
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
参考:
爬了一下天猫上的Bra购买记录,有了一些羞羞哒的发现...
Python做了六百万字的歌词分析,告诉你中国Rapper都在唱些啥
分析了42万字歌词后,终于搞清楚民谣歌手唱什么了
十二星座的真实面目
唐朝诗人之间的关系到底是什么样的?
中国姓氏排行榜
一、爬取对象
在2018年一月我有幸拜读了由上个世纪70年代永井豪大师创作的超前深度漫画《恶魔人》改编的动画《恶魔人crybaby》

这部佳作当时给了我极大的冲击,剧中“何为善恶,何为人性”这一拷问让我至现在还无法解答,所以在这次的爬虫学习中我决定爬取《恶魔人crybaby》中的短评,看下别人眼中的恶魔人是什么样子。
二、开始爬取
1.分析目标数据的网页结构
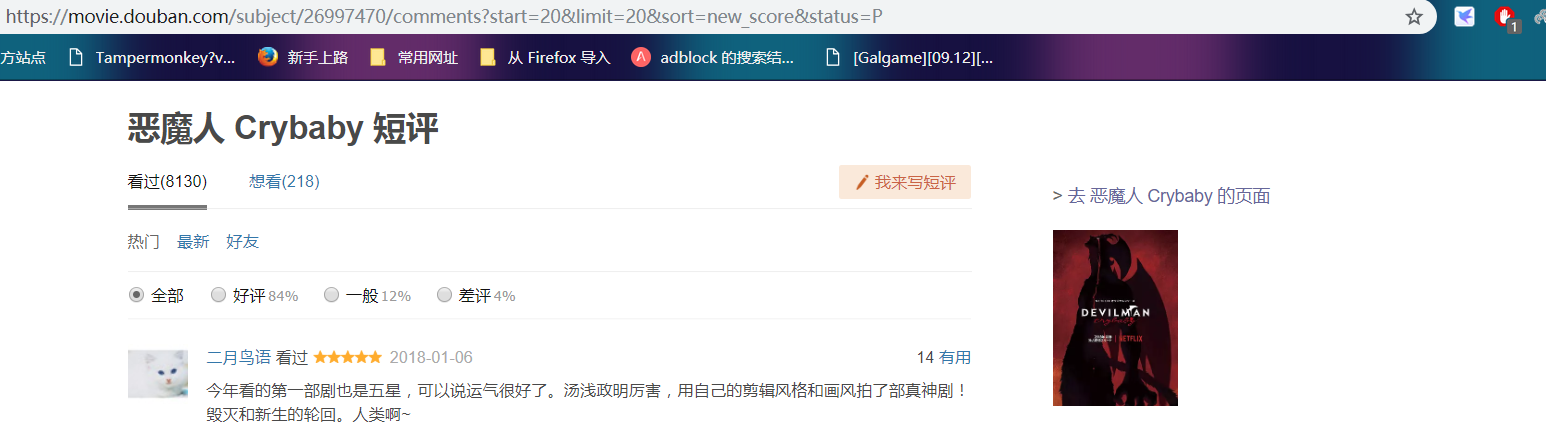
通过分析每一页的url都是由'https://movie.douban.com/subject/26997470/comments?start=' + (20*页数) + '&limit=20&sort=new_score&status=P'这种格式构成,
因此我们可以得出通用URL格式'https://movie.douban.com/subject/26997470/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P'
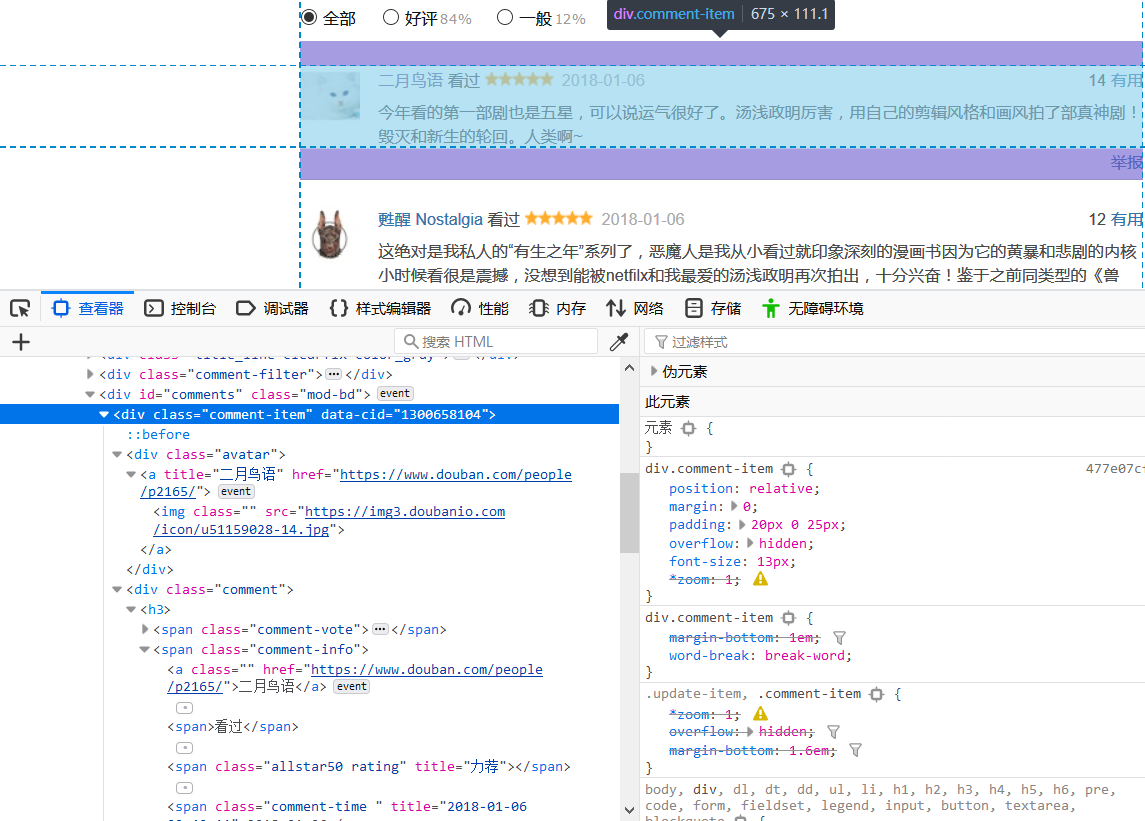
通过分析html元素结构,可知短评的用户名数据与短评内容与点赞数位于class=comment_item的span元素,因此我们可以用beautifulsoup解析findall('span', 'comment_item')代码来先获取一个评论板块。
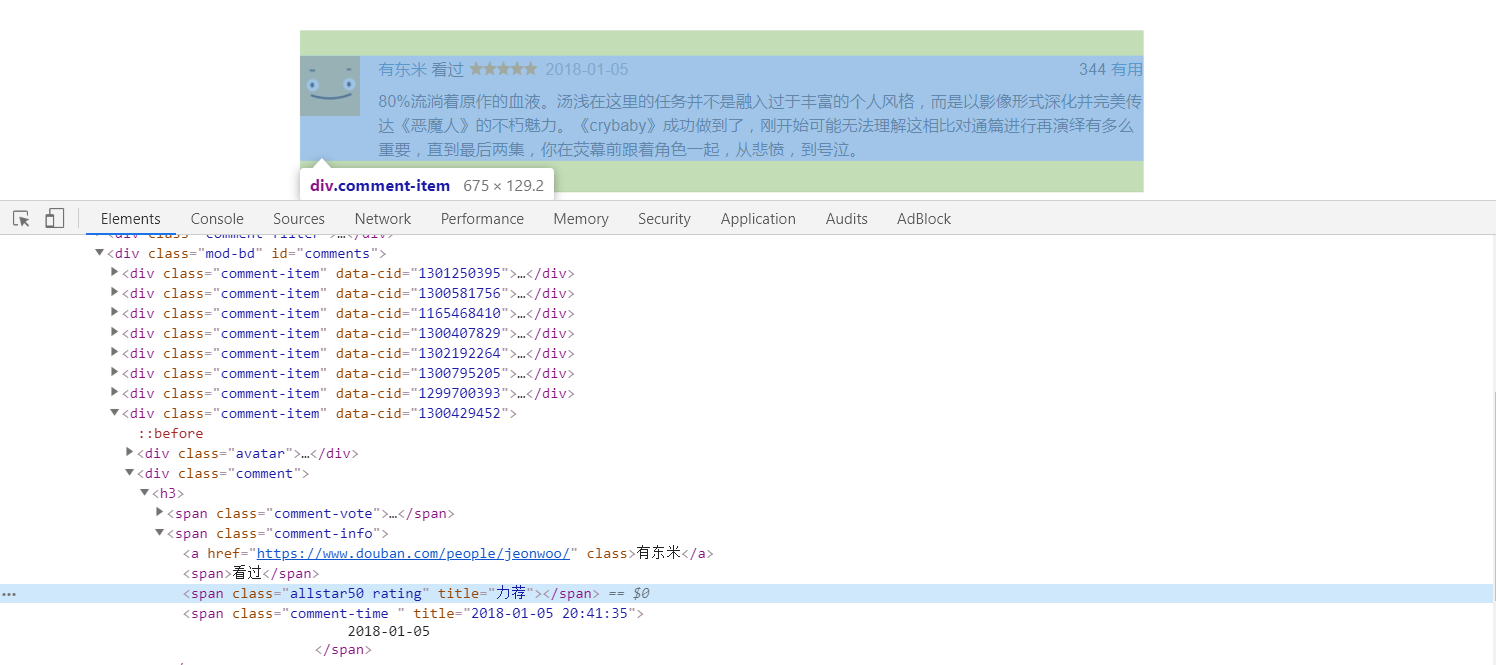
