
flask项目——代码抽取
通常一个项目的启动文件为app.py或者manage.py,所以我们先将项目中启动文件的文件名进行修改。这里我修改为manage.py。
在立项准备的时候,我们在manage.py中写入了太多的内容,导致整个文件已经非常的臃肿了,所以,这里我们要对代码进行抽取,我们只让manage.py做一个程序的启动入口,而不是让所有代码都写入其中。
这里,我们自顶向下开始抽取。
1.配置文件抽取
1.1 在项目目录下新建config.py
1.2 将配置类从manage.py中拿到config.py中。(原来的代码不要直接剪切,复制到新文件中,然后将原来的注释掉,防止改错)
1.3 哪里报错改哪里
1.4 这里报红了所以我们导一下包

from redis import StrictRedis
还有这里
这里是因为找不到Config这个类了,被移到config.py这个文件里面了,我们导入一下
from config import Config
补充说明
封装代码的步骤:
- 确定哪些代码需要封装
- 确定要封装到哪里
- 将代码移动到指定位置
- 回看是否有错
- 如果有错就改错
- 改错后直接运行
- 注意点
- 切记不要一次封装太多代码
- 如果逻辑复杂,分批逐步封装
2.app信息抽取
2.1app的相关代码都是业务逻辑相关代码,所以,我们最好将其封装到业务逻辑部分中。
这里,我们需要新建一个Python Package的包,命名为info,以后里面就存储着业务逻辑相关代码。
这里,我们将标注的部分抽取到info的__init__中,因为业务逻辑只要一开始,就会优先执行__init__文件中的内容。
当把代码放入到__init__中,可以看到下面内容:
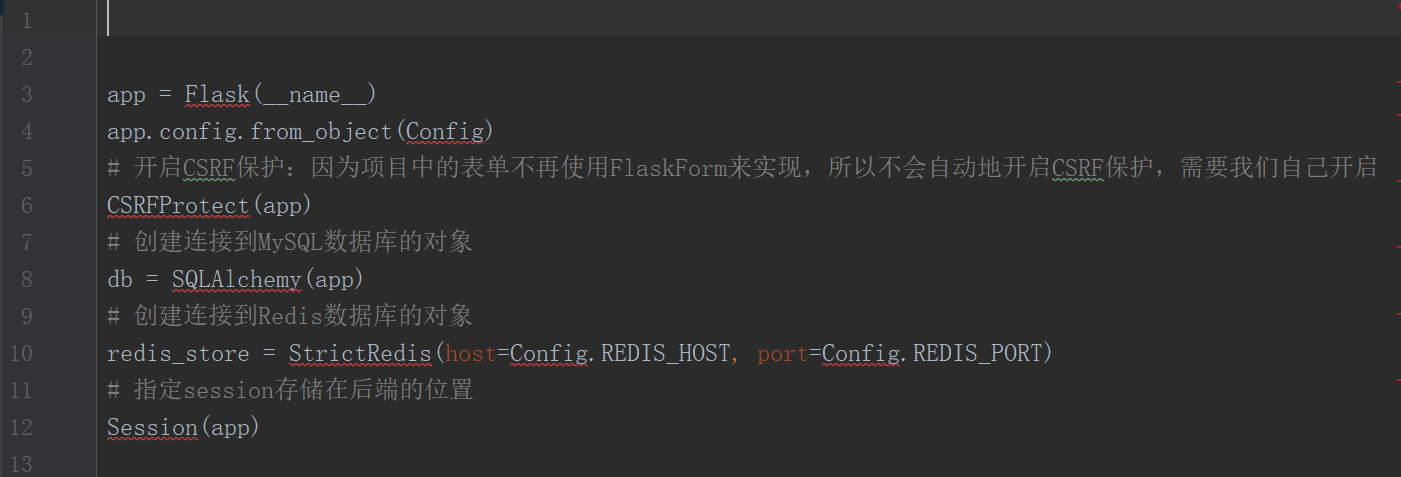
2.2 从这里我们可以看到一堆报红的,然后我们在返回manage.py去看,把灰色的包全部收集起来,扔到_init_.py这个目录下就可以了
2.3我们返回manage.py可以看到app和db报红,我们从_init_.py中导入一下
from info import app, db
然后运行一下代码检查一下,就可以了
3.工厂方式的建立
3.1 创建不同工作环境下的类
不同开发环境会有不同的配置,所以我们要封装不同开发环境下的配置信息。
首先我们在config.py中建立不同环境的类如下:
