

从软件(Java/hotspot/Linux)到硬件(硬件架构)分析互斥操作的本质
先上结论:
一切互斥操作的依赖是 自旋锁(spin_lock),互斥量(semaphore)等其他需要队列的实现均需要自选锁保证临界区互斥访问。
而自旋锁需要xcmpchg等类似的可提供CAS操作的硬件指令提供原子性 和 可见性,(xcmpchg会锁总线或缓存行,一切会锁总线或缓存行的操作都会刷StoreBuffer,起到写屏障的操作)
所以,任意的互斥操作,无论是 java 层面,hotspot层面,linux层面 的根本依赖都是 xcmpchg 等硬件指令。java算是上层,需要依赖hotspot和linux嵌入的汇编完成xcmpchg的调用。
所有同步手段的根本是硬件,软件是辅助手段,软件和硬件的交界面是用于并发控制的硬件指令(如 cmpchg, 带lock前缀的指令,lwsync, sfence 等)
整个依赖链条:
1. Java 的并发工具包 JUC 中大部分同步工具类依赖 AQS 为他们提供队列服务和资源控制服务。
2. AQS 依赖 LockSupport 的 park 和 unpark 为他提供线程休眠唤醒操作
3. LockSupport 的 park 和 unpark 是依赖 JVM(此处语境讨论 Hotspot)调用操作系统的 pthread_mutex_lock 和 pthread_cond_wait , 前者是保护后者和 counter 变量的互斥锁,保证只有一个线程操作 counter 变量和 condtion 上的等待队列
4. pthread_mutex_wait 依赖于 操作系统的 futex 机制,多个用户态的线程(Java线程,即Mutator)通过用户空间相同,物理页共享,共同争抢受写屏障增强,线程可见性强的资源变量。如果抢不到,需要用 futex_wait 系统调用,具体是委托内核查看该变量是否还是 futex_wait 的入参(争抢失败后的值),如果是,则让内核将自己从 runqueue(Linux下的就绪进程队列)摘下来,并且状态设为 TASK_INTERRUABLE,表示不需要继续执行,但是可以用信号唤醒,如果不是,返回用户空间,再次争抢
