
基于redis的分布式锁原理
前言:
在高并发编程当中,锁是一种将并行执行的程序转化成串行执行的程序的一种手段,它是牺牲效率而追求数据安全性的一种措施。在单节点项目中,由于是在一个jvm进程之中,我们可以使用synchronized或者Lock来解决并发安全问题,但是在分布式架构或者集群项目中若要使用jvm层面的锁效果不大,所以这就需要使用分布式锁。问题复现:
首先先看一下不使用分布式锁在集群项目当中会导致的数据安全问题现在模拟扣减库存的场景,我们先在redis中创建一个库存为1000的key value
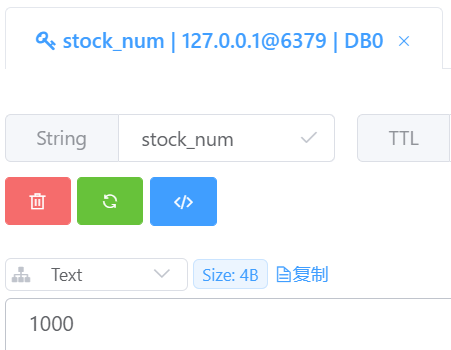
然后写一段简单的代码用来扣减库存
点击查看代码
@RestController public class RedisDistributedController { @Resource RedisTemplate redisTemplate; @RequestMapping("/lessenStock") public synchronized String redisDistributedLock() { Object stock_num = redisTemplate.opsForValue().get("stock_num"); long l = Long.parseLong(stock_num.toString()); if(l > 0) { redisTemplate.opsForValue().set("stock_num", (l-1)+""); System.out.println("stock_num:" + (l-1)); } else { System.out.println("stock_num is zero!"); } return "success"; } }
然后使用一个nginx作为负载均衡,把我们的请求分发到每台服务器上,配置文件我这边是这样写的
点击查看代码
#全局块 #user nobody; worker_processes 3; #event块 events { worker_connections 1024; } #http块 http { #http全局块 include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; #server块 server { listen 80; server_name localhost; location / { root html; index index.html index.htm; proxy_pass http://redisdis; } } upstream redisdis{ server localhost:8080 weight=1; server localhost:8081 weight=1; server localhost:8082 weight=1; } }