class DevlopmentConfig(Config): """开发环境""" pass class ProductionConfig(Config): """生产环境""" DEBUG = False SQLALCHEMY_DATABASE_URI = "mysql://root:mysql@127.0.0.1:3306/demo" class TestConfig(Config): """测试环境""" pass
3.2 用工厂方法创建app
这里专门解释下为啥要用工厂方式来创建app,因为app的相关信息的修改和业务逻辑有关。而你们公司会有个恶心的职业,叫做测试,每当我们修改了业务逻辑的相关内容,都必须要进行测试,哪怕只是加了个空格,改了标点也要重新测试(没错,就是这么恶心)。所以,你懂的!
而目前和业务逻辑无关的是manage.py和config.py我们要看看从哪个文件入手,来间接地处理这个问题,这里我们选择的是manage.py
3.2.1 创造创建app的函数
info -> __init__.py
首先我们创建一个函数 create_app ,然后给他传一个参数,再然后app的内容全部踢进去,然后改一下配置类所需要接受的参数
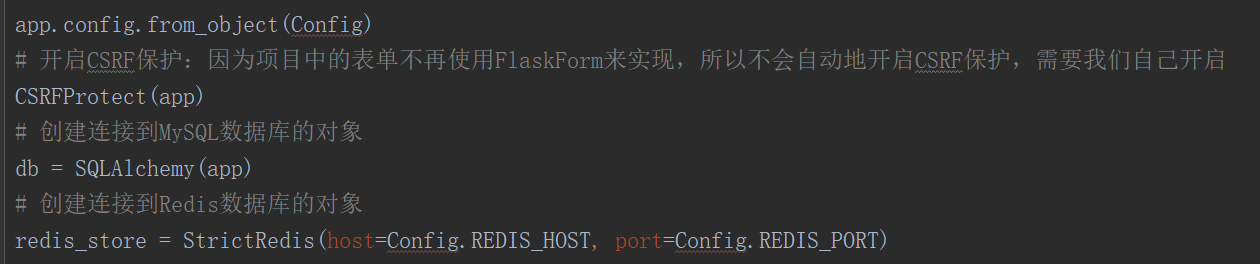
def create_app(env): app = Flask(__name__) app.config.from_object(env) # 开启CSRF保护:因为项目中的表单不再使用FlaskForm来实现,所以不会自动地开启CSRF保护,需要我们自己开启 CSRFProtect(app) # 创建连接到MySQL数据库的对象 db = SQLAlchemy(app) # 创建连接到Redis数据库的对象 redis_store = StrictRedis(host=env.REDIS_HOST, port=env.REDIS_PORT) # 指定session存储在后端的位置 Session(app)
当我们这么玩的时候,manage.py中的app和db导包的时候发生了错误,这是因为我们把这部分内容放到了函数中,这样我们就没法从__init__中读取这两个内容了。这里先不用解决,注释掉,
3.3 在manage.py中使用之前定义的创建app的函数来创建app
from info import create_app app = create_app("参数")