5. futex_wait 和 futex_wakeup 依赖 spin_lock保护桶bucket,其实保护bucket上的一整条链表
6. 操作系统的 down , up 依赖 spin_lock 保护等待队列和资源变量
硬件层
预备知识:
写屏障:
简化微机架构(Intel X86):
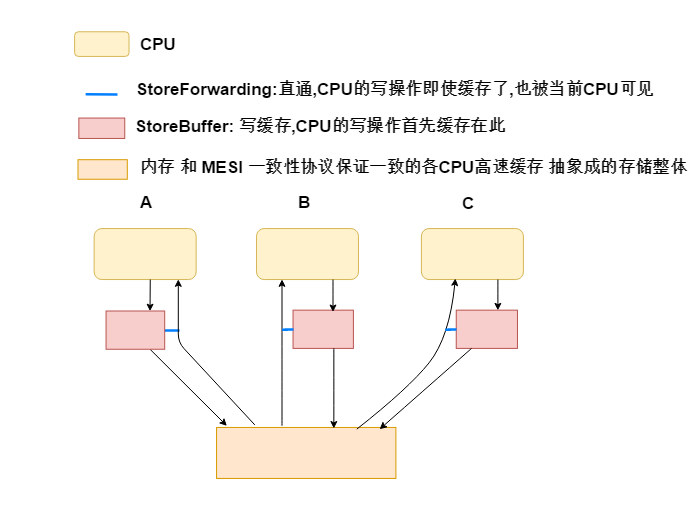
无写屏障:
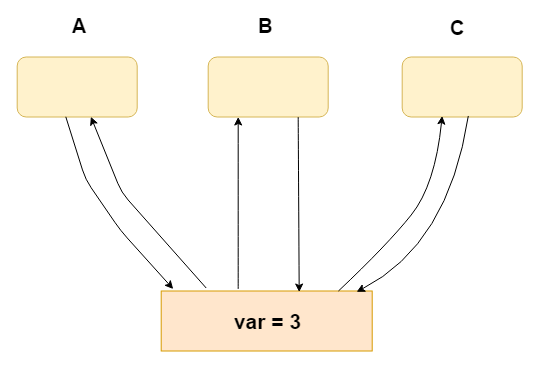
1.假设有变量var
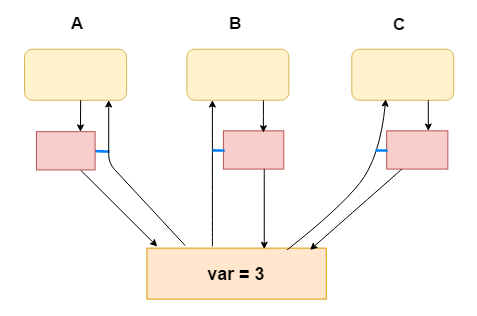
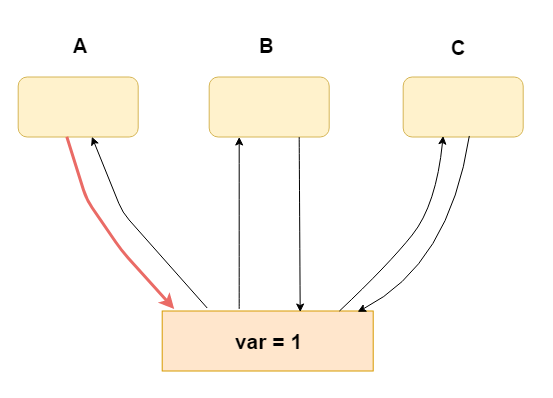
2. CPU A(进程/线程A) 修改 var = 1
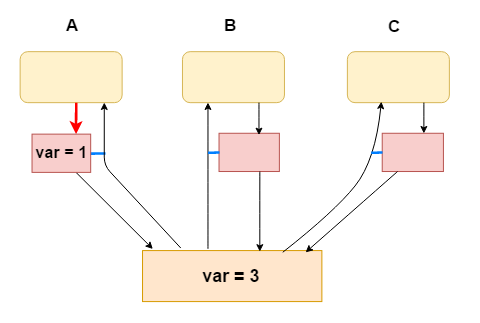
3. CPU C(进程/线程C) 读取到 var = 3, 无法立刻得到 A 的修改
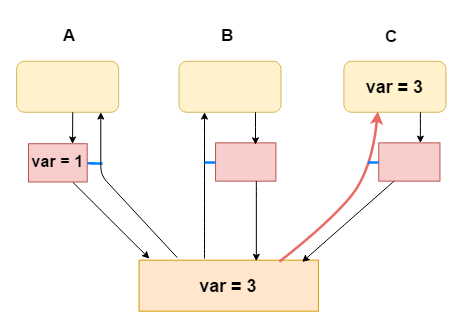
有写屏障(A,B,C任意CPU在修改完某个变量后均使用写屏障):
上面的微机架构可以简化成:
1.A修改var
2.C立刻可见
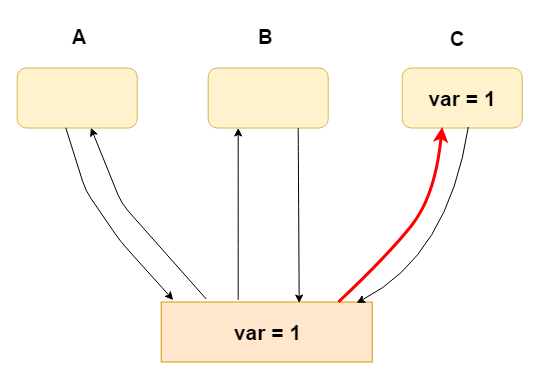
使用写屏障类似:
var = 1;
write_fence_here(); // 写屏障
作用只是将 storeBuffer中的内容马上刷出到 自己的高速缓存中,因为高速缓存有MESI缓存一致性协议,所以其他CPU读取该变量,将是一直的新值(即使穿透缓存直接读取内存也是一样一致)
读屏障本文不讨论,其本身作用是将 Invalidate Queue 中的无效化请求应用到自己独享的缓存中,以便不去读之前的旧数据。而是因为缓存行已经 Invalidated,而去 从其他CPU或内存读取最新数据。
操作系统层
