
本次作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
1.列表,元组,字典,集合分别如何增删改查及遍历。
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式
3.词频统计
-
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
8.输出TOP(20)
- 9.可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')
线上工具生成词云:
https://wordart.com/create
作业博客要求:
- 文字作业要求言简意骇,用自己的话说明清楚。
- 编码作业要求放上代码,加好注释,并附上运行结果截图。
一、列表的增、删、改、查
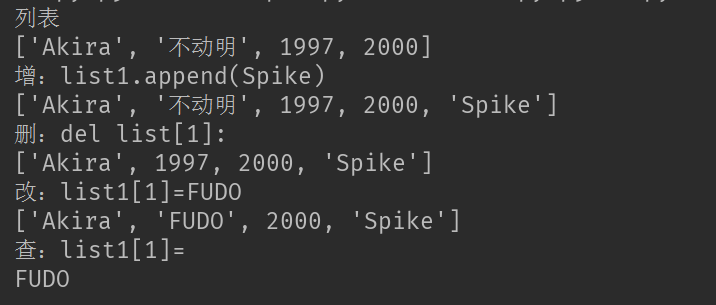
list1 = ['Akira', '不动明', 1997, 2000] print('列表') print(list1) list1.append('Spike') print('增:list1.append(Spike)') print(list1) del list1[1] print('删:del list[1]:') print(list1) list1[1]='FUDO' print('改:list1[1]=FUDO') print(list1) print('查:list1[1]=') print(list1[1])
二、元组的增、删、改、查
tuple1 =('Akira', '不动明', 1997, 2000) tuple2 =(1, 2) print('元组') print(tuple1) tuple3=tuple1+tuple2 print('增与改:元组中的元素值是不允许修改的,但我们可以对元组进行连接组合->tup3 = tup1 + tup2') print(tuple3) print('删:元组不可以删除元素但是可以删除整个元组') print('查:tuple1[0:4]=') print(tuple1[0:4])

三、字典的增、删、改、查
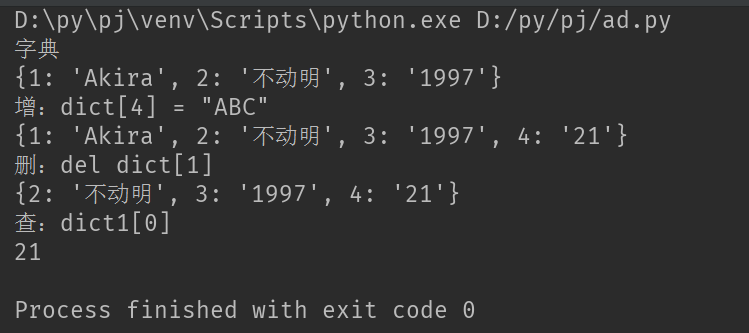
dict1 ={1:'Akira', 2:'不动明', 3:'1997'}
print('字典')
print(dict1)
dict1.update({4: '21'})
print('增:dict[4] = "ABC"')
print(dict1)
del dict1[1]
print('删:del dict[1]')
print(dict1)
print('查:dict1[4]')
print(dict1[4])
四、集合的增、删、改、查
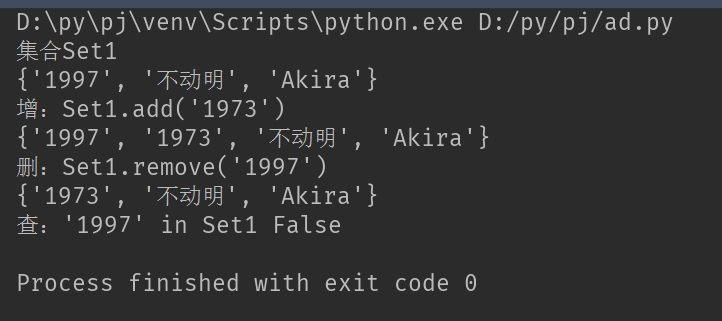
Set1 ={'Akira', '不动明', '1997'}
print('集合Set1')
print(Set1)
Set1.add('1973')
print('增:Set1.add(\'1973\')')
print(Set1)
