

后端概述:原子-硬件-分布式/集群 - 新设想
这是一篇将给大学新生的启蒙文章,有不对的地方,水平不够的地方,请多指正
我将从一个简单系统演进到一个规模庞大的系统 的过程 来讲述,后端是在学些什么。当然,后端里面也是有分支的,我讲的是主要的分支。
后端最基本的工作是写业务,所谓的业务逻辑就比如 客户买一个商品,我要看他余额是否够,够的话扣他余额,并且创建订单,减少商品库存。
这就是最简单的业务逻辑。可以用下面这段假代码表示。
public void doPurchase (User 客户, Good 商品) {
if (客户.余额 >= 商品.价格) {
客户.余额 = 客户.余额 - 商品.价格;
创建订单();
商品.库存 = 商品.库存 - 1;
}
}
最简单的,把这段代码放到服务器上跑,并且让服务器连上数据库,这样就能实现最简单的业务功能。
节点可以简单理解成一台电脑
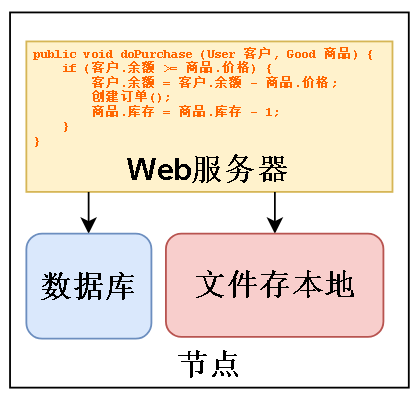
一开始可能只是一个用户或者几个用户访问,但是产品放出去总是要面向社会的,随着用户越来越多,首先要解决的是正确地执行我写的业务逻辑。
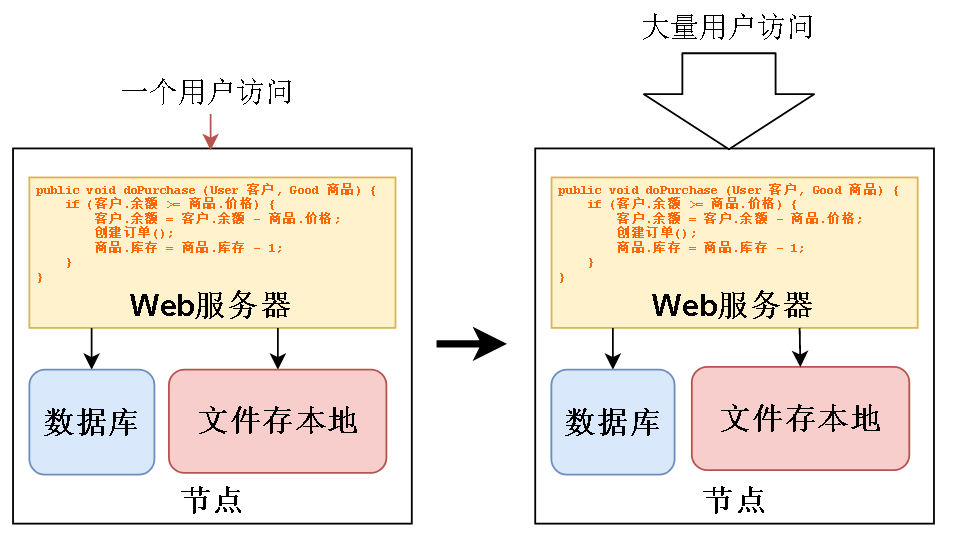
就比如有两个人来买商品,现在商品库存只剩一件,我必须让一个人正确买到,另一个人买不到。
这就是一种并发控制,“并” 的意思是多个用户同时,“发” 的意思是用户发出请求,并发控制要做的事就是正确处理多个用户同时发起的请求,保证数据最后是对的。
回到刚才的场景,数据是存在数据库里的,现在的场景数据库只装在一台电脑上,我们暂时只讨论同一台电脑怎么进行并发控制。

要知道,在一台电脑上,进行并发控制根本上依赖的是硬件,软件只起到辅助作用
(提神!)