自旋锁和队列锁(一般互斥量是队列锁):
1.自旋锁简化:
while (true) { if (compareAndSet(期望的旧值, 新值)) { return; } }
自旋锁在Linux中写作 spin_lock ,spin 本身有“连轴转”的意思。自旋锁的本质是获取不到资源就一直空转。
compareAndSet : 类似下面代码,但是被包装成 一条硬件指令,所以是原子的,在他执行的中间,不能有别的CPU插手这个内存的操作。
并且CAS要么全部完成,要么不执行,不能只执行一半,因为他是一条锁了总线或缓存行的硬件指令。在SMP条件下,如果不锁总线或缓存行,指令也不是原子的,比如ADD(read-write-read),只有微操作是原子的。
比如将某个值打入某个寄存器中(write)。
boolean compareAndSet (期望的旧值, 新值) { if (变量值 == 期望的旧值) { 变量 = 新值; return true; } return false; }
2. 队列锁简化:
addToQueue: 将线程/进程的TCB/PCB(在linux是task_struct),放入等待队列,当持有资源的线程释放资源的时候会唤醒等待队列中线程(PCB/TCP就是代表进程/线程的结构)。
并且将进程/线程的 状态设为非运行状态(linux中一般使用TASK_INTERRUPTABLE), 并从就绪队列上摘下来(Linux上是runqueue)
schedule :当前线程已设置为非运行状态,所以会选择其他线程占用CPU, 当前线程在此点睡眠
while (true) { if (!compareAndSet(期望旧值,新值)) { // 尝试获取资源,如:compareAndSet(原资源数,原资源数 - 1) addToQueue(当前线程PCB/TCB); // 获取不到就进入等待队列 schedule();// 睡眠,让出CPU } }
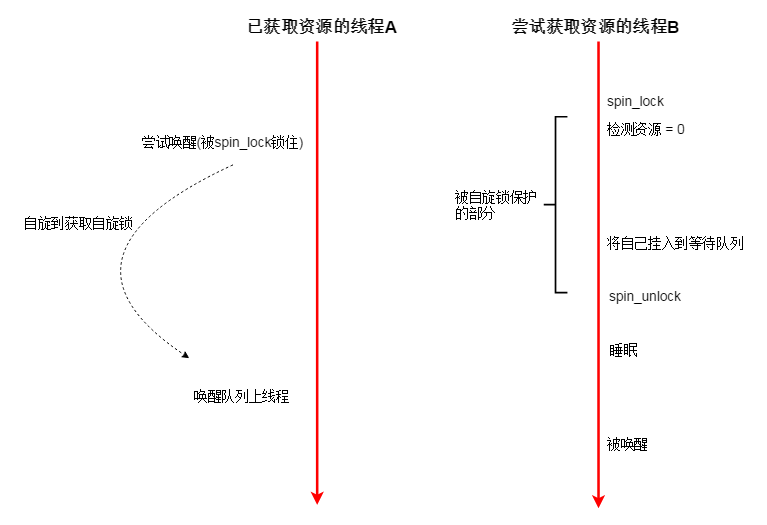
为什么说互斥量(队列锁)依赖自旋锁?