Set1.discard('1997')
print('删:Set1.discard(\'1997\')')
print(Set1)
print('查:\'1997\' in Set1','1997' in Set1)
五、总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式
(1)括号
列表为[ ],元组为( ),字典与集合为{ }。
(2)有序无序
列表与元组有序,字典与集合无序。
(3)可变不可变
列表与字典可变,元组与集合不可以变。
(4)重复不可重复
列表元组集合都可重复,只有字典不可重复。
(5)存储与查找方式
列表和元组都是值,字典是键,集合是键对值
六、词频统计
-
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
8.输出TOP(20)
- 9.可视化:词云
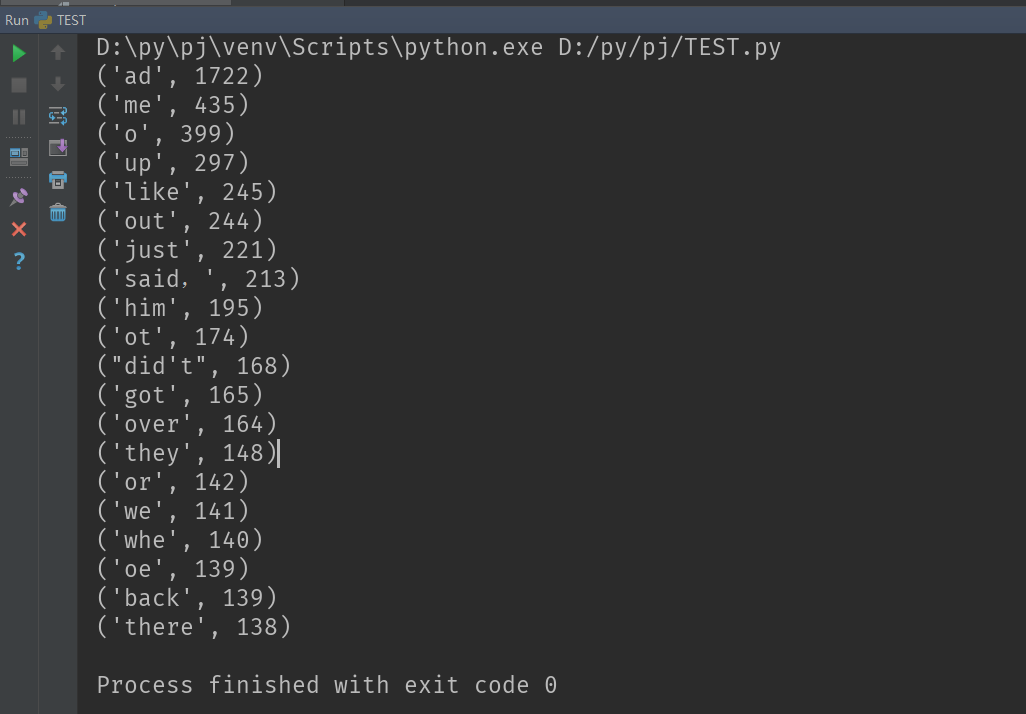
import pandas as pd f = open('novel.txt', 'r', encoding='utf-8') nov = f.read() f.close() nov = nov.lower() waste = r',.;!\n-_' #创建过滤字符串 for i in waste: nov = nov.replace(i, '') List = nov.split(' ') # 生成列表存储预处理完毕的单词 Set = set(List) # 同时用SET进行集合形式的存储,为下面集合减去无意义单词铺垫 useless = { 'the', 'and', 'of', 'to', 'a', 'in', 'was', 'she', 'her', 'had', 'that', 'it', 'with', 'i', 'mr', 'but', 'by', 'said', 'be', 'were', 'which', 'from', 'which', 'this', 'an', 'on', 'he', 'for', 'you', 'as', 'his', 'not', 'at', 'mrs','my','is','have','so','all','what','about','ever'} # 定义无用集合 Set = Set - useless # 处理无用单词 Dict = {} # 创建一个字典统计词频 for i in Set: Dict[i] = List.count(i) TopList = list(Dict.items()) # 转换成列表进行排序 TopList.sort(key=lambda x: x[1], reverse=True) # 按照词频降序排列 # 输出前20 for i in range(20): print(TopList[i]) pd.DataFrame(data=TopList[0:20]).to_csv('top20.csv', encoding='utf-8')
生成的TOP20.CSV如下:

运行截图:
词云图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号