在目前使用通用型号CPU,比如Intel,AMD 的计算机上,一般都是跑下图这种简化模型,有的可能没有 Invaild Queue
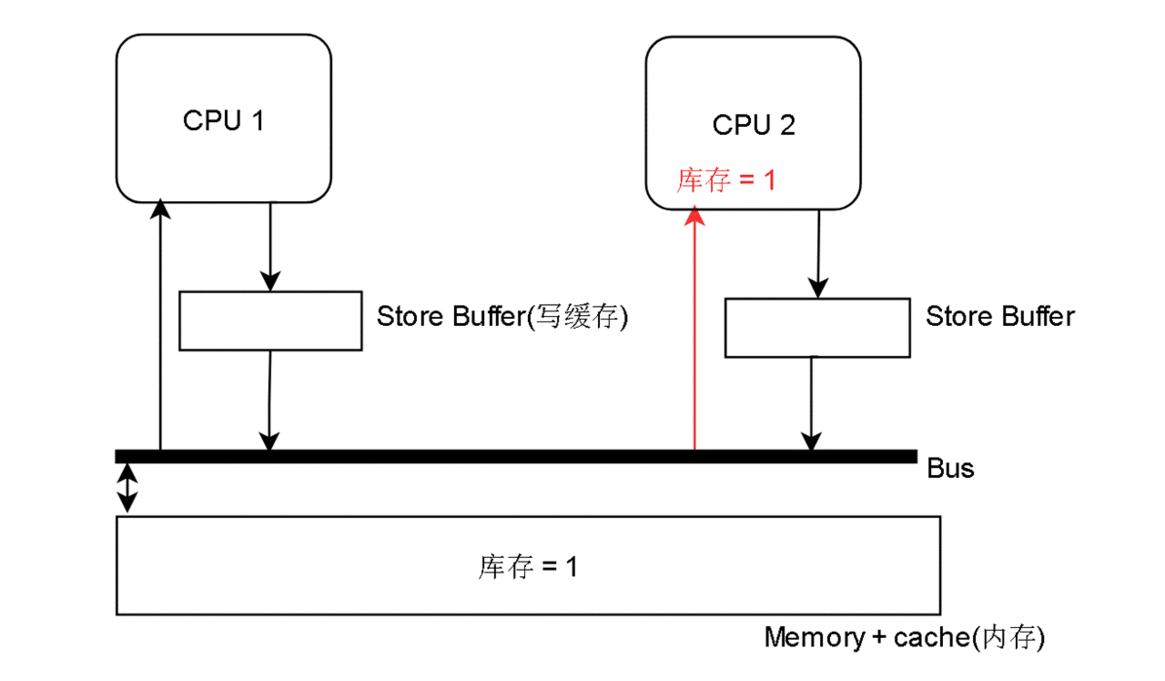