假设有以下情况:(互斥量对应资源初始值=1)
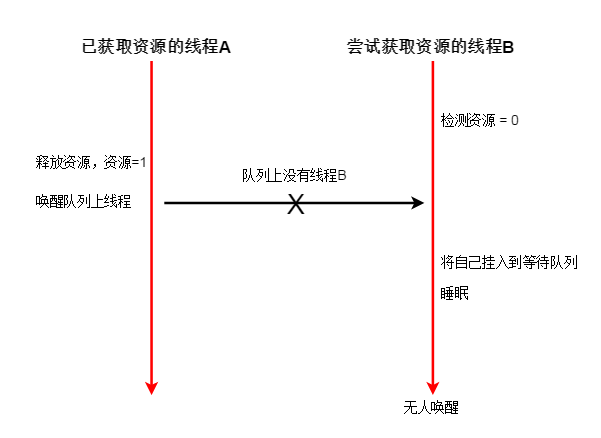
如此一来,明明有资源,但是线程B却无法被唤醒。
究其原因,是因为B的 检测资源-挂入等待队列-睡眠 这三个阶段,不是原子的。线程A 可以修改资源,让资源变成1。
线程A对资源的操作插入到了线程B的操作之中,使得B的操作集合中语句前后所处的状态不一致,即非原子的,受干扰的(区别于事物原子性)。
可以使用自旋锁保护 资源,在读取资源时,其他线程不能修改资源,那么释放操作就会被放到睡眠之后:
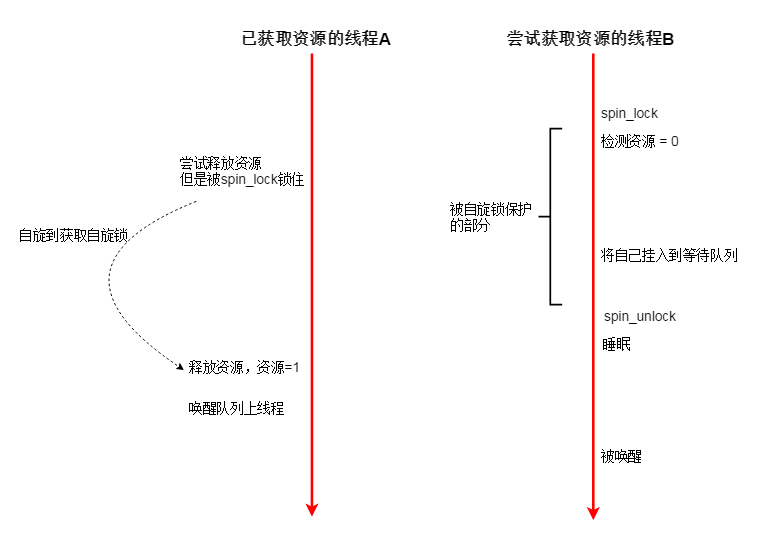
为何可以使用自旋锁? 因为自旋锁不涉及队列,如果线程无法获取自旋锁,就在CPU 上空转,直到获取为止,不需要队列去存储他们,所以不会出现多个线程修改一个队列的情况。
也不会睡眠,所以也不会出现因为睡眠而错过资源的情况,像上二张图就是错过资源的情况,自选锁一直都在争抢。
但是自旋锁的局限性也很大,空转,无意义的CPU时间被浪费。所以只有竞争不是很激烈,以及占用锁时间不长的情况,才使用自旋锁。
这里的对队列操作,只是简单地读取一下变量,和在链表上挂一个节点,很快。
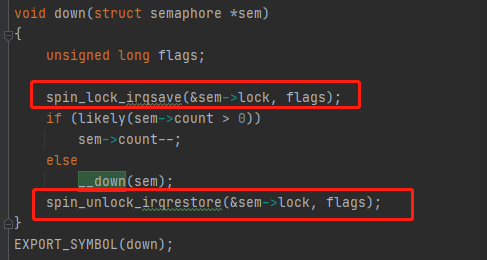
在Linux(3.0.7)下的实现:
up 操作是释放互斥量资源,down 操作是获取互斥量资源

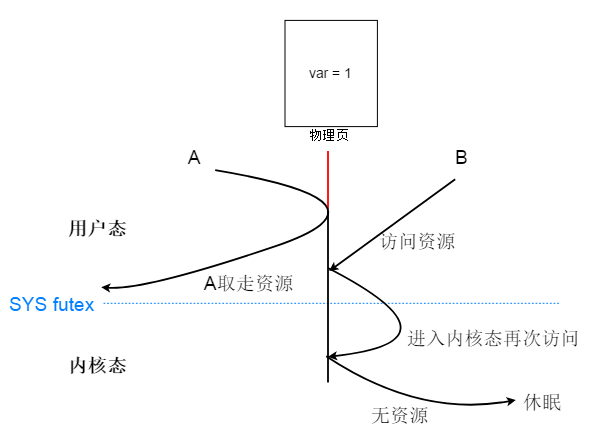
futex(fast user mutex):之所以称为 user mutex,是因为多个用户态线程通过一块共享内存存储代表资源的变量,多个用户态线程对这个资源的操作是原子性的,这是在用户态的操作。
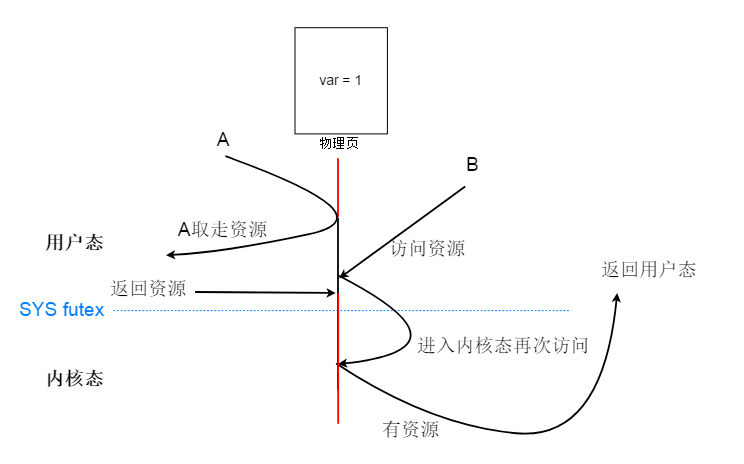
