
本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2881
1. 简单说明爬虫原理
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
3).了解网页
写一个简单的html文件,包含多个标签,类,id
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
3.提取一篇校园新闻的标题、发布时间、发布单位、作者、点击次数、内容等信息
如url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
要求发布时间为datetime类型,点击次数为数值型,其它是字符串类型。
一、简单说明爬虫原理
爬虫是向特定的URL发起request,获取response,进行下载网页解析内容,保存数据的自动化程序。
二、简单说明浏览器工作原理
浏览器解析HTML构建dom树,根据dom树构建出渲染树,然后利用操作系统底层API对渲染树进行绘制渲染得到可视化网页。
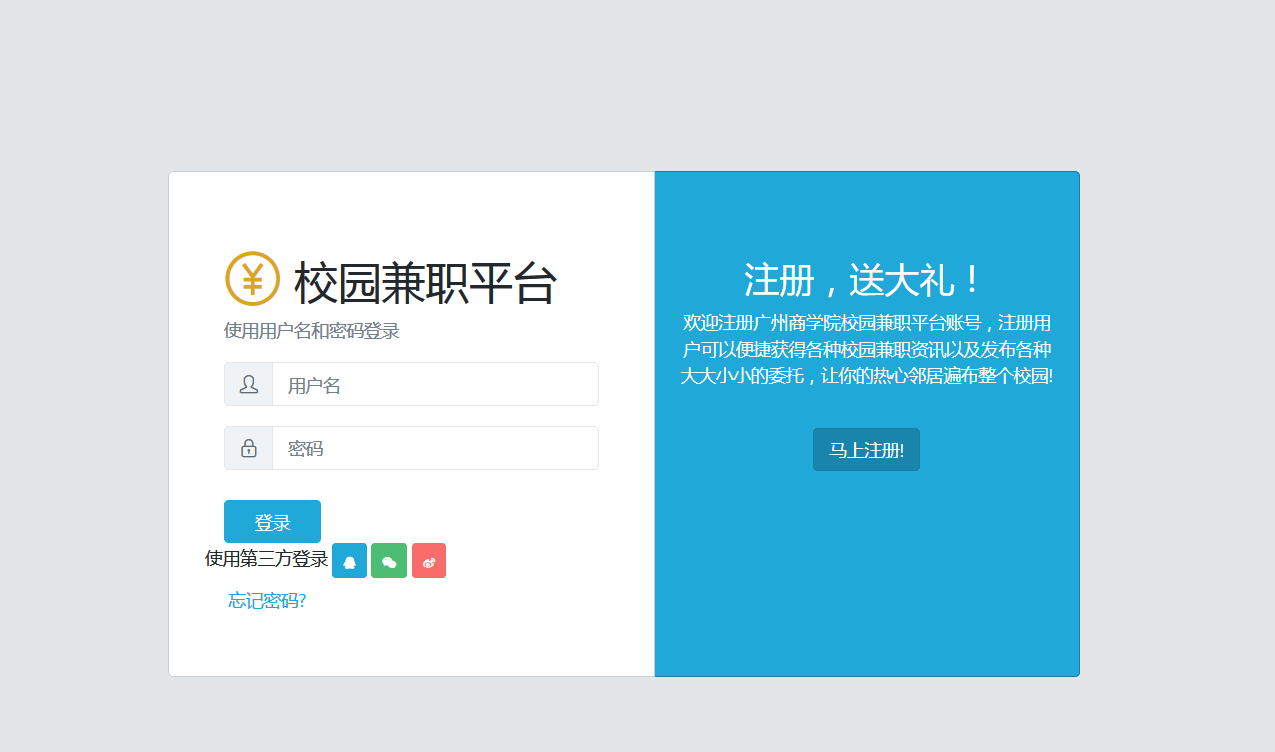
三、写一个简单的html文件,包含多个标签,类,id
<!DOCTYPE html> <html lang="en"> <head> <base href="./"> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0, shrink-to-fit=no"> <meta name="description" content="CoreUI - Open Source Bootstrap Admin Template"> <meta name="author" content="Łukasz Holeczek"> <meta name="keyword" content="Bootstrap,Admin,Template,Open,Source,jQuery,CSS,HTML,RWD,Dashboard"> <title>CoreUI Free Bootstrap Admin Template</title> <!-- Icons--> <link href="vendors/@coreui/icons/css/coreui-icons.min.css" rel="stylesheet"> <link href="vendors/flag-icon-css/css/flag-icon.min.css" rel="stylesheet"> <link href="vendors/font-awesome/css/font-awesome.min.css" rel="stylesheet"> <link href="vendors/simple-line-icons/css/simple-line-icons.css" rel="stylesheet"> <!