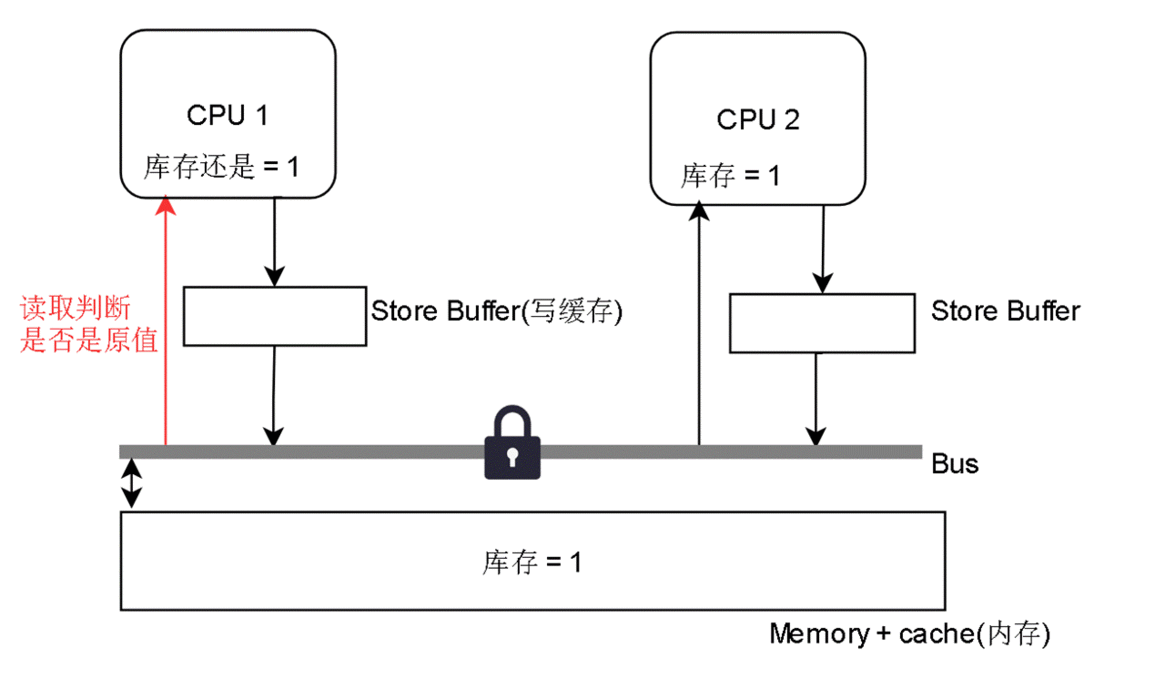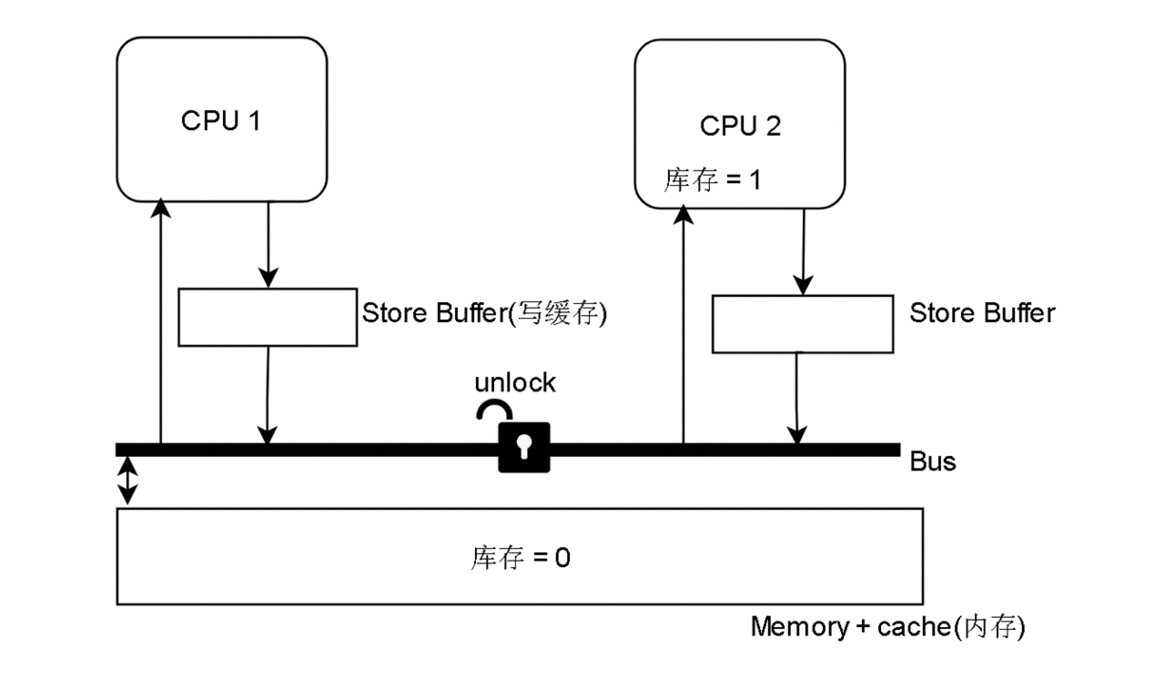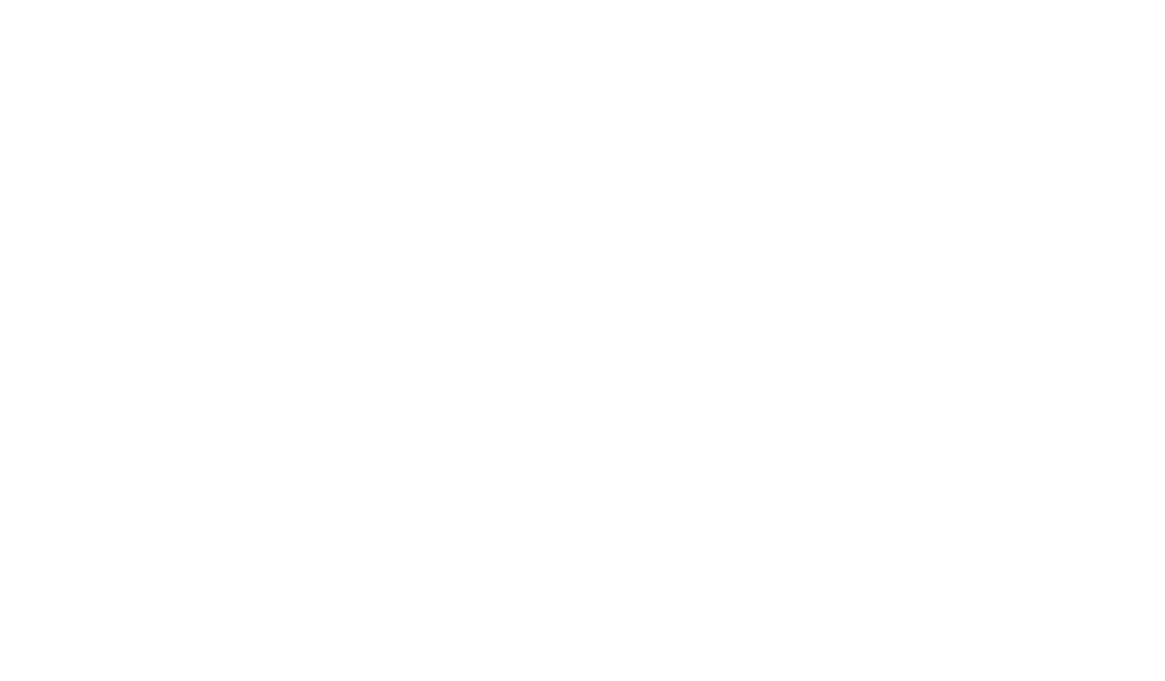