而同时发现评分内容处于class="comment-info"的span下的第一个span子元素中的title属性值,我们可以通过正则表达式匹配包含关键字class=allstar的span来获取对应的titile属性,也可以通过xpath方式来获取需要的数据,但是需要过滤掉没有做出评分的用户。
2.开始爬取数据
首先进行前30页的短评爬取:
if __name__ == '__main__': f1 = open('恶魔人crybaby好评度.txt', 'w', encoding='utf-8') for page in range(30): # 豆瓣恶魔人crybaby前30页短评论 url = 'https://movie.douban.com/subject/26997470/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P' time.sleep(random.random() * 3) getPingfen(url) f1.write(str(pingajia)) time.sleep(random.random() * 3) getPinglun(url) f1.close() print(pingajia) print(pinglun) writerCSV = pd.DataFrame(pinglun) writerCSV.to_csv('恶魔人crybaby.csv', encoding='utf-8')
新建恶魔人crybaby好评度.txt保存好评度数据,爬取的评论数据写入恶魔人crybaby.csv文件保存评论数据,同时设置随机时间间隔进行传入通用格式url进行爬取网页数据,减少网站压力。
global pingajia,pinglun #定义全局变量记录评分情况与评论相关数据 pingajia = {'很差': 0, '较差': 0, '还行': 0, '推荐': 0, '力荐': 0} pinglun = [] def getHtml(url): #获取html proxies = {"http": "http://192.10.1.10:8080", "https": "http://193.121.1.10:9080"} cookies = {'cookie':'bid=umuLg3iZhkI; gr_user_id=98225c1a-dbb7-4892-9f1a-b109797f47b8; _vwo_uuid_v2=D4785A3539CB3B44B17B113925EFAF048|17c62c9137095bd21941127ee5001657; viewed="1770782_1200840"; __utmz=30149280.1553270495.2.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); ll="118281"; _pk_ses.100001.8cb4=*; __utma=30149280.1116038887.1553258504.1553270495.1561001711.3; __utmc=30149280; __utmt=1; ap_v=0,6.0; __yadk_uid=8ACD8TDbyZ5u3vvzrfBsgTPBHlA0BDFV; _pk_id.100001.8cb4=4df36ec4e19661d2.1561001704.1.1561001761.1561001704.; __utmb=30149280.2.10.1561001711'} headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:65.0'} res = requests.get(url,headers=headers, cookies=cookies) res.encoding = 'utf-8' # 爬虫结果乱码,可以用UTF-8解码更正 html = res.text return html def getPinglun(url): #获取页面上每个评论内容、点赞数与用户名 html = getHtml(url) soup = BeautifulSoup(html, 'html.parser') duanpings = soup.findAll('div', class_='comment-item') #获取到所有评论item for duanping in duanpings: comment = {} comment['id'] = duanping.find("span",class_='comment-info').find('a').get_text() comment['comment'] = duanping.find("span", class_="short").get_text().replace('\n', '').replace(' ','') comment['vote'] = duanping.find("span", class_="votes").get_text() pinglun.append(comment)
用request方法获取解析网页,在request添加headers使爬虫模仿浏览器访问的行为,添加cookies可以使爬虫以登录状态访问网页以获取没有登录无法得到的数据,用beautifulsoup中的findall方法找到对应的元素获取相应的评论数据,findall之后再继续再生成字典保存相关属性数据,最后字典保存到pinglun数组中。
然后进行评分爬取:
global pingajia,pinglun #定义全局变量记录评分情况与评论相关数据 pingajia = {'很差': 0, '较差': 0, '还行': 0, '推荐': 0, '力荐': 0} pinglun = [] def getHtml(url): #获取html proxies = {"http": "http://192.10.1.10:8080", "https": "http://193.121.1.10:9080"} cookies = {'cookie':'bid=umuLg3iZhkI; gr_user_id=98225c1a-dbb7-4892-9f1a-b109797f47b8; _vwo_uuid_v2=D4785A3539CB3B44B17B113925EFAF048|17c62c9137095bd21941127ee5001657; viewed="1770782_1200840"; __utmz=30149280.1553270495.2.