3.4 然后在配置信息的相关设置在config.py中,这个文件中定义一个字典,存储关键字对应的不同的配置类的内存地址
configs = { "dev": DevelopmentConfig, "pro": ProductionConfig, "test": TestConfig, }
然后我们就可以在manage.py里面加入那个参数了
app = create_app("dev")
参数传到了__init__中去创建app了。但是__init__中并不知道这个参数的作用,所以需要导入相关包,并完成相关配置:
from config import configs
def create_app(env):
app = Flask(__name__)
app.config.from_object(configs[env])
# 开启CSRF保护:因为项目中的表单不再使用FlaskForm来实现,所以不会自动地开启CSRF保护,需要我们自己开启
CSRFProtect(app)
# 创建连接到MySQL数据库的对象
db = SQLAlchemy(app)
# 创建连接到Redis数据库的对象
redis_store = StrictRedis(host=configs[env].REDIS_HOST, port=configs[env].REDIS_PORT)
# 指定session存储在后端的位置
Session(app)
测试之后报错,是因为没有给函数一个返回值,所以报错
所以,在工厂函数的后面加上:
return app
4.db问题的解决
4.1 首先我们第一步遇到问题先看源码:

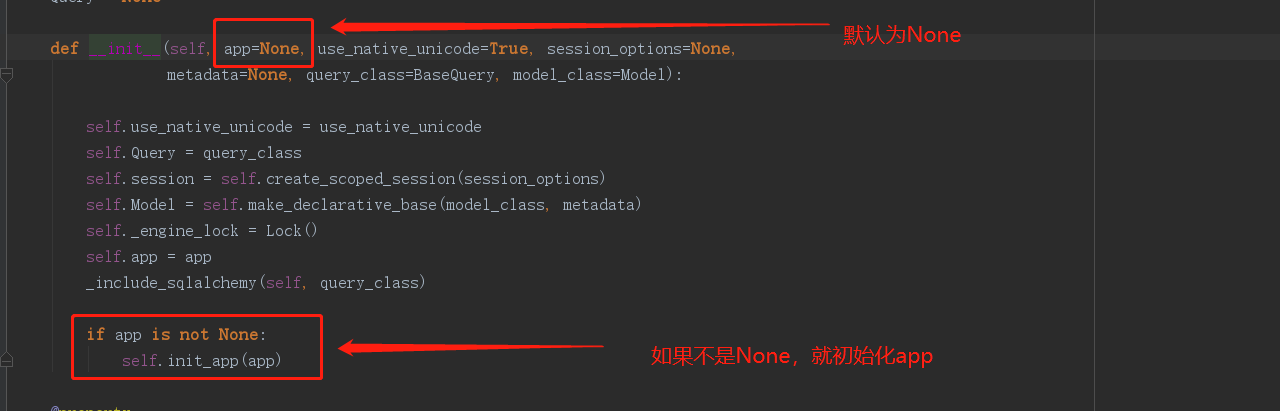
默认app为None,再看下边,如果app不等于None,那么就初始化app,由此我们可以写出以下代码:
...... # 创建SQLAlchemy对象 db = SQLAlchemy() def create_app(env): ...... # 创建连接到MySQL数据库的对象 # db = SQLAlchemy(app) db.init_app(app) ......
5.日志的使用
5.1首先我们来讲一下日志的级别
日志的等级
- 我们先来思考下下面的两个问题:
- 作为开发人员,在开发一个应用程序时需要什么日志信息?在应用程序正式上线后需要什么日志信息?
- 作为应用运维人员,在部署开发环境时需要什么日志信息?在部署生产环境时需要什么日志信息?
