数间可以有空格也可以没空格;-p可直接接密码也可以后边要求输入时再输入;密码有$等元字符时要用单引号括起来防止被解析掉;-e后的的命令一般都有空格所以一般都用引号括起来。
1.1.2 断开数据库连接
-- 方式一 exit -- 方式二 quit
1.1.3 常用图形界面客户端
Navicat:暂时见到最好用的mysql客户端;原来有免费版本Navicat Lite现在已经不提供了。
Workbench:MySQL官方客户端,各方面都还可以;最大的糟点大概是界面有点丑。
HeidiSQL:暂时见到的开源免费还算能用的mysql客户端;最让人难受的是数据库列表和打开后的数据库属两个窗口。
phpMyAdmin:web形式的客户端比较受欢迎,但php写的也有就语言局限性。
1.2 库操作
1.2.1 创建数据库
-- 基础用法
create database <database_name>;
-- 指定utf8编码格式
create database <database_name> character set utf8 collate utf8_general_ci;
1.2.2 删除数据库
drop database <database_name>;
1.2.3 修改数据库
应该来讲,修改数据库我们最希望的是修改数据库名,但mysql并没有提供直接的修改数据库名的操作(现在的修改本质上都是新建一个数据库然后把表导过去),只能改改默认编码之类的。
alter database <database_name> character set = 'utf8' ;
1.2.4 查看现有数据库
-- 查看所有数据库 show databases; -- 查看当前使用的数据库 select database(); -- 查看数据库创建信息 show create database database_name;
1.2.5 使用数据库
use <database_name>;
1.3 表操作
1.3.1 创建数据表
-- 基础创建格式 create table table_name(column_1_name_1 column_1_type, column_2_name_2 column_1_type) -- 创建示例;习惯在每个字段后回车换行 create table if not exists test_table( id int unsigned auto_increment, username varchar(100) not null, password varchar(100) not null, primary key(id) )default charset=utf8;
1.3.2 删除数据表
drop table <table_name>;
1.3.3 修改数据表
-- 重命令数据表 rename table <old_table_name> to <new_table_name>;
1.3.4 查看数据表
show tables [ from database_name ];
1.4 字段操作
1.4.1 增加字段
alter table <table_name> add [column] <column_name> <column_type> [first | after ready_column];
1.4.2 删除字段
alter table <table_name> drop [column] <column_name>;
1.4.3 修改字段
-- 修改字段名 alter table <table_name> rename column <old_column_name> to <new_column_name>; -- 修改字段类型 alter table <table_name> modify [column] <column_name> <new_column_type> [first | after ready_column]; -- 同时修改字段名和字段类型 alter table <table_name> change [column] <old_column_name> <new_column_name> <new_column_type> [first | after ready_column];
1.4.4 查看字段
show columns from <table_name>; desc <table_name>;
1.5 记录操作
1.5.1 插入记录
insert [into] <table_name> [column_name_1,column_name_2] values (value_10,value_20) [,(value_11,value_21)];
1.5.2 删除记录
-- 删除指定记录 delete from <table_name> [ where column_name = 'value' ]; -- 删除所有记录 -- delete是DDL(Data Manipulation Language),truncate是DML(Data Definition Language)。 -- 两者的区别有很多分不太清,delete不重置自增长字段,truncate会重置自增长字段 delete * from <table_name>; truncate table <table_name>; -- 删除重复记录 -- 第一步,创建格式和原表一样的临时表 CREATE TABLE t_source_copy LIKE t_source; -- 第二步,通过group by把唯一的一条数据插入临时表 -- 允许重复的所有字段都要参与group by;一般除关键字外都参与 INSERT INTO t_source_copy SELECT * FROM t_source GROUP BY column_names; -- 第三步,删除原表 DROP TABLE t_source; -- 第四步,把临时表重命名为原表名 ALTER TABLE t_source_copy RENAME TO t_source;
1.5.3 修改记录
update <table_name> set <column_name> = <value> [ where column_name = "value" ];
1.5.4 查看记录