-- Main styles for this application--> <link href="style.css" rel="stylesheet"> <link href="vendors/pace-progress/css/pace.min.css" rel="stylesheet"> </head> <body class="app flex-row align-items-center"> <div class="container"> <div class="row justify-content-center"> <div class="col-md-8"> <div class="card-group"> <div class="card p-4"> <div class="card-body"> <form action="/login" method="post" enctype="multipart/form-data"></form> <h1><i class="fa cui-yen fa-lg mt-4" style="color:goldenrod"></i> 校园兼职平台</h1> <p class="text-muted">使用用户名和密码登录</p> <div class="input-group mb-3"> <div class="input-group-prepend"> <span class="input-group-text"> <i class="icon-user"></i> </span> </div> <input class="form-control" type="text" placeholder="用户名"> </div> <div class="input-group mb-4"> <div class="input-group-prepend"> <span class="input-group-text"> <i class="icon-lock"></i> </span> </div> <input class="form-control" type="password" placeholder="密码"> </div> <div class="row"> <div class="col-6"> <button class="btn btn-primary px-4" type="button">登录</button><br> </div> <span><a>使用第三方登录</a><span> <span> <button class="btn btn-primary btn-sm" type="button"><i class="fa fa-qq small" ></i></button> <button class="btn btn-success btn-sm " type="button"><i class="fa fa-wechat small"></i></button> <button class="btn btn-danger btn-sm " type="button"><i class="fa fa-weibo small"></i></button> </span> <div class="col-6 text-right"> <button class="btn btn-link px-0" type="button">忘记密码?