Redis - sentinel / cluster
订阅连接:订阅某个频道,频道有消息马上读取,一个频道上的消息会发给多个订阅者,所以是一发多收
命令连接:收发方 简单通过命令通信(udp?)
Redis 主从:
某个 Redis 实例 A 通过 slaveof masterip masterport 指定要成为谁的从服务器
A 会连接到 目标主服务器的 socket 上
之后从服务器会向主服务器发送 PING 命令,主服务器回送 PONG 命令,来测试 socket 建立的信道的可用性,然后是身份认证(如果有),接着是从服务器发送自己的端口(不知什么用),最后是同步:
同步:
新版本的同步策略:
如果从服务器建立连接成为主服务器的从服务器,那么主服务器会生成一个 RDB 文件,并且发送给从节点,并且在发送期间的命令会存在一个 RDB 缓存区,当RDB文件发送完成,会把这个缓存区的数据发送给从节点,直到这个缓冲区为空(如果有新命令进来的话会继续填充)。还有一个缓冲区叫做 命令传播缓冲区,先解释命令传播,接收了主服务器的 RDB 文件后,主服务器每执行一条命令,就会向从服务器传播一条命令,这叫命令传播,命令传播缓冲区是 FIFO 的队列。当一个从节点掉线了,收不到主节点传播的命令,他重新上线的时候,会告知主节点自己最后接受了的命令的偏移量,如果这个偏移量还在命令传播缓冲区里,那么主服务器只用把传播缓冲区中的该偏移量之后的命令发送给掉线的从节点即可。
主从复制的过程总是 Background 的,forki一个线程,先是 执行 BackgroundSaveRDB,然后执行 updateSlavesWaitingBgsave
后者是阻塞地给slaves 发送RDB
【5 4 3 2】1 0,括号里的是队列,如果从服务器发的是 1 ,因为2和之后都在队列里,所以发送队列里的就好了。如果发送的是0,则因为1不在队列,没了,所以要一份完整RDB
否则要重新生成一份完整的 RDB 文件给从服务器,其实就是复现上面第一个步骤。
heartBeat: 从服务器定时向主服务器发送 replconf ack offset ,告知主服务器当前复制的偏移量,这种心跳检测有四种作用
1. 检查从服务器是否存活
2. 检查从服务器和主服务器间通信的延迟
3. 检测从服务器偏移量是否和当前偏移量相同,不同的话就要发送命令,让从服务器偏移量跟上
4. 如果从服务器和主服务器间的通信延迟大于某个值,或者在线从服务器数量小于某个值(某个值都是配置的),就会拒绝 客户端发送的写请求。
Sentinel:
Redis 的 sentinel 保证的高可用环境是 单纯的若干个 主 - 从 服务器集群 (每个集群有一个主服务器,若干从服务器,一个sentinel 可以监视多个这样的集群)
首先要介绍一下 sentinel 自己的集群方式,多个 sentinel 可以形成一个 sentinel 集群。
sentinel 的配置中直接指明 他需要监听的主服务器的 IP 和 端口 (未知是否可以监听多个主)