当用户线程发现自己争抢不到资源,才委托系统调用帮自己检查一下这个变量还是不是刚才读到的变量,如果是就当前线程休眠,所以是在用户态判断是否可以获取资源,不行再使用系统调用陷入内核态。比如说,我有一块内存页,被A,B两个线程共享,这个内存页里有个变量 var ,表示资源的个数,一开始是1。线程A和B都是通过CAS型的硬件指令去设置这个资源,即操作是原子性的。假如一开始A,CAS 抢夺成功,资源var 变成 0。资源B 直接通过自己的页面映射表去到这个共享的物理页,读取一下,发现是0,那么当前表示无资源可用。B将会使用系统调用,委托操作系统检查,这个资源是不是还是0,如果是就将自己休眠,否则B退出内核态回到用户态。为什么要委托操作系统再检查一次呢?因为有可能A已经释放资源了,B只要再CAS一次就能获得资源。
futex 机制的实现比较简单,基于散列表:
每一个futex_key代表一个共享变量,即资源。
每一个节点包裹着 futex_key
每一个futex_bucket代表一个hash桶,也就是hash表中的某个位置
一个 futex_bucket 的链表中,有不同节点,说明有不同资源。比如说,“萤石” 是一种资源,“红石”也是一种资源,他们的数量所代表的变量(地址)的节点会存在于下图的同一个链表上
每个bucket都有一个 锁 可以被自旋锁 锁定,锁的单位是 一个 bucket上的链表,所以当一种资源需要加锁,会锁到链表上的其他资源。
设计者这么做其实并不过分,因为一个桶中的链表长度并不是很长,而且spin_lock是短时间锁,将锁粒度控制在整个散列表一个锁和每个节点一个锁之间,是对空间和时间的权衡。
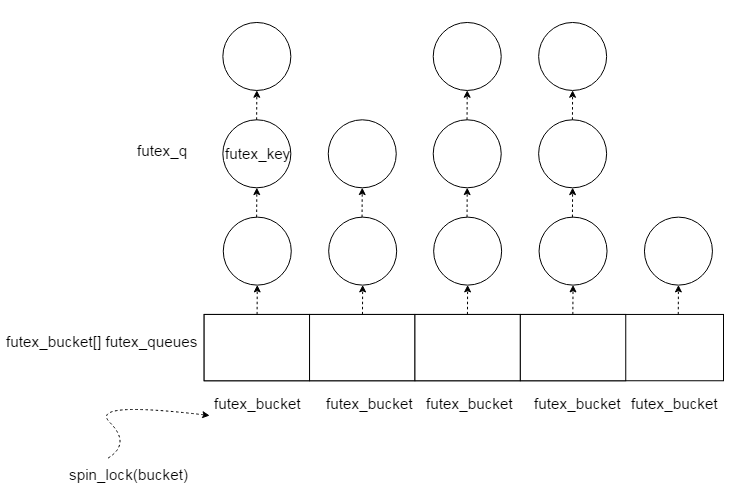
futex在 线程处于内核态 ,读取资源 之前,会用 spin_lock 锁住 bucket,读取资源后发现没有资源会把自己挂入等待队列,然后释放spin_lock 。
持有资源的线程在唤醒等待队列中线程之前,同样要用 spin_lock 锁住同样位置的 bucket。
下图是 futex 的互斥机制,可能会有疑问:获取资源不用算进去吗?