</button> </div> </div> </div> </div> <div class="card text-white bg-primary py-5 d-md-down-none" style="width:44%"> <div class="card-body text-center"> <div> <h2>注册,送大礼!</h2> <p>欢迎注册广州商学院校园兼职平台账号,注册用户可以便捷获得各种校园兼职资讯以及发布各种大大小小的委托,让你的热心邻居遍布整个校园!</p> <button class="btn btn-primary active mt-3" type="button">马上注册!</button> </div> </div> </div> </div> </div> </div> </div> <!-- CoreUI and necessary plugins--> <script src="vendors/jquery/js/jquery.min.js"></script> <script src="vendors/popper.js/js/popper.min.js"></script> <script src="vendors/bootstrap/js/bootstrap.min.js"></script> <script src="vendors/pace-progress/js/pace.min.js"></script> <script src="vendors/perfect-scrollbar/js/perfect-scrollbar.min.js"></script> <script src="vendors/@coreui/coreui/js/coreui.min.js"></script> </body> </html>
效果图:
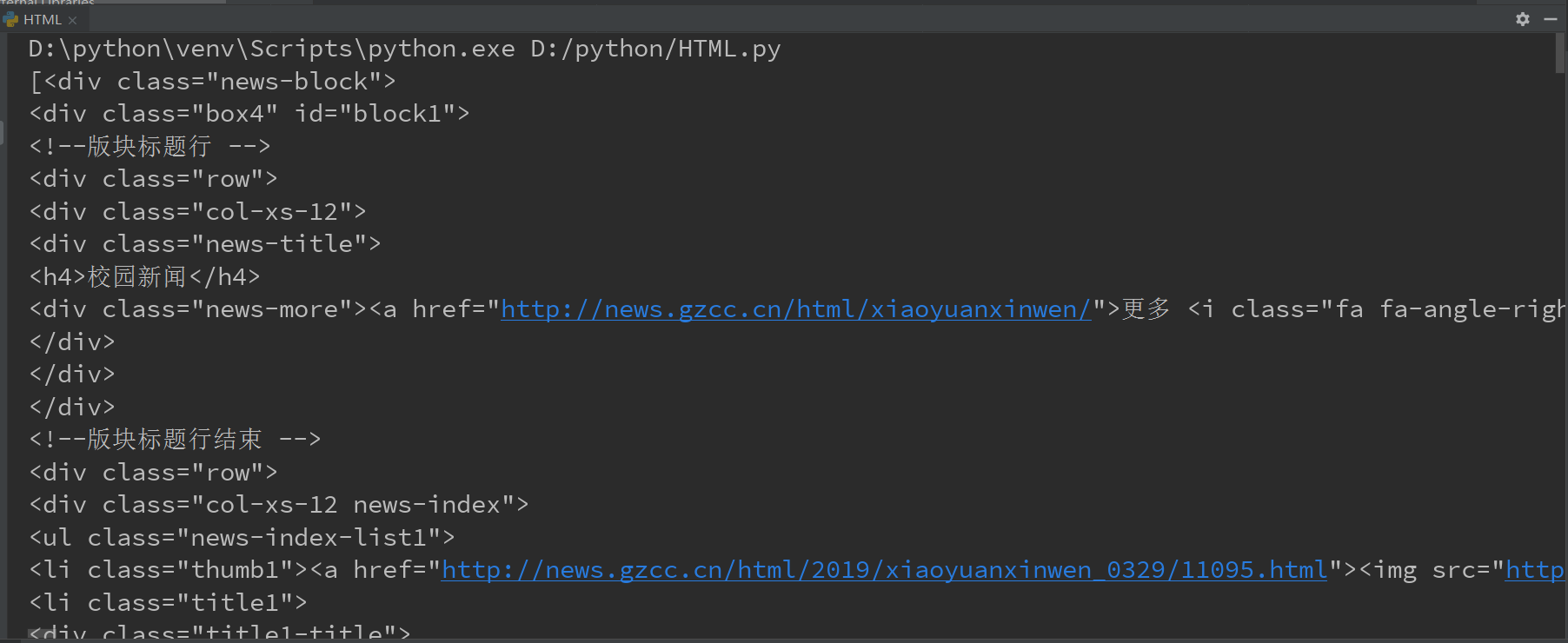
四、使用 Beautiful Soup 解析网页
from bs4 import BeautifulSoup
import requests
url = "http://news.gzcc.cn/"
res = requests.get(url) #requests后面的方法要根据网页的请求信息来判断
res.encoding = 'utf-8' #爬虫结果乱码,可以用UTF-8解码更正
soup = BeautifulSoup(res.text, 'html.parser')
news_block = soup.select('.news-block')
