
spark并行查询
一、jdbc连接数据库
我们知道spark可以通过jdbc查询数据库,但是Spark 通过 JDBC 读取关系型数据库,默认查询全表,只有一个 Task 去执行查询操作,大量数据情况下,效率是很慢的。
这时,可以通过构造多个 Task 并行连接 数据库提升效率。
二、spark sql属性介绍
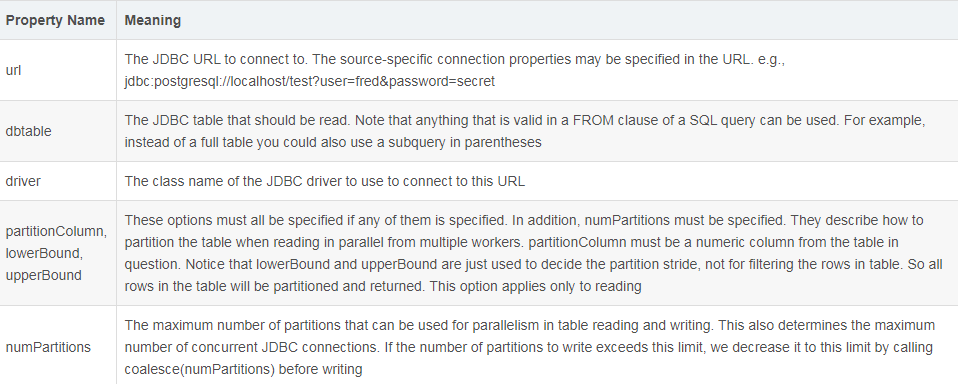
1、dbtable:表名,可以是真实存在的关系表,也可以是通过查询语句 AS 出来的表。其实只要是在 SQL 语句里,FROM 后面能跟的语句用在 dbtable 属性都合法,其原理就是拼接 SQL 语句,dbtable 会填在 FROM 后面。
2、numPartitions:读、写的最大分区数,也决定了开启数据库连接的数目。使用 numPartitions 有一点点限制, 如果指定了 numPartitions 大于1的值,但是没有指定分区规则,仍只有一个 task 去执行查询。
3、partitionColumn, lowerBound, upperBound:指定读数据时的分区规则。要使用这三个参数,必须定义 numPartitions,而且这三个参数不能单独出现,要用就必须全部指定。而且 lowerBound, upperBound 不是过滤条件,只是用于决定分区跨度。在分区的时候,会根据 numPartitions 将 lowerBound 和 upperBound 拆分成,然后并行去执行查询。
三、并行查询
并行查询大致有两种方式:
1、
val gpRDF = spark.read
.format("jdbc")
// .option("driver", "com.pivotal.jdbc.GreenplumDriver")
.option("driver", "org.postgresql.Driver")
.option("url", "jdbc:postgresql://host:5432/db?characterEncoding=utf-8")
.option("partitionColumn", "id")
.option("lowerBound", 1)
.option("upperBound", 3000000)
.option("numPartitions", 6)
.option("dbtable", "public.testdb")
.option("user", "user")
.option("password", "pwd")
.load()
2、
// 创建 numPartitions 个 task val registerDF = Range(0, numPartitions) .map(index => { spark .read .format("jdbc") .option("driver", "org.postgresql.Driver") .option("url", "jdbc:postgresql://host:5432;DatabaseName=testdb") .option("dbtable", s"(SELECT feature FROM public.t_timing_face_person WHERE person_id > ${stride * index} AND person_id <= ${stride * (index + 1)}) AS t_tmp_${index}") .option("user", "user") .option("password", "pwd") .load() }) .reduce((rdd1, rdd2) => rdd1.union(rdd2))
第一种方法可能导致数据倾斜,但是代码简单,对一些连续的分布键采用这种方法会有不错的效果;第二种方法是通过sql来控制,相对可控,相应的代码也相对复杂(主要是sql)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号