select * from <table_name> [ where column_name = "value" ]; -- 某列唯一 select distinct column_name from <table_name> [ where column_name = "value" ]; -- 某列唯一计数 select count( distinct column_name ) from <table_name> [ where column_name = "value" ]; -- 多列组合唯一 select distinct column_name1[, column_name2] from <table_name> [ where column_name = "value" ]; -- 多列组合唯一计数(需要5.7以后版本才支持,之前的版本会先去掉column_name1一样的记录,再去掉column_name2相同的记录,与我们预期不符) select count(distinct column_name1[, column_name2]) from <table_name> [ where column_name = "value" ];
二、导入导出数据操作
2.1 导出数据
-- 方法一:使用into outfile导出数据 -- 导出默认格式:文件本件,字段以\t分隔,行以\n分隔 -- 只指定文件名不具体给出目录时,文件会保存到mysql配置的导出目录下 select * from table_name into outfile "<file_path>"; -- 保存成csv select * from table_name fields terminated by ',' optionally enclosed by '"' lines terminated by '\n'; -- 方法二:使用重定向> -- 如果数据库不允许导出文件,那么只能-e命令行查然后再重定向到文件 -- 但这种方式没法指定terminated,即也不能输出成csv文件。折中的办法是输出成txt然后复制到excel中再保存成csv mysql -h ip -u user -p password db_name -e "select * from table_name" > file_path -- 方法三:使用mysqldump导出数据 -- 导出默认格式:.sql文件 -- 不指定数据库名时默认导出所有数据库 mysqldump -u<username> -p<password> [--databases <database_names>] > <file_path> mysqldump -u<username> -p<password> [--databases <database_names>] --result-file <file_path>
2.2 导入数据
-- 方法一:使用mysql命令导入sql语句(.sql)文件 mysql -u<username> -p<password> < <file_path> -- 方法二:登录数据库后使用source入sql语句(.sql)文件 -- 当然也可以使用mysql -u<username> -p<password> -e <command>转成shell命令形式 source <file_path> -- 方法三:登录数据库后使用load data导入.cvs等格式文件 -- 当然也可以使用mysql -u<username> -p<password> -e <command>转成shell命令形式 -- local是指文件在登录mysql的那台机器上 -- 默认.cvs格式,即字段分隔符为,行分隔符为换行符(具体是\r\n还是\n还是\r看你系统) -- 对于数据格式,导入时mysql会尽最大可能将导入的数据转成字段的格式 -- 如果导入的字段值中包含分隔符,此种情况导入前应处理,不然会误导mysql的分隔判断 load data local infile <file_path> into table <table_name>; -- 自定义字段分隔符和行分隔符 load data local infile <file_path> into table <table_name>[(column_names)] fields terminated by ':' lines terminated by '\n'; -- 如果导入的文件中某个字段没有值(或者想让自增长字段自增长),则将该字段留空即可(如,,) -- 如果导入的文件中某个字段对应的位置是有值的但并不想导入数据库,则在column_names位置使用@column_name形式指示导入时跳过该字段即可 -- 方法四:使用mysqlimport导入.cvs等格式文件 -- mysqlimport从功能上来说只是load data的一个shell命令形式 mysqlimport -u<username> -p<password> --local <database_name> <file_path> mysqlimport -u<username> -p<password> --local --fields-terminated-by "," --lines-terminated-by "\n" <database_name> <file_path>
三、权限类操作
3.1 授权
-- create只创建用户,该用户没有任何如增删改查的权限 create user <username>@<ip> [identified by <password>]; -- grant先创建用户,后又可给用户赋权 -- with grant option表示允许该用户将其所拥有的权限,赋给其他人 grant <all|create|drop|alter|show|insert|delete|update|select> on <database_name>.<table_name> to <username|rolename>@<ip> [identified by <password>] [with grant option]; -- 给角色增加权限 grant <all|create|drop|alter|show|insert|delete|update|select> on <database_name>.<table_name> to <rolename>; -- 给用户增加角色 grant <rolename> to <username>@<ip>;