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); ll="118281"; _pk_ses.100001.8cb4=*; __utma=30149280.1116038887.1553258504.1553270495.1561001711.3; __utmc=30149280; __utmt=1; ap_v=0,6.0; __yadk_uid=8ACD8TDbyZ5u3vvzrfBsgTPBHlA0BDFV; _pk_id.100001.8cb4=4df36ec4e19661d2.1561001704.1.1561001761.1561001704.; __utmb=30149280.2.10.1561001711'} headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:65.0'} res = requests.get(url,headers=headers, cookies=cookies) res.encoding = 'utf-8' # 爬虫结果乱码,可以用UTF-8解码更正 html = res.text return html def getPinglun(url): #获取页面上每个评论内容、点赞数与用户名 html = getHtml(url) soup = BeautifulSoup(html, 'html.parser') duanpings = soup.findAll('div', class_='comment-item') #获取到所有评论item for duanping in duanpings: comment = {} comment['id'] = duanping.find("span",class_='comment-info').find('a').get_text() comment['comment'] = duanping.find("span", class_="short").get_text().replace('\n', '').replace(' ','') comment['vote'] = duanping.find("span", class_="votes").get_text() pinglun.append(comment)
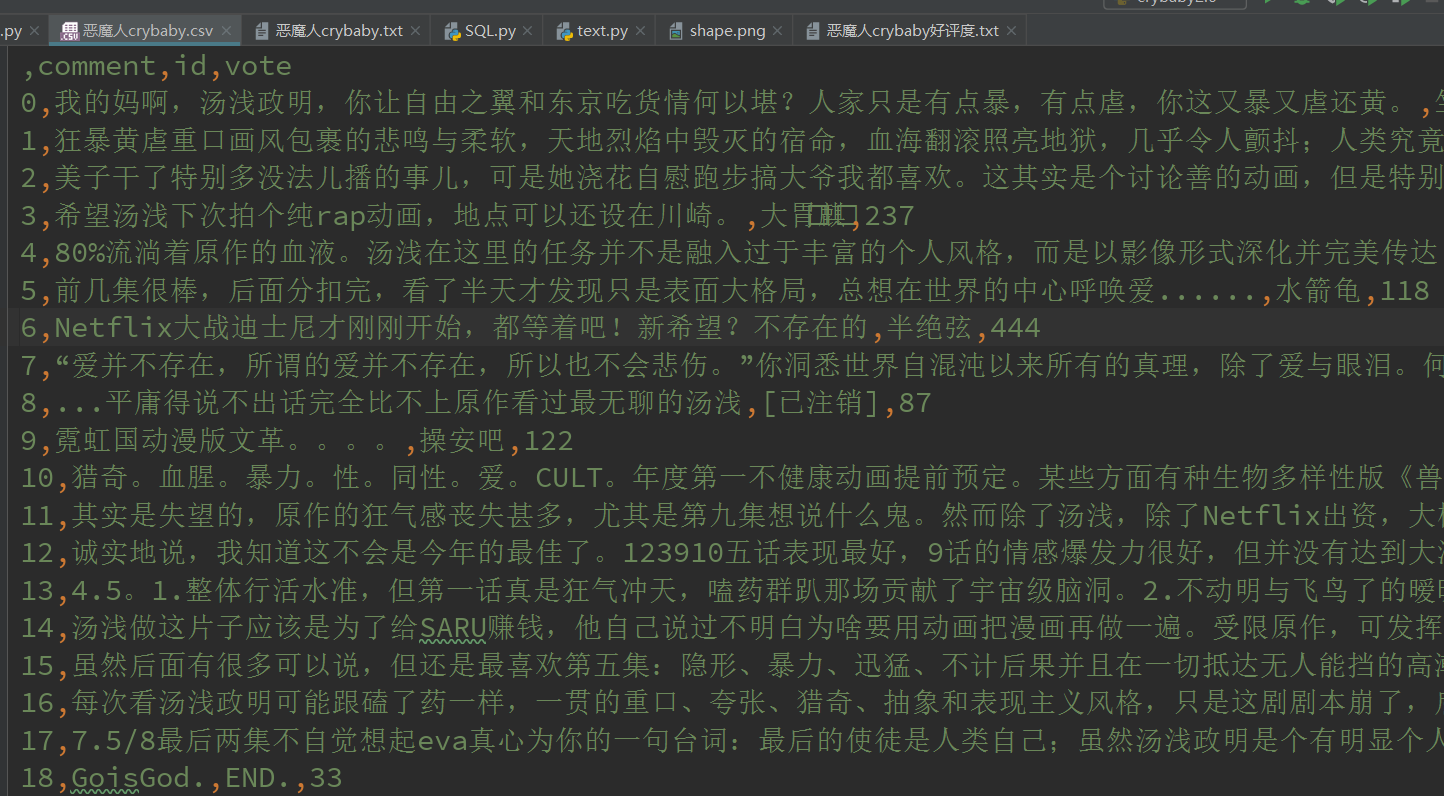
得出结果如下图:

3.分析评论数据
用jieba对上爬取下来的评论数据进行切片处理,最后统计词汇生成csv与词云图
核心代码如下:
import jieba import pandas as pd from PIL import Image from wordcloud import WordCloud, ImageColorGenerator import matplotlib.pyplot as plt import numpy as np import matplotlib.font_manager as fm f = open('恶魔人crybaby.txt', 'r', encoding='utf-8') #读取小说内容 nov = f.read() f.close() f1 = open('stops_chinese.txt', 'r', encoding='utf-8') #读取无用中文关键词 waste = f1.read() f1.close() for i in [' ','\n']: nov = nov.replace(i, '') #jieba添加词典与关键词 jieba.add_word("汤浅政明") jieba.add_word("Netflix") jieba.load_userdict('恶魔人关键字.txt') novel=jieba.lcut(nov) #用jieba切割nov #token过滤无用关键词 waste=waste.split('\n') tokens = [token for token in novel if token not in