- 在软件开发阶段或部署开发环境时,为了尽可能详细的查看应用程序的运行状态来保证上线后的稳定性,我们可能需要把该应用程序所有的运行日志全部记录下来进行分析,这是非常耗费机器性能的
- 当应用程序正式发布或在生产环境部署应用程序时,我们通常只需要记录应用程序的异常信息、错误信息等,这样既可以减小服务器的I/O压力,也可以更加方便的进行故障排查。
-
那么,怎样才能在不改动应用程序代码的情况下实现在不同的环境记录不同详细程度的日志呢?这就是日志等级的作用了,我们通过配置文件指定我们需要的日志等级就可以了。
-
不同的应用程序所定义的日志等级可能会有所差别,分的详细点的会包含以下几个等级:
- FATAL/CRITICAL = 重大的,危险的 最高等级,服务器都可能会挂掉,接受惩罚吧
- ERROR = 错误
- WARNING = 警告 生产环境从这一等级开始
- INFO = 信息
- DEBUG = 调试 开发环境从这一等级开始
- NOTSET = 没有设置 最低等级,啥都记录
logging 模块的日志级别
- logging模块默认定义了以下几个日志等级,它允许开发人员自定义其他日志级别,但是这是不被推荐的,尤其是在开发供别人使用的库时,因为这会导致日志级别的混乱。
- DEBUG 最详细的日志信息,典型应用场景是 问题诊断
- INFO 信息详细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作
- WARNING 当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的
- ERROR 由于一个更严重的问题导致某些功能不能正常运行时记录的信息
- FATAL/CRITICAL 整个系统即将/完全崩溃
- 开发应用程序或部署开发环境时,可以使用 DEBUG 或 INFO 级别的日志获取尽可能详细的日志 信息来进行开发或部署调试;
- 应用上线或部署生产环境时,应该使用 WARNING 或 ERROR 或 CRITICAL 级别的日志来降低机器的I/O压力和提高获取错误日志信息的效率。
5.2 然后我们导入一下logging模块,并且在项目路径下创建一个存放专门存放日志的文件夹logs
import logging from logging.handlers import RotatingFileHandler # 设置日志的记录等级 logging.basicConfig(level=logging.DEBUG) # 调试debug级 # 创建日志记录器,指明日志保存的路径(前面的logs为文件的名字,需要我们手动创建,后面则会自动创建)、每个日志文件的最大大小、保存的日志文件个数上限。 file_log_handler = RotatingFileHandler("../logs/log", maxBytes=1024*1024*100, backupCount=10) # 创建日志记录的格式 日志等级 输入日志信息的文件名 行数 日志信息 formatter = logging.Formatter('%(levelname)s %(filename)s:%(lineno)d %(message)s') # 为刚创建的日志记录器设置日志记录格式 file_log_handler.setFormatter(formatter) # 为全局的日志工具对象(flask app使用的)添加日志记录器 logging.getLogger().addHandler(file_log_handler)
5.3 根据配置信息封装日志
创建一个函数 setup_log 并且将日志信息踢进去,并且接受一个参数为level
