

一个完整的大作业
我选择主题是58同城二手汽车买卖网,爬取的网站是:http://gz.58.com/ershouche/?utm_source=market&spm=b-31580022738699-pe-f-829.hao360_101&PGTID=0d100000-0000-3ada-ba49-dc2ff301240a&ClickID=1
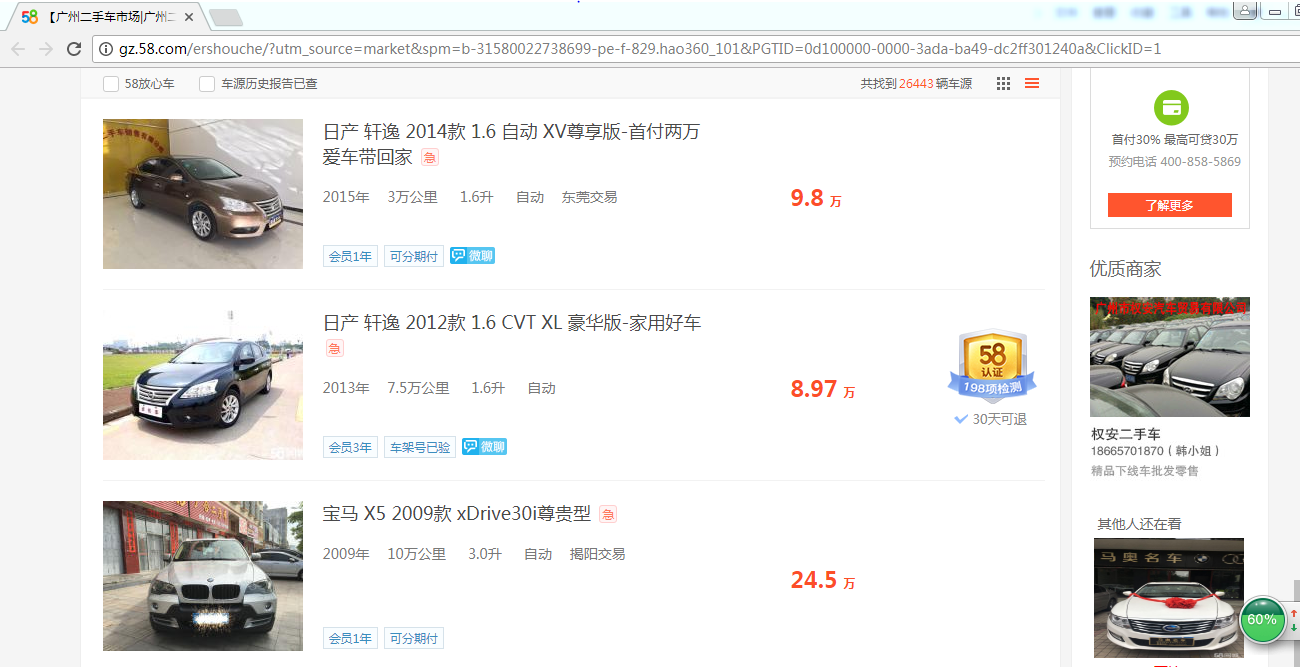
爬取网站的各个品牌的二手车品牌的链接
import requests from bs4 import BeautifulSoup url='http://gz.58.com/ershouche/?utm_source=market&spm=b-31580022738699-pe-f-829.hao360_101&PGTID=0d100000-0000-3ada-ba49-dc2ff301240a&ClickID=1' res=requests.get(url) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') for esc in soup.select('li'): if len(esc.select('li'))>0: url=esc.select('a')[0]['href'] title=esc.select('a')[0].text print(title,url)

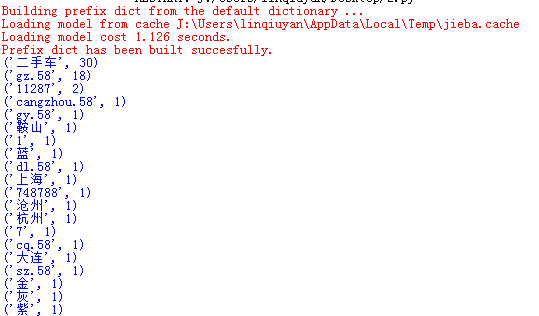
分析爬取到的结果,统计词频
import jieba fr=open("58.txt",'r',encoding='utf-8') s=list(jieba.cut(fr.read())) exp={'pve','\n','.','_','”','“',':','http',' ','?','(',')','*',':','4917',';','ershouche','/','com'} key=set(s)-exp dic={} for i in key: dic[i]=s.count(i) wc=list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) for i in range(20): print(wc[i]) fr.close()
生成词云
#coding:utf-8 import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator text =open("58.txt",'r',encoding='utf-8').read() print(text) wordlist = jieba.cut(text,cut_all=True) wl_split = "/".join(wordlist) backgroud_Image = plt.imread('heart.jpg') mywc = WordCloud( background_color = 'white', # 设置背景颜色 mask = backgroud_Image, # 设置背景图片 max_words = 2000, # 设置最大字数 stopwords = STOPWORDS, # 设置停用词 font_path = 'C:/Users/Windows/fonts/msyh.ttf',# 设置字体格式 max_font_size = 200, # 设置字体值 random_state = 30, # 设置有多少种随机生成状态 ).generate(text) plt.imshow(mywc) plt.axis("off") plt.show()