3.2 回收权限
-- 从用户回收权限 revoke <all|create|drop|alter|show|insert|delete|update|select> on <database_name>.<table_name> from <username|rolename>@<ip>; -- 从角色回收权限 revoke <all|create|drop|alter|show|insert|delete|update|select> on <database_name>.<table_name> from <rolename>; -- 从用户回收角色 revoke <rolename> from <username>@<ip>;
3.3 修改用户密码
-- 查看当前登录用户 select user(); -- 查看所有用户 select user,host from mysql.user; -- 修改当前用户密码 set password = <password>; -- 修改指定用户密码 set password for <username>@<ip> = <password>; -- 修改当前用户密码 alter user user() identified by <password>; -- 修改指定用户密码 alter user <username>@<ip> identified by <password>; -- 5.7之前版本 update mysql.user set password=PASSWORD(<password>) where user=<username>; -- 5.7及之后版本 update mysql.user set authentication_string=PASSWORD(<password>) where user=<username>;
四、其他常用操作
-- 查看数据库版本 select version(); -- 查看连接数 show status where variable_name = 'Threads_connected'; show global status like "Threads_connected"; -- 查看具体连接 show processlist; -- show processlist出来的id是服务端给客户端连接分配的id,而不是客户端在系统中的进程id -- 这是比较容易理解的,因为如果是不同机器那服务端显然无法了解客户端在系统中的进程id -- 所以关闭连接的kill操作,应该在mysql会话中进行,而不是在系统shell中进行 kill <processlist_id>; -- 查看在本机客户端中执行过的mysql命令 cat ~/.mysql_history -- 大多变量可在my.cnf文件中配置默认值,但下划线要改成杠 -- mysql配置文件中,既允许不同文件间有相同节区,也允许一个文件有重复的节区,最后汇总去重使用 -- 查看变量 show [global|session] variables [like <pattern>]; -- 设置变量值,但set并不写入文件即重启后失效 set <variable_name> = <value>; -- 查看支持的编码 show character set [ likt <pattern> ]; -- 服务端使用什么编码存并不那么重要,只要客户端使用正确的编码即可正确显示 -- 将character_set_client, character_set_connection及character_set_results三个变量设为给定编码 set names 'utf8'; -- 以某个字段进行分组并统计数量 select count(*),<column_name> from <table_name> group by <column_name> -- 以某个字段的某几个字符进行分组并统计数量;以前几位用left(),以中间几位字符用substr(),以右边几位用right() select count(*),<left(column_name,char_index) [as column_name]> from <table_name> group by <left(column_name,char_index)> -- 行列转置显示。 -- 当记录太长时会产生换行,此时字段和字段值关系难以分清,这时我们可以使用\G将行列进行转置 -- mysql中\g作用等效于分号,\G除了分号作用外还进行行列转置 -- 因为\G已启到分号作用,所以不需要再加分号;如果加上就相当于一条空语句,进而报“ERROR: No query specified” select * from <table_name> limit 1 \G -- 在表上做两层查询 select * from (select * from test_table) as a where a.column1 = 'xxx' -- 将第n列相同的记录,的第m列也修改为相同值 update test_table1,(select n,m from test_table1 where m != '' group by n) as b set test_table1.m = b.m where test_table1.m = '' and test_table1.n = b.n; -- 嵌套 -- 凡是表名的位置,都可以使用(select xxx from xxx)来替换实现嵌套 -- having子句 -- where只能针对原始的字段进行过滤,不能对group by后计算出的字段进行过滤;要对group by后计算出的字段进行过滤就得用having
select count(*) as total_count,ip from some_table group by ip having total_count > 3;
-- 查询某个月最后一天/某个月共有多少天
-- select last_day('2012-02-22'), day(last_day('2012-02-22'));
-- ERROR 1175 (HY000): You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column.