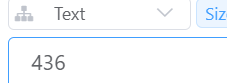
然后点击jmeter的start,这时可以看到报告当中1000个请求已经执行成功
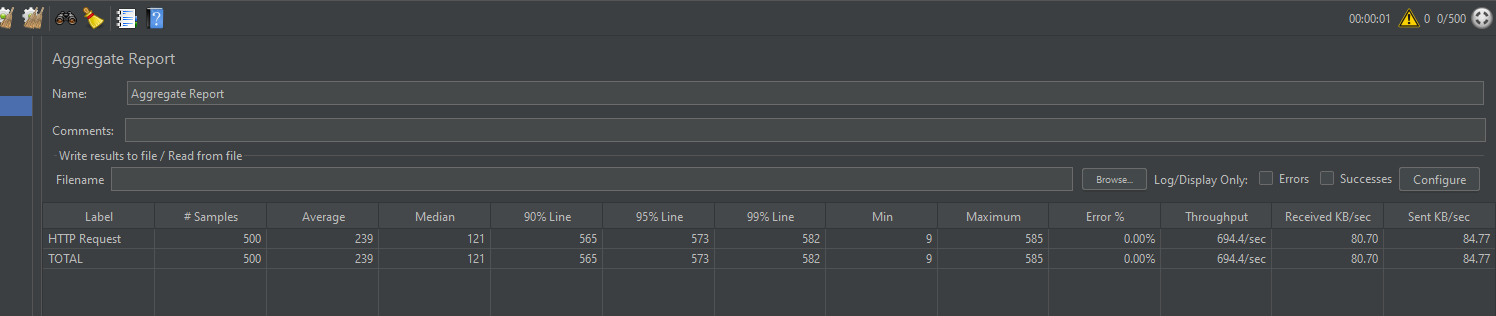
然后去redis中看stock_num的值, 虽然期望值是0,但是结果是436
在分布式项目或者集群项目当中,jvm层面的锁显然没有办法解决高并发场景下的数据安全问题,若要解决这个问题就需要用到分布式锁
基于redis的分布式锁原理
在需要加锁的代码要执行前, 我们先去redis中设置一个值,这个值就是我们的锁信息,只有设置成功的线程才会执行后面的代码。其中的代码可以是这样的:点击查看代码
@RequestMapping("/lessenStock") public String redisDistributedLock() { //如果lock在redis中不存在,lockSuccess的值为true, 否则为false Boolean lockSuccess = redisTemplate.opsForValue().setIfAbsent("lock", ""); //只有设置成功, 才会执行下面的代码 if(lockSuccess) { Object stock_num = redisTemplate.opsForValue().get("stock_num"); long l = Long.parseLong(stock_num.toString()); if (l > 0) { redisTemplate.opsForValue().set("stock_num", (l - 1) + ""); System.out.println("stock_num:" + (l - 1)); } else { System.out.println("stock_num is zero!"); } redisTemplate.delete("lock"); return "success"; } else { return "fail"; } }
-
没有重试方案,如果设置值不成功,不会循环等待
-
这个锁不是可重入的
-
这个锁没有超时时间,如果要是某台服务在set lock和delete lock中间宕机了,就会导致其余的线程没有办法执行
-
如果给这个锁设置了超时时间,假如说在业务代码中发生了一次full gc或者某个订单的业务场景复杂走了非常非常多的校验,导致锁自动失效了,那么下面的delete lock 就会将其余线程已经加了锁删除掉,这样我们的锁就永久失效了。
问题解决
- 第一种情况, 我们可以加一个循环代码块,类似这样:
点击查看代码
