网络IO模型
同步(synchronous) IO、异步(asynchronous) IO、阻塞(blocking) IO、非阻塞(non-blocking)IO
1、阻塞IO(blocking IO)
系统调用(一般是IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。
在此期间,线程将无法执行任何运算或响应任何的网络请求。
一个简单的改进方案是在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。
传统意义上,进程的开销要远远大于线程,所以如果需要同时为较多的客户机提供服务,则不推荐使用多进程;
如果单个服务执行体需要消耗较多的CPU资源,譬如需要进行大规模或长时间的数据运算或文件访问,则进程较为安全。
2、非阻塞IO(non-blocking IO)
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。
一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
在非阻塞式IO中,用户进程需要不断的主动询问kernel数据准备好了没有,严重影响性能。
3、多路复用IO(IO multiplexing)
即 select/epoll
select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。
它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
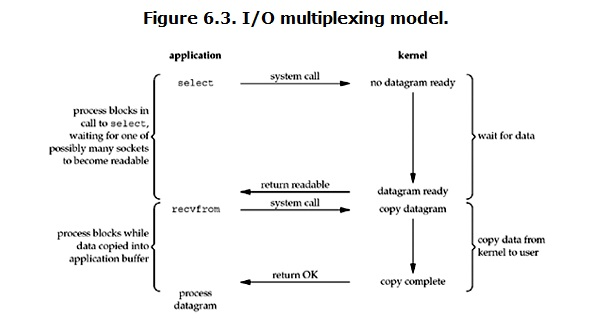
事件驱动模型:
普通的非阻塞IO是各个IO自行盲询自己的IO是否就绪,而IO复用则是以一个系统调用来完成所有IO是否就绪的轮询,如果就绪则执行IO操作。
事件驱动是IO复用的一种升级版本,IO复用是轮询所有的IO。
而事件驱动是只处理已经就绪的IO,首先开启socket信号驱动的功能(将socket放到epoll文件系统里file对象对应的红黑树,并在内核终端处理程序中注册回调函数),当网卡检测到某个socket有数据来到时,内核就会将socket放入IO就绪队列,并从网卡拷贝数据到内核。
IO复用的缺点:
单线程能轮询的文件描述符有限1024;
需要轮询所有的IO,如果当前IO事件很多,但是就绪的非常少,那么会导致效率下降;
事件驱动则可以解决上述两个缺点,没有文件描述符的限制(通常都非常大,比如2G内存的机器都有655350);只处理已经就绪的IO,可以过滤掉不活跃的IO轮询带来的损失。
同时使用mmap(内存映射)的方式,来减少IO数据从内核-用户控件的拷贝。
MMAP介绍:
1、用户空间、内核空间都是不能直接访问设备的物理地址
2、内核空间如果要访问设备的物理地址,需要先映射物理地址到内核的虚拟地址(页缓存)上,以后驱动程序访问这个虚拟地址
3、用户空间只能通过系统调用访问映射好的内核虚拟地址(页缓存)
这上面会有2次数据拷贝,硬件和内核空间,用户空间和内核空间。
而MMAP的目的是将2次拷贝转换为1次拷贝,节约拷贝数据带来的消耗。
将物理地址映射到一块内存,应用程序(用户区域)可以直接访问这块内存。
事件驱动的缺点:
如果各个IO都比较活跃,那么IO复用的全轮询也不会有太多的性能损失,但是注册socket驱动事件却会带来一些负担。
4、异步IO(Asynchronous I/O)
用户进程发起read操作之后,立刻就可以开始去做其它的事。
而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
转自:http://blog.chinaunix.net/uid-28458801-id-4464639.html ,https://www.cnblogs.com/souyoulang/p/8873558.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号