
rabbitmq 相关概念
AMQP
Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
消息模型
所有 MQ 产品从模型抽象上来说都是一样的过程:
消费者(consumer)订阅某个队列。生产者(producer)创建消息,然后发布到队列(queue)中,最后将消息发送到监听的消费者。

基本概念

- Broker
消息队列服务器实体。如部署RabbitMQ应用。 - Virtual Host
虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个 vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时指定,RabbitMQ 默认的 vhost 是 / 。
注意:通过amqp://--- 配置时,如果virtual host名中包含/,需要使用转义字符%2F。 - Connection
与RabbitMQ服务器的Tcp连接。 - Channel
基于Connection建立的信道。
信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内地虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。 - Message
消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。 - Publisher
消息的生产者,也是一个向交换器发布消息的客户端应用程序。 - Consumer
消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。 - Exchange
交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。 - Routing Key
用于消息队列和交换器之间的关联。
若使用交换机,发布消息时,只需指定exchange即可。由交换机,按照routing key的匹配规则,自动分发至Queue中。
**只有Topic模式下,routing key才可使用通配符(#,*) ** - Queue
消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
Exchange的类型
fanout
每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去。fanout 交换器不处理路由键,只是简单的将队列绑定到交换器上,每个发送到交换器的消息都会被转发到与该交换器绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型转发消息是最快的。

direct
消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器就将消息发到对应的队列中。路由键与队列名完全匹配,如果一个队列绑定到交换机要求路由键为“dog”,则只转发 routing key 标记为“dog”的消息,不会转发“dog.puppy”,也不会转发“dog.guard”等等。它是完全匹配、单播的模式。

topic
topic 交换器通过模式匹配分配消息的路由键属性,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。它同样也会识别两个通配符:符号“#”和符号“”。#匹配0个或多个单词,匹配不多不少一个单词。

RabbitMQ集群
RabbitMQ 最优秀的功能之一就是内建集群,这个功能设计的目的是允许消费者和生产者在节点崩溃的情况下继续运行,以及通过添加更多的节点来线性扩展消息通信吞吐量。RabbitMQ 内部利用 Erlang 提供的分布式通信框架 OTP 来满足上述需求,使客户端在失去一个 RabbitMQ 节点连接的情况下,还是能够重新连接到集群中的任何其他节点继续生产、消费消息。
相关概念
元数据
RabbitMQ 会始终记录以下四种类型的内部元数据:
- 队列元数据
包括队列名称和它们的属性,比如是否可持久化,是否自动删除 - 交换器元数据
交换器名称、类型、属性 - 绑定元数据
内部是一张表格记录如何将消息路由到队列 - vhost 元数据
为 vhost 内部的队列、交换器、绑定提供命名空间和安全属性
至少需要一个磁盘节点
- 元数据信息存储在磁盘节点,如果有节点崩溃,其它节点可共享元数据信息
- 磁盘节点崩溃,集群只能起到路由的作用
3种械式
rabbitmq有3种模式,但集群模式是2种。详细如下:
- 单一模式
即单机情况不做集群,就单独运行一个rabbitmq而已。 - 普通模式
默认模式,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。当rabbit01节点故障后,rabbit02节点无法取到rabbit01节点中还未消费的消息实体。如果做了消息持久化,那么得等rabbit01节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。 - 镜像模式
把需要的队列做成镜像队列,存在与多个节点属于RabbitMQ的HA方案。该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
docker部署
参考文档 docker部署RabbitMQ集群 - Alan6 - 博客园
1、拉镜像
docker pull rabbitmq:3.9.7-management
2、运行容器
docker run -d --hostname rabbit_host1 --name rabbitmq1 -p 15672:15672 -p 5672:5672 -p 4369:4369 -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' rabbitmq:3.9.7-management
docker run -d --hostname rabbit_host2 --name rabbitmq2 -p 5673:5672 --link rabbitmq1:rabbit_host1 -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' rabbitmq:3.9.7-management
docker run -d --hostname rabbit_host3 --name rabbitmq3 -p 5674:5672 --link rabbitmq1:rabbit_host1 --link rabbitmq2:rabbit_host2 -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' rabbitmq:3.9.7-management
主要参数:
-p 15672:15672 management 界面管理访问端口
-p 5672:5672 amqp 访问端口
--link 容器之间连接
Erlang Cookie 值必须相同,也就是一个集群内 RABBITMQ_ERLANG_COOKIE 参数的值必须相同。因为 RabbitMQ 是用Erlang实现的,Erlang Cookie 相当于不同节点之间通讯的密钥,Erlang节点通过交换 Erlang Cookie 获得认证。
修改hosts
- Windows OS
路径:C:\Windows\System32\drivers\etc\hosts - Linux
路径:/etc/hosts
127.0.0.1 rabbit_host1 rabbit_host2 rabbit_host3
3、加入节点到集群
设置节点1:
docker exec -it rabbitmq1 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
exit
设置节点2,加入到集群:
docker exec -it rabbitmq2 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit_host1
rabbitmqctl start_app
exit
设置节点3,加入到集群:
docker exec -it rabbitmq3 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit_host1
rabbitmqctl start_app
exit
4、Policy设置
4.1、策略policy概念
使用RabbitMQ镜像功能,需要基于RabbitMQ策略来实现,策略policy是用来控制和修改群集范围的某个vhost队列行为和Exchange行为。策略policy就是要设置哪些Exchange或者queue的数据需要复制、同步,以及如何复制同步。
为了使队列成为镜像队列,需要创建一个策略来匹配队列,设置策略有两个键“ha-mode和 ha-params(可选)”。ha-params根据ha-mode设置不同的值,下表说明这些key的选项。