waste] Set = set(tokens)#把tokens转换为集合方便字典统计 Dict = {} # 创建一个字典统计词频 for i in Set: Dict[i] = tokens.count(i) TopList = list(Dict.items()) # 转换成列表进行排序 TopList.sort(key = lambda x: x[1], reverse=True) # 按照词频降序排列 for i in range(20): #输出前20 print(TopList[i]) pd.DataFrame(data=TopList[0:20]).to_csv('恶魔人短评关键词top20.csv', encoding='utf-8') #生成词云图,进行字体变量配置后用空格分割内容 wl_split=' '.join(tokens) bg = np.array(Image.open("shape.png")) mywc = WordCloud( mask=bg, min_font_size=40, font_path='C:/Windows/Fonts/simkai.ttf' #中文处理,用系统自带的字体 ).generate(wl_split) my_font = fm.FontProperties(fname='C:/Windows/Fonts/simkai.ttf') # image_colors = ImageColorGenerator(bg) # mywc.recolor(color_func=image_colors) plt.imshow(mywc, interpolation='bilinear') plt.axis("off") plt.tight_layout() plt.show() mywc.to_file("crybaby.png")
生成的csv文件:
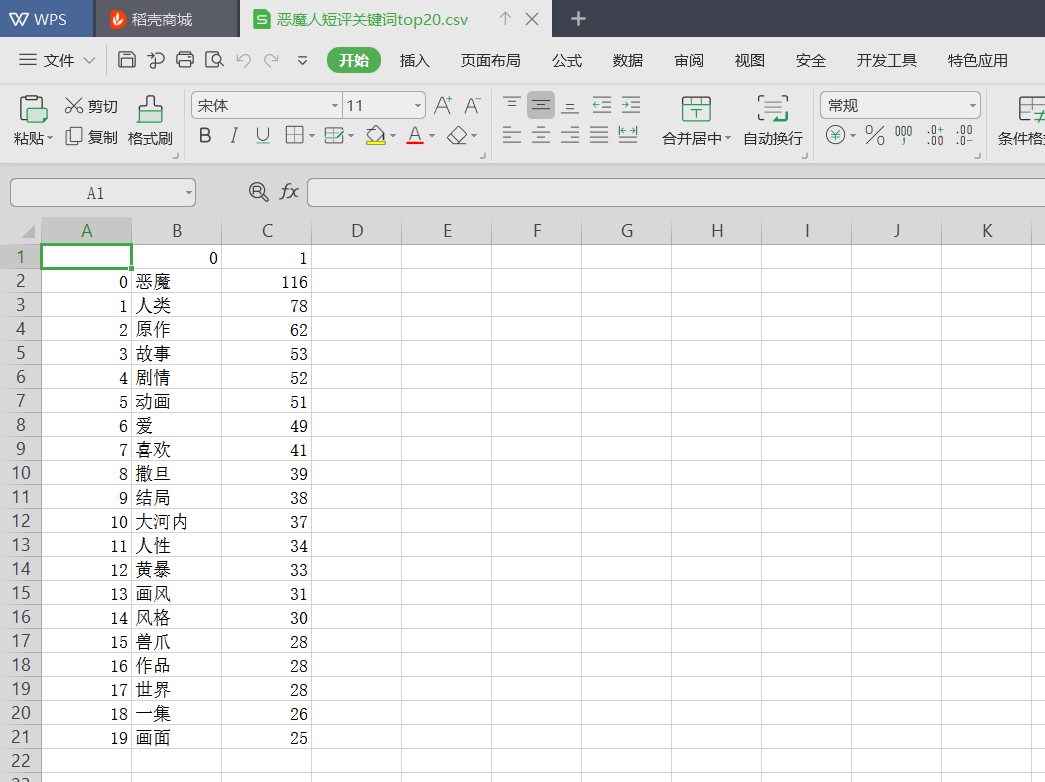
保存到MySQL数据库
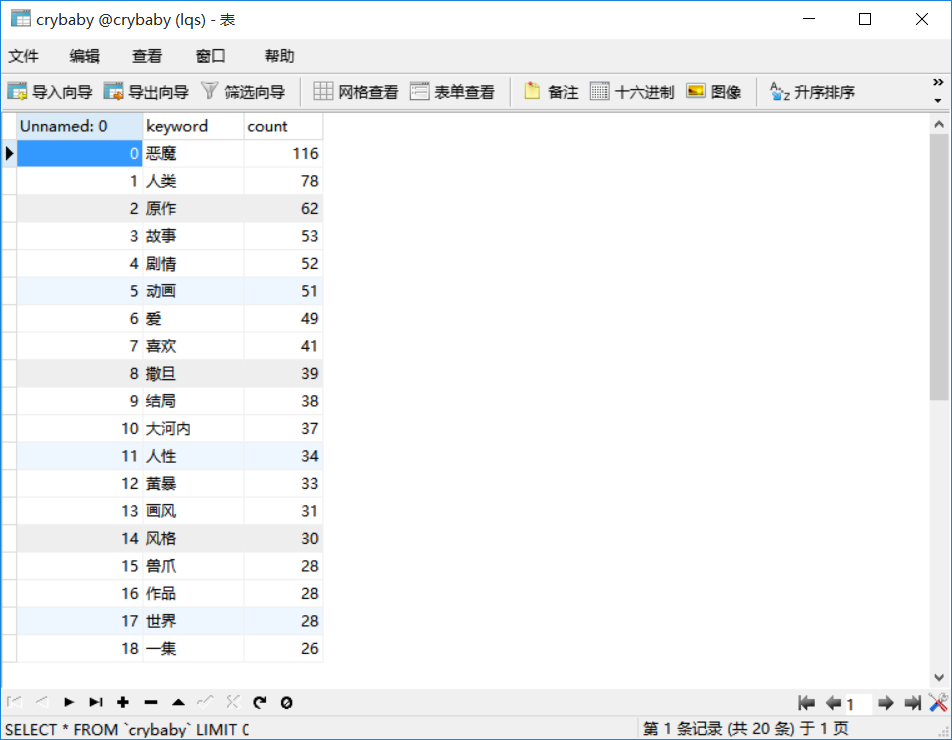
