神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词。看完后有一些自己的小想法,也想做一个玩儿一玩儿。用到的原理是深度学习里的循环神经网络,无奈理论太艰深,只能从头开始开始慢慢看,因此产生写一个项目的想法,把机器学习和深度学习里关于分类的算法整理一下,按照原理写一些demo,方便自己也方便其他人。项目地址:https://github.com/LiuRoy/classfication_demo,目前实现了逻辑回归和神经网络两种分类算法。
Logistic回归
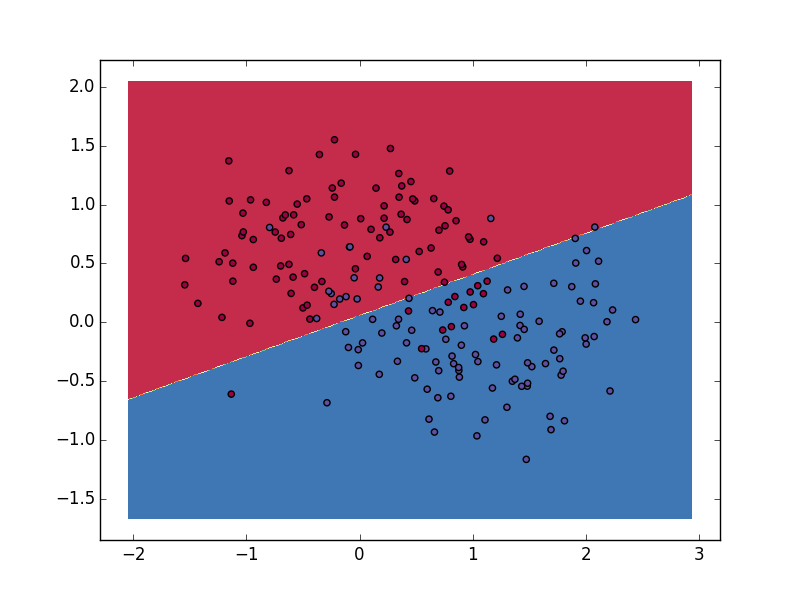
这是相对比较简单的一种分类方法,准确率较低,也只适用于线性可分数据,网上有很多关于logistic回归的博客和文章,讲的也都非常通俗易懂,就不赘述。此处采用随机梯度下降的方式实现,讲解可以参考《机器学习实战》第五章logistic回归。代码如下:
def train(self, num_iteration=150):
"""随机梯度上升算法
Args:
data (numpy.ndarray): 训练数据集
labels (numpy.ndarray): 训练标签
num_iteration (int): 迭代次数
"""
for j in xrange(num_iteration):
data_index = range(self.data_num)
for i in xrange(self.data_num):
# 学习速率
alpha = 0.01
rand_index = int(random.uniform(0, len(data_index)))
error = self.label[rand_index] - sigmoid(sum(self.data[rand_index] * self.weights + self.b))
self.weights += alpha * error * self.data[rand_index]
self.b += alpha * error
del(data_index[rand_index])
效果图:
神经网络
参考的是这篇文章,如果自己英语比较好,还可以查看英文文章,里面有简单的实现,唯一的缺点就是没有把原理讲明白。关于神经网络,个人认为确实不是一两句就能解释清楚的,尤其是网上的博客,要么只给公式,要么只给图,看起来都非常的晦涩,建议大家看一下加州理工的一个公开课,有中文字幕,一个小时的课程绝对比自己花一天查文字资料理解的深刻,知道原理之后再来看前面的那篇博客就很轻松啦!