这和程序顺序有关,释放资源肯定在唤醒之前的,这是必须遵循的,因为释放完资源才会去唤醒进程去争夺
那么唤醒等待队列这个操作可能在 被自旋锁保护区域的上面或者下面。
如果在上面,那么资源在唤醒之前就释放了,保护区里肯定可以得到资源,免于睡眠。
如果在下面,那么无论资源在唤醒之前的哪个位置,就算是在保护区里也好,只要是释放了就行。因为唤醒操作在保护区之后,而保护区里,要休眠进程已经挂到等待队列。
所以唤醒操作必能唤醒要休眠进程,因为他在 入队操作之后,他能找到那些休眠的进程,从而唤醒他们。
再向上一层看, pthread_mutex_wait 和 pthread_cond_wait,这两个函数是 Hotspot 实现 park 函数依赖的操作系统层面接口。而park函数是 LockSupport.park 方法的本地方法实现。
其中 pthread_cond_wait 是把 Java线程(java应用线程,即Mutator)放入到一个等待队列,这个队列称为条件队列。对应LockSupport.park 方法。
还有一个与之对应的解锁方法,pthread_cond_signal ,是唤醒这个队列上的线程。那么怎么保证对这个等待队列的操作是互斥的呢?如果不互斥,就可能发生下面这钟典型的写覆盖并发问题:
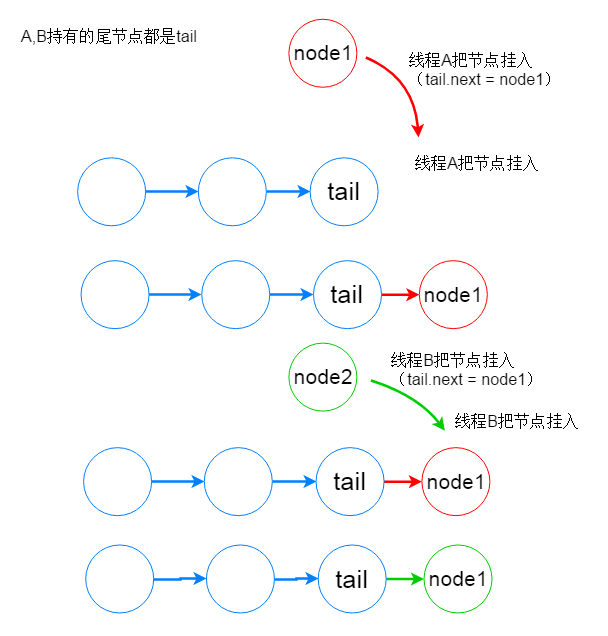
依赖的是 pthread_mutex_lock, 要操作队列之前先获取互斥量,操作完释放互斥量
pthread_mutex_lock(&mutex); pthread_cond_wait(&queue); pthread_mutex_unlock(&mutex);
pthread_mutex_lock 依赖的是上面所说的,futex, 所以 pthread_mutex_lock 就是上面说的,先在用户态读取资源,如果没资源了,就调用 SYS futex 系统调用
jvm(hotspot)层
到这里,操作系统和java层面差不多要连起来了,我们再通过LockSupport向上走。
在 调用LockSupport.unpark 之后调用LockSupport.park 的话,线程不会休眠。这个点很重要,没有这个点 ,JUC中的AQS无法正常工作。
伪代码:xchg相比xcmpchg不会比较,而是直接原子设置相应内存单元的值。
park () { // 之前有资源,直接返回,并且把资源消耗掉 if (xchg(&counter ,1, 0) == 1) { return; } // 准备操作 票据和队列 pthread_mutex_lock(); // 可能之前 获取 mutex 的线程给予了 资源 // 必须要有这一句,否则可能错过释放了的资源,永远无法被唤醒 if (counter == 1) { counter = 0; pthread_mutex_unlock(); return; } pthread_cond_wait(); // 这句为什么在 pthread_cond_wait 之后呢? // 因为这里是线程被唤醒之后的地方,其他线程给了一个资源,当前线程才被唤醒 // 既然被唤醒了,就要去消耗这个资源,这样一唤醒(资源+1),一睡眠(资源-1)。 // 扯平之后就是当前线程的 继续运行状态 counter = 0; pthread_mutex_unlock(); } unpark () { pthread_mutex_lock(); counter = 1; writeBarrierHere(); pthread_cond_signal(); pthread_mutex_unlock(); }
回到刚才的问题:为什么unpark 之后 park 不会休眠在 AQS 中起到关键作用?