from pandas import DataFrame import pandas as pd import pymysql from sqlalchemy import create_engine newsdf = pd.read_csv(r'恶魔人短评关键词top20.csv', engine='python') conInfo = r"mysql+pymysql://root:123456@localhost:3306/crybaby?charset=utf8" engine = create_engine(conInfo,encoding='utf-8') newsdf.to_sql(name='crybaby', con=engine, if_exists='append', index=False)
保存后的MYSQL效果图
但是个人对pycharm生成的词云图不满意,所以后面去wordcloud网站生成自己喜欢的词云图,效果如下:

以恶魔人crybaby的海报图作素材,生成了我喜欢的词云形状,一眼看去人性、恶魔、人类、黄暴等有冲击力的词汇扑面而来,可见这是一部有宗教色彩,让观众探讨人性,令人深思的动画。
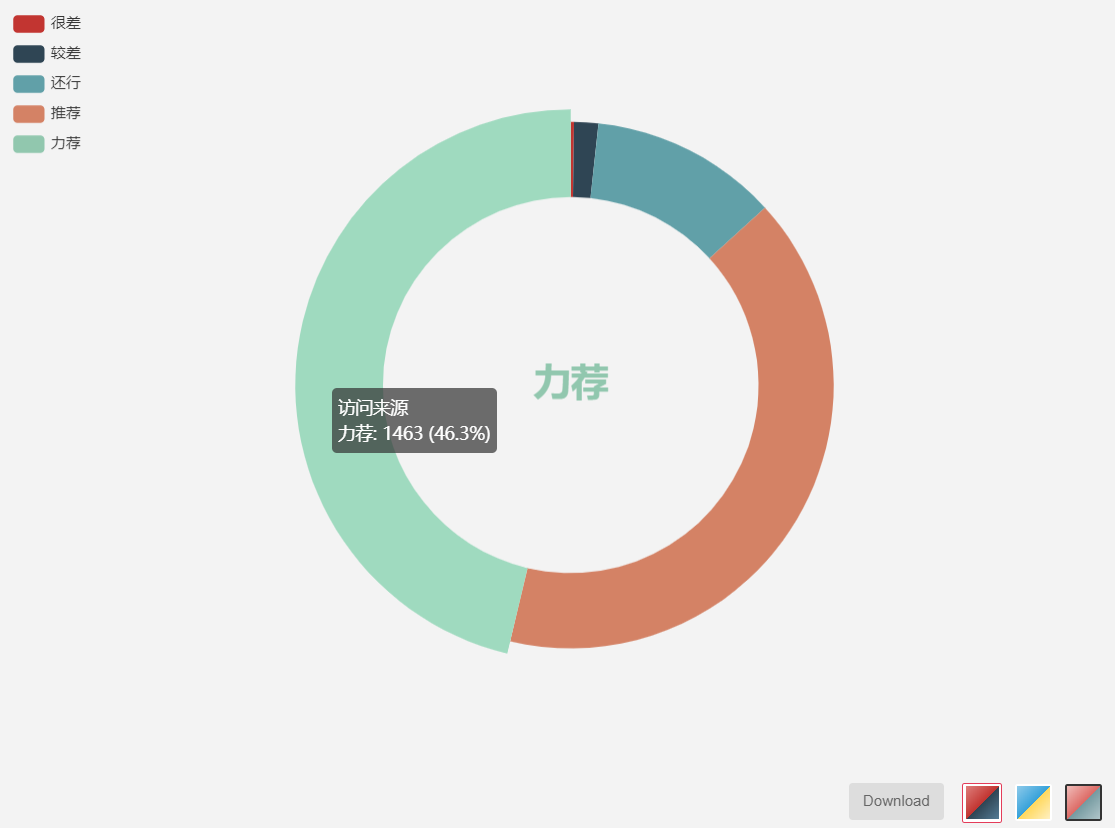
把数据进行图像化处理得出上图,好评率高达88.2%,总体来说这是一部好评甚多的一部深度优良动漫,不过根据词云图与个人观感,这部动漫观看时需要有健康稳固的三观才能正视这部上世纪佳作想表达的情感思想内核,在“黄暴“、”人性”、“恶魔”,“人类”等尖锐的词云关键词中却仍然能隐隐约约地看到“”爱”这一关键词,看出本作在黄暴与人性的恶劣中寻求人性真善美的那些光亮,人性有多恶劣,人性就有多高洁,作品在多处的残暴血腥描写中却流露出对生命的悲悯,因为悲伤,所以有爱。
补充:
在6月19号时本人想提高爬虫爬取能力爬取更多数据,增加不同的user-agent与cookie、代理等防防爬功能时发现可能爬取的太频繁导致账号被永封。。IP地址也被记录了 

 浙公网安备 33010602011771号
浙公网安备 33010602011771号