NB_example = soup.select('#navbar-example')
TAG_a=soup.select('a')
print(news_block)
print(NB_example)
print(TAG_a)
结果截图:
五、提取一篇校园新闻的标题、发布时间、发布单位、作者、点击次数、内容等信息
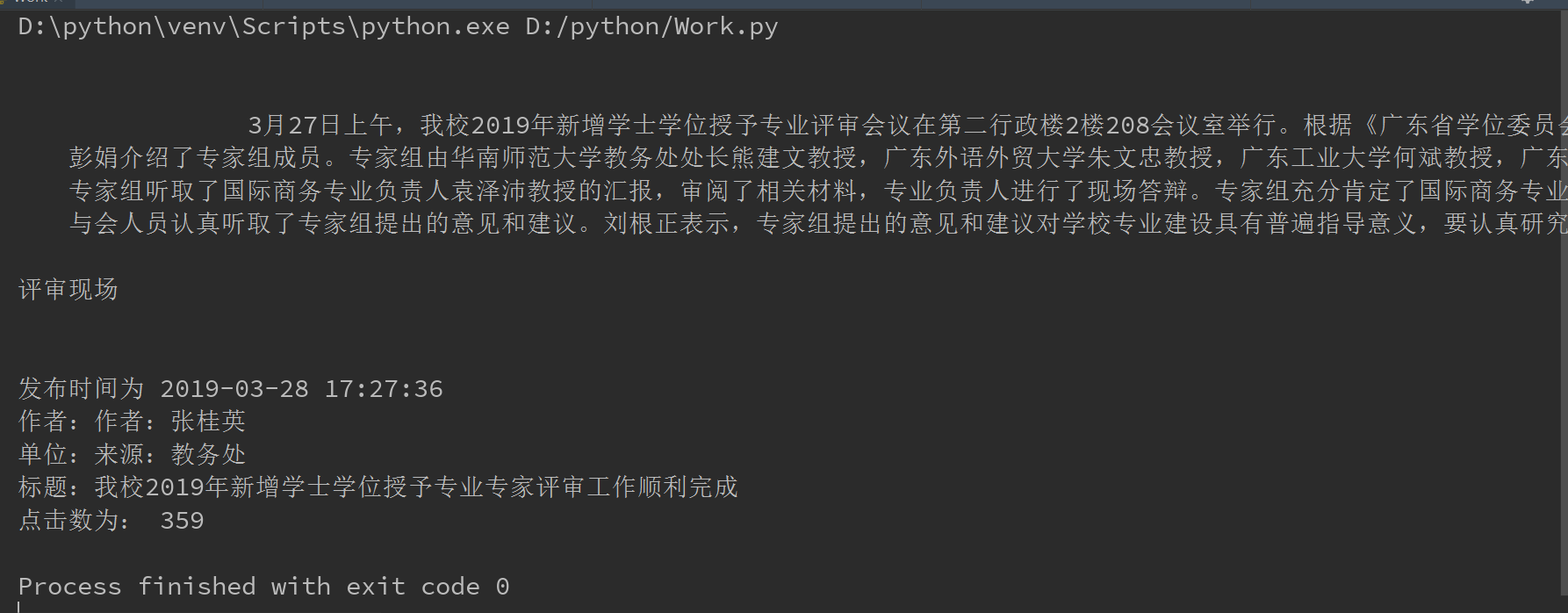
from datetime import datetime from bs4 import BeautifulSoup import requests #用beautifsoup LXML解析器方法来解析网址 url = "http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0328/11086.html" res = requests.get(url) #requests后面的方法要根据网页的请求信息来判断 res.encoding = 'utf-8' #爬虫结果乱码,可以用UTF-8解码更正 soup = BeautifulSoup(res.text,"lxml") #把选择class=show-info的部分html代码截取,提取新闻内容 content = soup.select('.show-content')[0].text print(content) #把选择class=show-info的部分html代码截取,进行切片清洗,把时间用datetime方法处理 soup1 = soup.select('.show-info')[0].text.split() date = soup1[0].split(':')[1] #把发布时间:XXXX另外切片得到要的日期 time = soup1[1] DateTime = datetime.strptime(date+' '+time, '%Y-%m-%d %H:%M:%S') print('发布时间为',DateTime) #作者、发布单位、标题 poster = soup1[2] danwei=soup1[4] title=soup.select('.show-title')[0].text print('作者:'+poster+'\n单位:'+danwei+'\n标题:'+title) #点击数 url = 'http://oa.gzcc.cn/api.php?op=count&id=11047&modelid=80' res_click = requests.get(url).text #不用解析直接获取文本 res_click = int(res_click.split('.html')[-1][2:5]) #最后一个html括号里面放置的是总点击数,同时转整型 print('点击数为:',res_click)
结果截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号