def setup_log(level): # 设置日志的记录等级 logging.basicConfig(level=level) # 调试debug级 # 创建日志记录器,指明日志保存的路径(前面的logs为文件的名字,需要我们手动创建,后面则会自动创建)、每个日志文件的最大大小、保存的日志文件个数上限。 file_log_handler = RotatingFileHandler("./logs/log", maxBytes=1024*1024*100, backupCount=10) # 创建日志记录的格式 日志等级 输入日志信息的文件名 行数 日志信息 formatter = logging.Formatter('%(levelname)s %(filename)s:%(lineno)d %(message)s') # 为刚创建的日志记录器设置日志记录格式 file_log_handler.setFormatter(formatter) # 为全局的日志工具对象(flask app使用的)添加日志记录器 logging.getLogger().addHandler(file_log_handler)
并且到环境工厂里面去,调试一下logging的日志等级
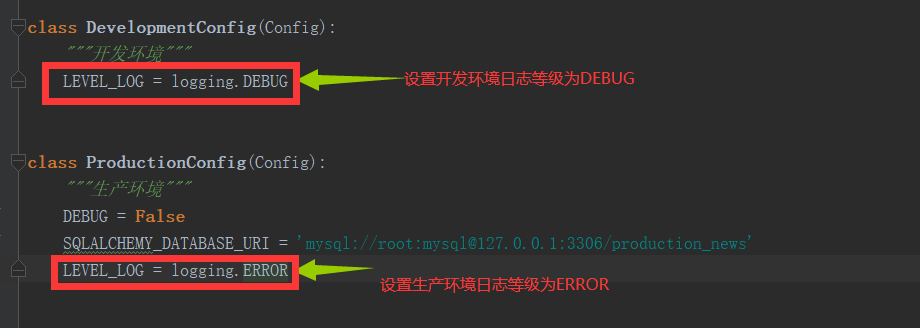
然后我们可以传参数了

5.4 我们现在把日志等级调一下,调成pro的日志等级来看看,我们之前pro设置的日志等级是ERROR等级


它什么都没有,但我们的前端又能运行,他是个怎么回事儿呢
因为它的一个日志级别比其他的日志级别都高,所以其他日志级别都不能显示,只能显示ERROR级别的一个信息。
6.蓝图抽取
6.1 新建业务逻辑文件夹
我们将业务逻辑统一放在了info文件夹中,而项目中我们又会分为很多的业务模块,比如用户模块、订单模块等。
在info的业务逻辑模块中,除了放业务模块还会放其他内容,所以我们需要新建一个文件夹来专门存放这些业务模块。
这里,我们在info下新建一个名为modules的文件夹来存放它们。
我们在modules中新建一个名为index的python package文件夹用于存放主页的相关内容,并在这个文件夹中新建一个views.py来存储视图函数相关内容。
6.2 函数的抽取以及封装
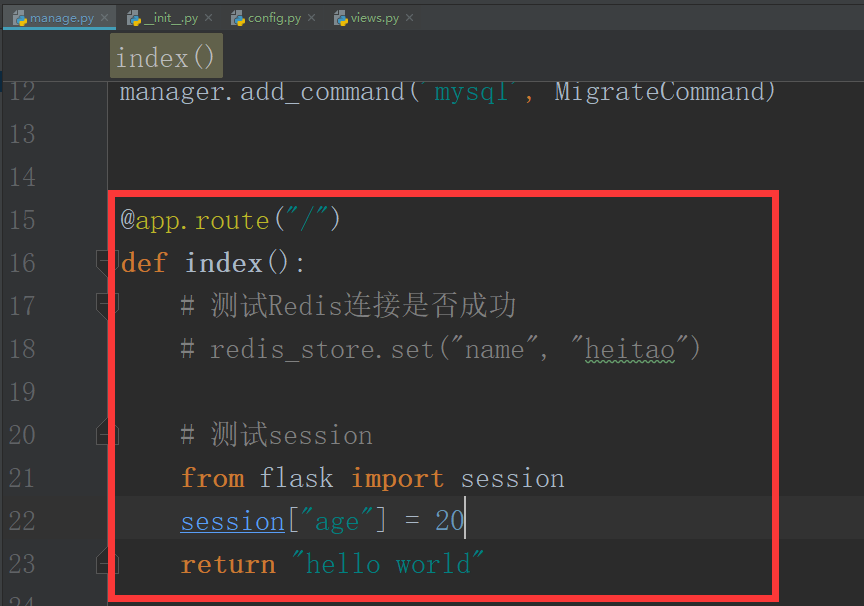
首先我们把我们的视图函数从manage.py中抽取并剪切到我们的views.py里面去
然后我们在views.py中进行对刚刚抽取过来的代码经行一个修改以及蓝图的导入
from flask import Blueprint index_blue = Blueprint("index", __name__) @index_blue.route("/") def index(): # 测试Redis连接是否成功 # redis_store.set("name", "heitao") # 测试session from flask import session session["age"] = 20 return "hello world"
因为前边蓝图的建立跟路由和视图的关系不大,所以我们抽取出来经行一下封装,我们把它扔到index下的_init_.py里面
from flask import Blueprint index_blue = Blueprint("index", __name__) from . import views
然后我们回到views.py里面导入一下index_blue
from . import index_blue
6.3 注册路由
基本上我们蓝图就弄的差不多了,就差最后一步注册路由了,我们到info文件夹中_init_.py中去注册一下路由
from info.moudles.index.views import index_blue ...... def create_app(env): ...... # 注册路由 app.register_blueprint(index_blue)
return app
