

列式存储kudu基于spark的操作
1、通过kudu客户端创建表
val kuduContext = new KuduContext("kuduMaster:7051",sc)
val sQLContext = new SQLContext(sc)
val kuduTableName = "spark_kudu_table"
val kuduOptions: Map[String, String] = Map(
"kudu.table" -> kuduTableName,
"kudu.master" -> "kuduMaster:7051")
// 检查要创建的表是否存在,若存在就删除
if (kuduContext.tableExists(kuduTableName)) {
kuduContext.deleteTable(kuduTableName)
}
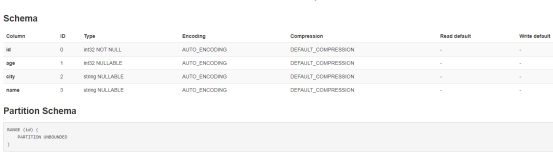
// 2. 配置schema
val kuduTableSchema = StructType(
// col name type nullable?主键不能为null
StructField("id", IntegerType , false) ::
StructField("age" , IntegerType, true ) ::
StructField("city", StringType , true ) ::
StructField("name", StringType , true ) :: Nil)
// 3. 指定主键
val kuduPrimaryKey = Seq("id")
// 4. 指定分区键以及副本数
val kuduTableOptions = new CreateTableOptions()
kuduTableOptions.
setRangePartitionColumns(List("id").asJava).
setNumReplicas(3)
// 5. 通过api建表
kuduContext.createTable(
// Table name, schema, primary key and options
kuduTableName, kuduTableSchema, kuduPrimaryKey, kuduTableOptions)
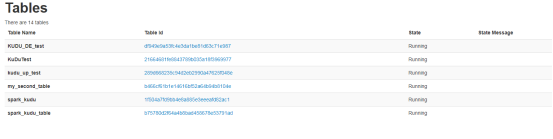
运行程序后再kudu的ui界面上就可以看见创建的表了,如图:浏览器访问你的kudumaster:8051
2、插入数据
//参数解释:frame:将要插入的数据转为dataframe ,kuduTableName:表名
kuduContext.insertRows(frame,kuduTableName)
或
df.write.options(Map("kudu.master"-> "kuduMaster:7051",
"kudu.table"-> kuduTable)).mode("append").kudu
3、删除数据
//删除表
kuduContext.deleteTable(kuduTableName)
//删除数据:将要删除的数据查询出来作为参数传入
kuduContext.updateRows(frame,kuduTable)
4、更新
//通过sql更新数据后调用api批量更新
val dataFrame = sQLContext.sql("select Name,city,AGE+3 as AGE from kudu_tem")
kuduContext.updateRows(dataFrame,kuduTable)
5、查
val kuduOptions: Map[String, String] = Map(
"kudu.table" -> kuduTable,
"kudu.master" -> "kuduMaster:7051")
val reader: DataFrame = sQLContext.read.options(kuduOptions).kudu
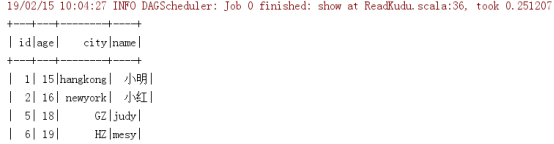
通过spark创建的表与impala创建的表有一定的区别。通过impala创建的表是不区分大小写的,impala会自动转为小写,而通过spark创建的表是区分大小写的。所以通过不同的途径操作kudu表时,要注意这一点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号