java层
假设线程A是已经获取资源,要释放资源的线程
B是尝试获取资源的线程
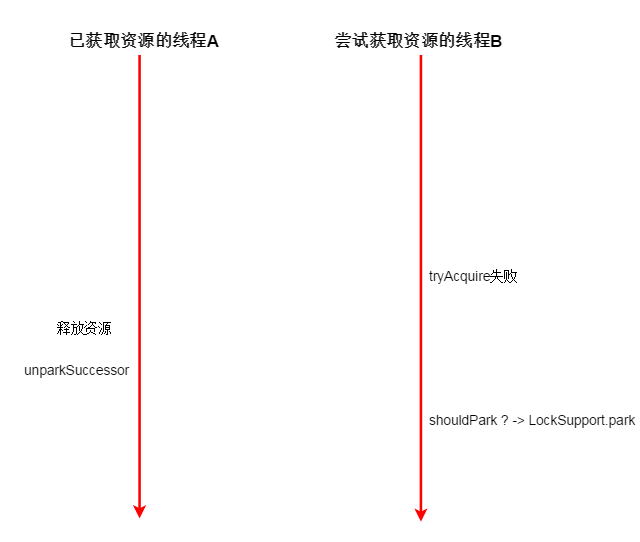
线程A对应下面两处代码:
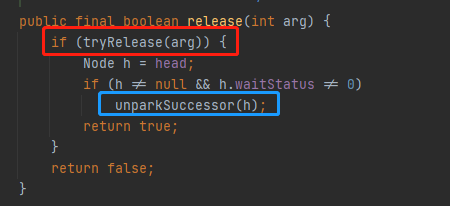
线程B对应下面两处代码。
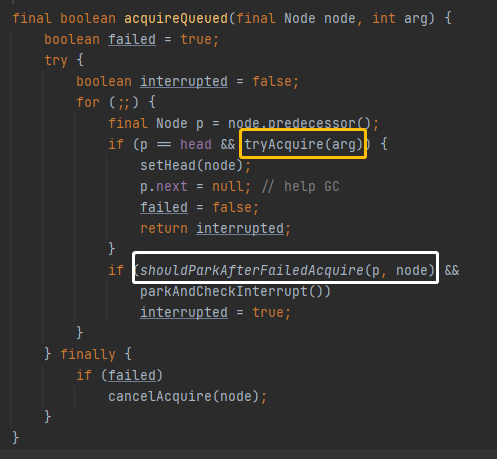
极端一段假设:当线程B执行到下面的绿色处,A执行完成他 release 方法中的两处代码
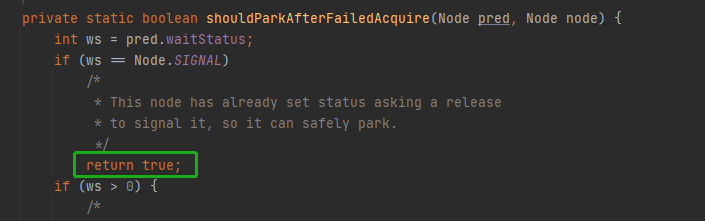
虽然A释放了资源,但是B还是判断要休眠,于是调用LockSupport.park。于是虽然有资源但是B还是调用了park
B真的就这样休眠了吗?不会,奥秘在unparkSuccessor。

他会unpark 头节点的后继。B在调用 acquireQueued之前已经在队列中,所以B的线程会被调用 LockSupport.unpark(B);
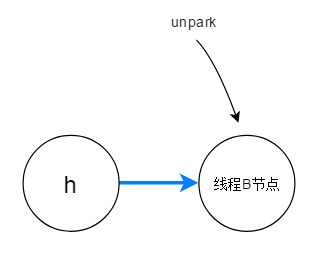
于是B在下次调用 LockSupport.park 的时候不会休眠,可以接着争抢资源!
最后,JUC中的绝大多是同步工具,如Semaphore 和 CountDownLatch 都是依赖AQS的。整个JAVA应用层面到硬件原理层面的同步体系至此介绍完毕。