if(!lockSuccess) { while(true) { Thread.sleep(n); setkey if(setKey == true) { break; } } }
-
第二种情况,我们可以在redis锁的value中设置一个当前线程的唯一id, 判断一下如果redis中的value是当前线程加的唯一id,那就直接再次进入代码块中,另外在删除key的时候也需要先判断一下锁的value值是否是之前生成的唯一id,这样就不会出现删除其余线程的值的情况。
-
对于超时的问题,setIfAbsent方法有很多的重载方法,其中有一个四个参数的重载方法Boolean setIfAbsent(K key, V value, long timeout, TimeUnit unit);这条命令是原子性的, 不会将设置值和设置超时时间分为两步来执行。然后我们执行完这句代码之后可以再在后台开启一个新线程用于监控这个锁是否快要过期了,如果快要过期了,我们就加大这个key的过期时间,这样只要不发生宕机重启断电等重大事故,一般情况下代码块中的代码都是可以执行完成的。
我们可以使用redisson框架来轻松的解决以上问题,redisson已经帮我们做了以上这些情况的处理,并且实现与上述类似。在生产环境中,也不推荐大家去自己实现分布式锁。
使用redisson加锁的api方法类似于jdk中的lock和unlock
点击查看代码
private void redissonLock() { RLock lock = redissonClient.getLock("lockKey"); boolean b = lock.lock(30, TimeUnit.SECONDS); try { //业务代码 } finally { lock.unlock(); } }
主从架构下redis分布式锁的稳定性
在主从架构中,写入都是写入master节点,master会将数据同步到slave中,假如某个线程A获取到了锁,并且已经到值设置到redis中,这时如果master节点挂掉了,会从slave节点中选举出一个master,如果已经加锁的key还没有来得及同步到从slave节点中,那么选举出来的新的master节点中就没有这个key,这个时候线程B就能加锁来获取分布式锁执行业务逻辑,而这个时候A还没有执行结束,所以就会出现并发安全问题,这就是Redis主从架构的分布式锁失效问题。这种情况我们可以使用RedLock来解决
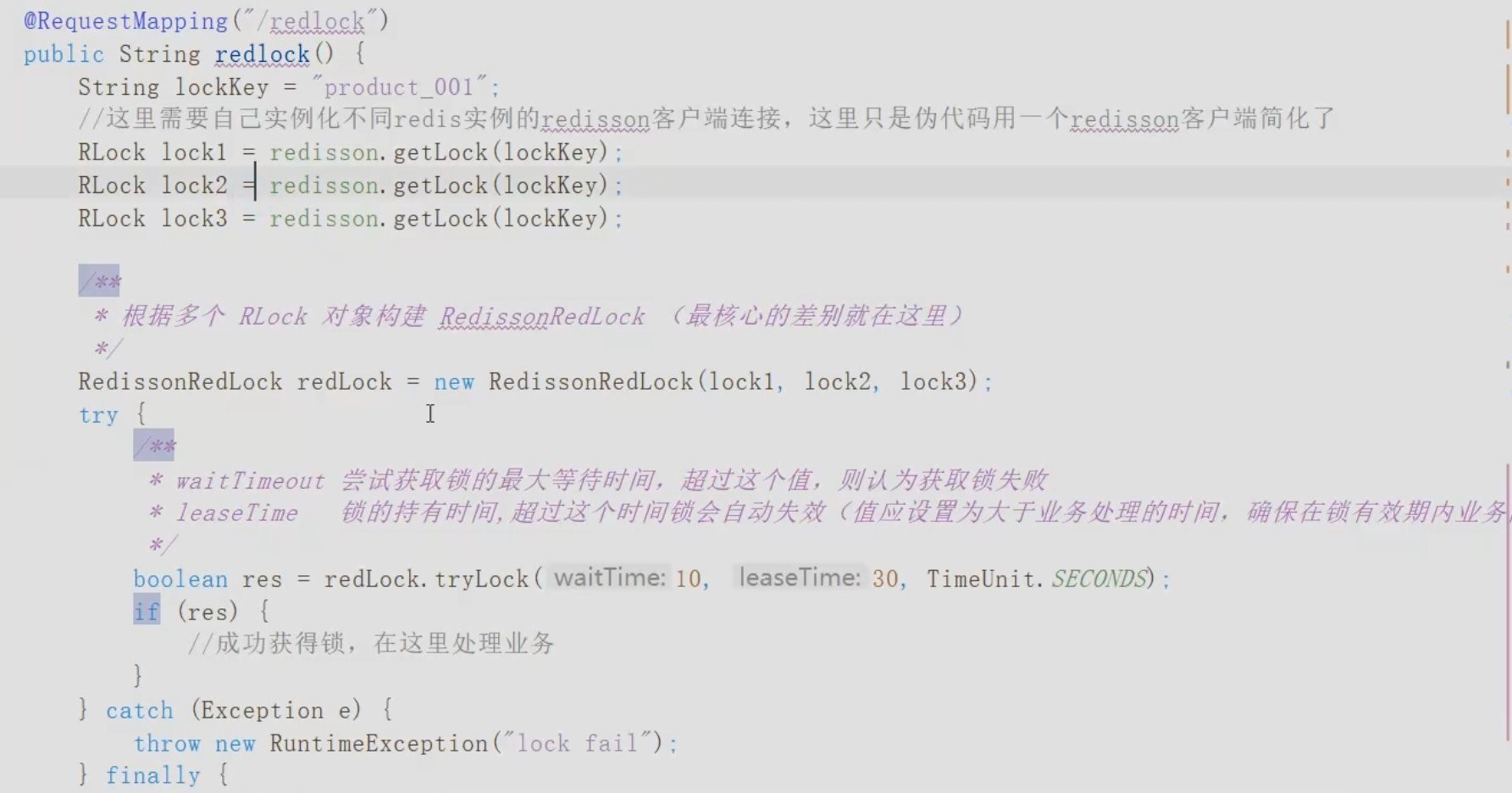
RedLock的原理是使用多个redis节点(非slave节点)来同时加锁, 只要有n/2+1个节点加锁成功, 就执行同步代码块中的代码,否则重新获取


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步