sentinel 启动的时候直接向 他的主服务器 发送 INFO ,主服务器收到后会发送自己的从服务器列表
sentinel 会通过 主服务器 获得 主服务器的 从服务器列表
因此可以得知从服务器们,并且向从服务器们发送 INFO, 并且从服务器们会回复自己的相关信息,还有自己主服务器是谁
sentinel 是订阅主服务器的 sentinel-hello 频道的,只要有一个sentinel 监听这个主服务器,主服务器就会向这个频道上发送 消息。
如果有多个sentinel 监听这个频道,而且有新的 sentinel 监听主服务器,那么这些监听 主服务器的 sentinel 都会认识到 新的 sentinel
多个 sentinel 之间单纯创建 命令连接,与其他 sentinel 通信
sentinel 与主服务器 ,从服务器之间建立了 命令连接 和 订阅连接
当 sentinel 发现 主服务器下线,此时只有他一个人觉得主服务器下线了,只是他的主观想法,要证明主服务器确实下线,当前 sentinel 就必须去询问 其他的 sentinel,如果超过 quorum 参数(当前 sentinel 的配置中设置的)
当前 sentinel 觉得,这个主服务器是 客观下线了,这时候,他就想把下线的服务器蹬掉,让其他从服务器做为新的主服务器,但是,他不能直接那么做,只有主 sentinel 才能这么做。
当 某个 主服务器被 判断为 客观下线
(难道是一个 sentinel 根据自己的配置觉得主服务器下线,就能告诉其他所有 sentinel 主服务器下线,从而这个主服务器真的都被所有 sentinel 认为是客观下线吗)
( 还是说一个 sentinel 觉得某个主服务器已经客观下线,就直接发起 sentinel 选举?虽然确实只有发现主服务器客观下线的 sentinel 才能让其他人选他自己,应该是的)
所有在线的监听当前主服务器的 sentinel 就要进行一次选举,只有胜出的 sentinel 才能 把主服务器的从服务器提升成新的主服务器,让其他从服务器和旧的主服务器(旧主服务器在 上线之后执行 slaveof) 成为新 主服务器的 从服务器,新服务器执行 slaveof no,剩余服务器 slaveof 新主服务器。
主sentinel 选择算法 为 raft
集群方式:
没有 sentinel,只有主节点 和 从节点
构建集群:
集群中的某个节点(可能这个集群只有一个节点)通过 Cluster Meet 和某个节点握手,建立连接。建立连接之后,新加入的节点和他握手的节点之间互相发送 PING , 并且回应 PONG ,PING 中会带有自己认识的两个节点,这样的话,新加入的节点会通过第一个节点认识到更多节点,通过认识到的更多节点又认识到集群中其他节点,直到整个集群都认识,这是一个类似悄悄话传播的过程,被称为 gossip 协议。最后集群所有节点的已知信息都会收敛到整个集群的信息。

集群中的主从:
某个节点可以通过 Cluster Replicate node_id ,设置要作为 node_id 的从服务器,具体复用了 sentinel 的代码
槽指派:
整个集群的数据 被分为 16384 份,每一份数据被称为一个槽,每个槽对应一个编号(0~16383)。只有主节点才能持有槽,key 根据 CRC16(key) & 16383 计算出槽编号,然后交给负责这个槽的主服务器处理,如果客户端访问的 key 对应的槽 不是目标服务器处理,那么目标服务器就会指引客户端重定向到槽所在的服务器(MOVED错误)。
给主节点分配槽:CLUSTER ADDSLOTS a b c d e f ...(a b c 是槽编号) 当所有槽都分配出去之后,集群才会变成上线状态,当给某个主节点分配槽,他会向集群中的其他主节点广播,自己负责了一个新的槽,并且带上这个槽的编号,其他主节点收到之后,会更新自己 ClusterState 的数据,这是一个 结构体,里面有个大小为 16384 的指针数组,如果某个编号的 槽被分配了,这个编号对应的指针就会指向对应的 ClusterNode,结构体ClusterNode 代表的就是一个节点。所以每个节点都会知道集群的槽分配情况。
槽广播:

槽重分配:
节点A会记录自己当前正在被 移动到另一个节点B的 所有槽,当客户端向节点A发送请求这个槽对应数据的命令的时候,A会先查,看看数据在不在,不在的话就回应 ask B ,让客户端去访问B
但是客户端直接访问 B 的话,B会说槽不在自己这,该去找A,即使数据已经在自己这里了,B同样也会记录正在移到自己这的 所有槽。客户端需要打开自己的 ASKING 标记才能访问 B上想要的数据。

故障迁移:
所有节点会通过 PING-PONG 发送-回应对确定其他节点是否在线(不只是主节点,从节点也会探测)
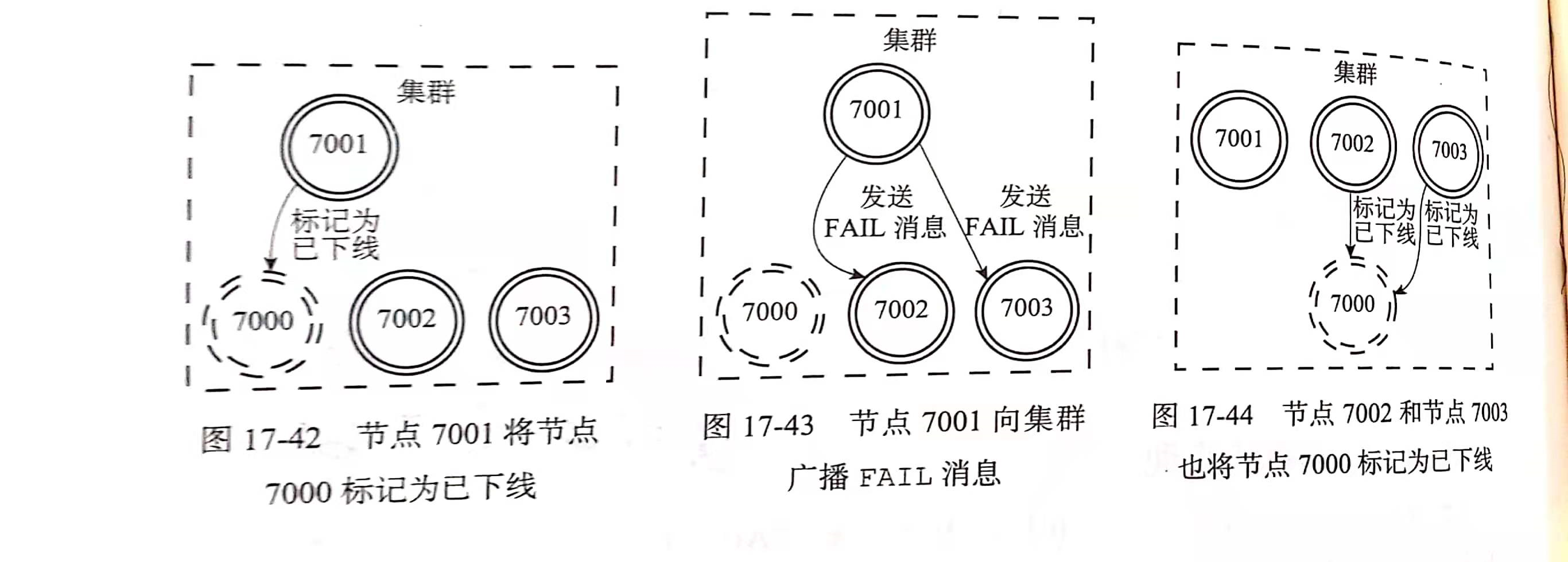
如果一个主节点A 发现某个主节点 B 好像下线了,那么他会告知其他主节点,B好像下线了。
如果某个主节点收到了 半数以上的主节点 对 B 的下线报告,那么他会向集群广播 FAIL 消息,快速告知集群中其他节点,B好像下线了,达到快速失败,而不是通过 PUBLISH 那样一个传一个的方式,或者gossip的感染方式来告知 B 失败。
如此一来,主节点B 被集群中的所有节点(包括从节点)认为是下线。
从节点这时候就要发话了,必须有人当期逝去主节点的大任,于是下线主节点的从节点们,用类似 raft 选举算法的方式,让剩下的主节点给 自己投票,得到半数以上主节点支持的从节点会成为新的主节点,之前逝去主节点的槽都交由该从节点处理。并且剩余的从节点和主节点,都会认这个从节点为新的主节点。
消息:
PUBLISH 是一传一的

PING, PONG , MEET 是基于 Gossip 的,其中 PING, PONG 是节点间的日常任务,其中夹带私货(悄悄话),是的整个集群每个节点得到的信息收敛
FAIL 是单个节点向所有节点广播的,是的所有节点都将某个节点标记为下线,用于立即失败