BGD实现
博客里面实现用的是批量梯度下降(batch gradient descent),代码:
def batch_gradient_descent(self, num_passes=20000):
"""批量梯度下降训练模型"""
for i in xrange(0, num_passes):
# Forward propagation
z1 = self.data.dot(self.W1) + self.b1
a1 = np.tanh(z1)
z2 = a1.dot(self.W2) + self.b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Backpropagation
delta3 = probs
delta3[range(self.num_examples), self.label] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(self.W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(self.data.T, delta2)
db1 = np.sum(delta2, axis=0)
# Add regularization terms (b1 and b2 don't have regularization terms)
dW2 += self.reg_lambda * self.W2
dW1 += self.reg_lambda * self.W1
# Gradient descent parameter update
self.W1 += -self.epsilon * dW1
self.b1 += -self.epsilon * db1
self.W2 += -self.epsilon * dW2
self.b2 += -self.epsilon * db2
效果图:

注意:强烈怀疑文中的后向传播公式给错了,因为和代码里的delta2 = delta3.dot(self.W2.T) * (1 - np.power(a1, 2))对不上。
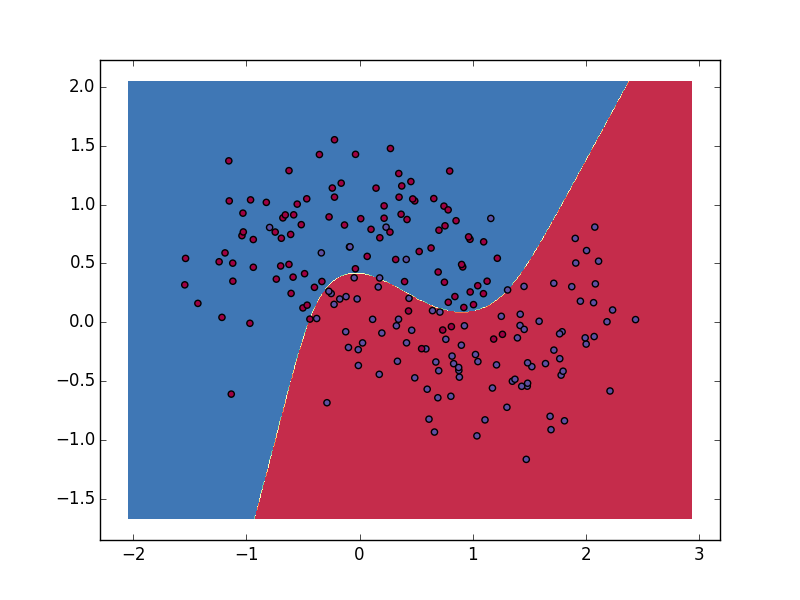
SGD实现
考虑到logistic回归可以用随机梯度下降,而且公开课里面也说随机梯度下降效果更好一些,所以在上面的代码上自己改动了一下,代码:
def stochastic_gradient_descent(self, num_passes=200):
"""随机梯度下降训练模型"""
for i in xrange(0, num_passes):
data_index = range(self.num_examples)
for j in xrange(self.num_examples):
rand_index = int(np.random.uniform(0, len(data_index)))
x = np.mat(self.data[rand_index])
y = self.label[rand_index]
# Forward propagation
z1 = x.dot(self.W1) + self.b1
a1 = np.tanh(z1)
z2 = a1.dot(self.W2) + self.b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Backpropagation
delta3 = probs
if y:
delta3[0, 0] -= 1
else:
delta3[0, 1] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
va = delta3.dot(self.W2.T)
vb = 1 - np.power(a1, 2)
delta2 = np.mat(np.array(va) * np.array(vb))
dW1 = x.T.dot(delta2)
db1 = np.sum(delta2, axis=0)
# Add regularization terms (b1 and b2 don't have regularization terms)
dW2 += self.reg_lambda * self.W2
dW1 += self.reg_lambda * self.W1
# Gradient descent parameter update
self.W1 += -self.epsilon * dW1
self.b1 += -self.epsilon * db1
self.W2 += -self.epsilon * dW2
self.b2 += -self.epsilon * db2
del(data_index[rand_index])
可能是我写的方式不好,虽然可以得到正确的结果,但是性能上却比不上BGD,希望大家能指出问题所在,运行效果图:
其他
SVM我还在看,里面的公式推导能把人绕死,稍晚一点写好合入,数学不好就是坑啊😭。至于决策树分类,贝叶斯分类等比较简单的,没有数学功底的人实现起来也很容易,就不放进去了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号