4.2、添加策略
登录rabbitmq管理页面 ——> Admin ——> Policies ——> Add / update a policy

name:随便取,策略名称
Pattern:^ 匹配符,只有一个^代表匹配所有
Definition:ha-mode=all 为匹配类型,分为3种模式:all(表示所有的queue)
或者使用命令:
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
4.3、查看效果
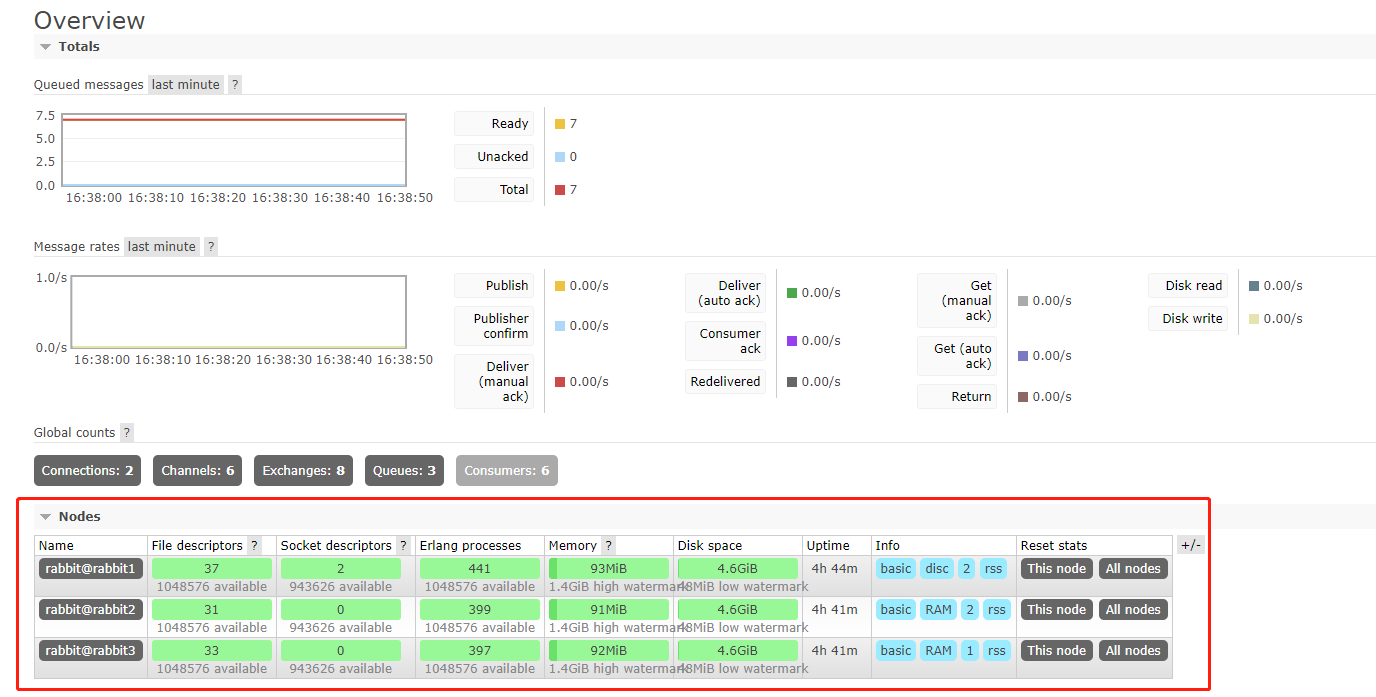
此策略会同步所在同一VHost中的交换器和队列数据。设置好policy之后,使用 http://ip:15672 再次进行访问,可以看到队列镜像同步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号