set sql_safe_updates = 0;
五、MySQL unix socket说明
装mysql的时候会经常能看到/var/lib/mysql/mysql.sock及类似的文件,之前一直不知道这个有什么用。研究一下发现这就是UNIX domain sockets使用的通信管道。
socket分AF_UNIX、AF_INET和AF_INET6三个协议族,其中AF_INET是常见的tcp/ip,AF_INET6是ipv6,AF_UNIX就是UNIX domain sockets。
AF_UNIX借用本地文件作为通信媒介,较AF_INET可省去差错控制等流程,本地通信使用AF_UNIX通信效率更高。
当不使用-h参数指定ip时,mysql就认为是登录本地mysql,所以使用UNIX domain sockets(AF_UNIX):
(也就需要给它指定一个作为通信媒介的文件,不然mysql就使用默认的/var/lib/mysql/mysql.sock。所以有时报无法创建/var/lib/mysql/mysql.sock的错误也就可以理解了,这种情况一般是使用非root账号登录操作系统然后登录本地mysql)
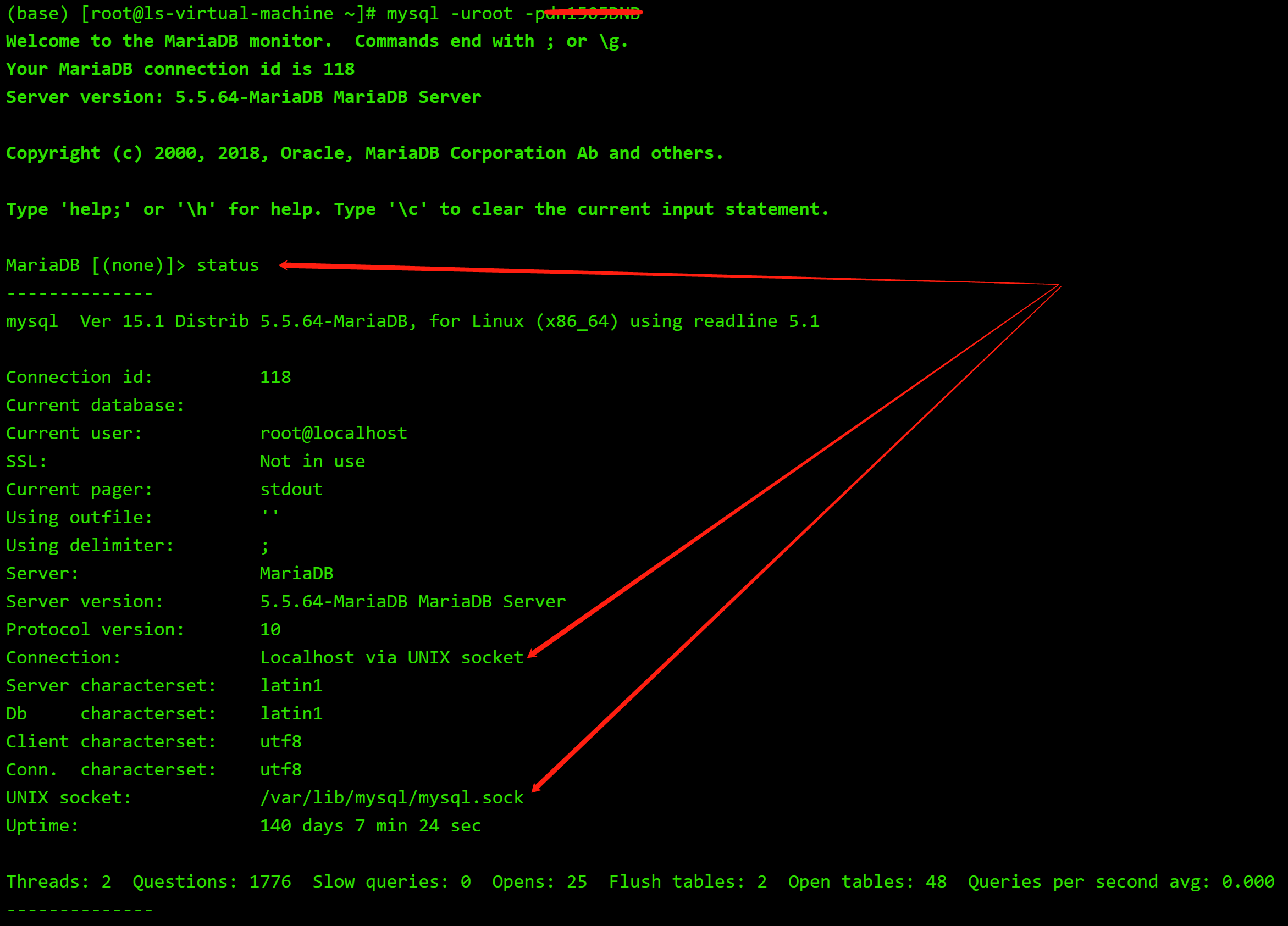
当使用-h指定服务器时,就认为是连接远程服务器,使用tcp/ip(AF_INET)进行通信:
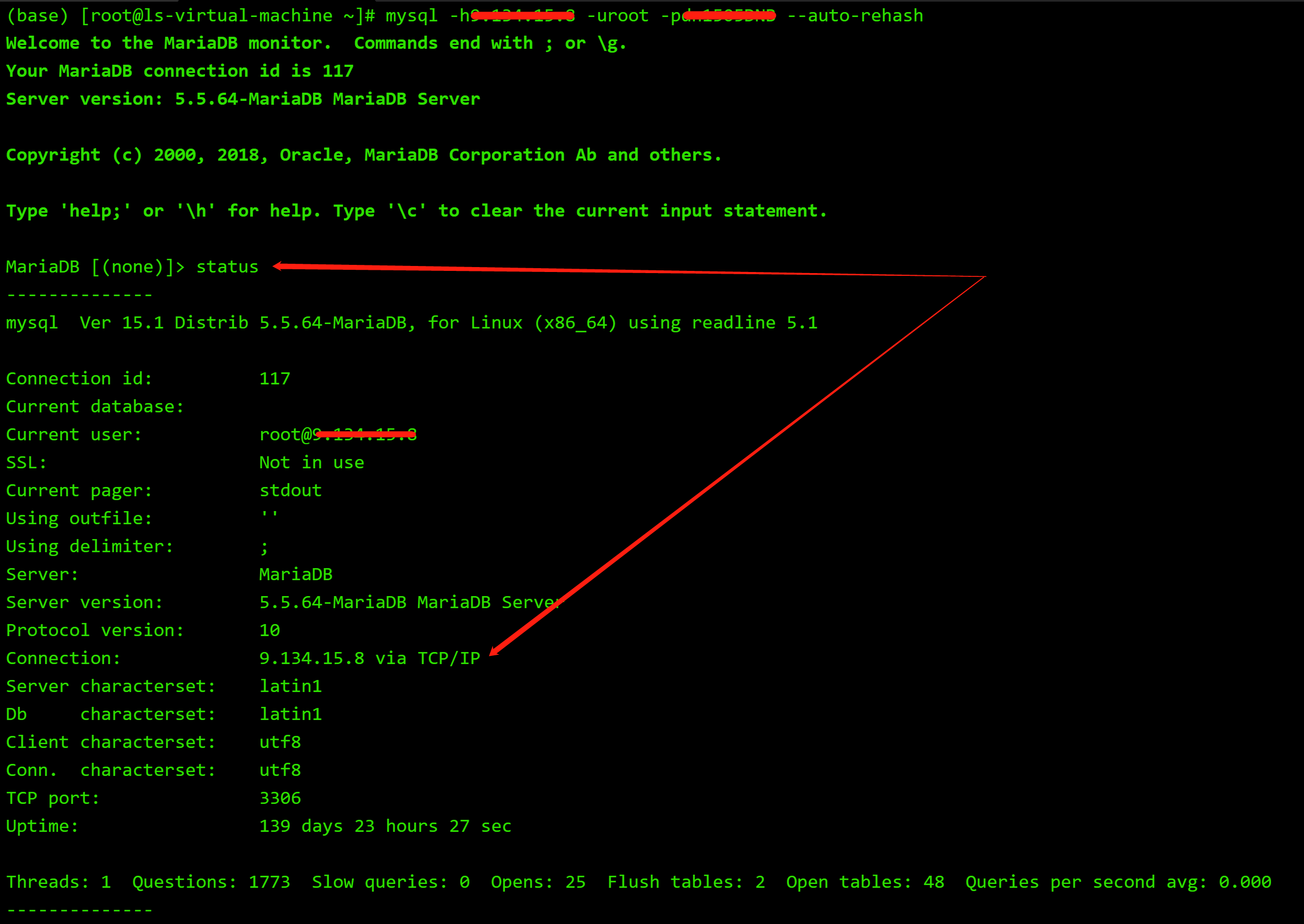
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号