在这种模型里,造成并发处理的结果不正确的两个部件是 Store Buffer 和 Invaild Queue
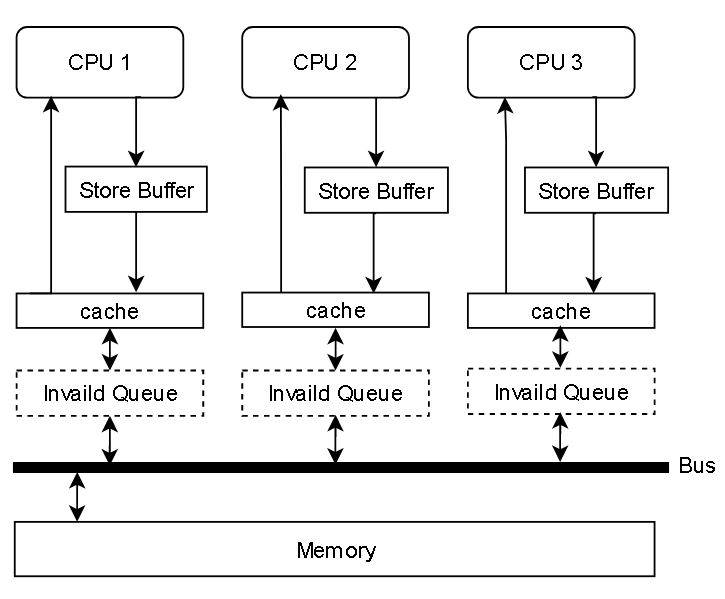
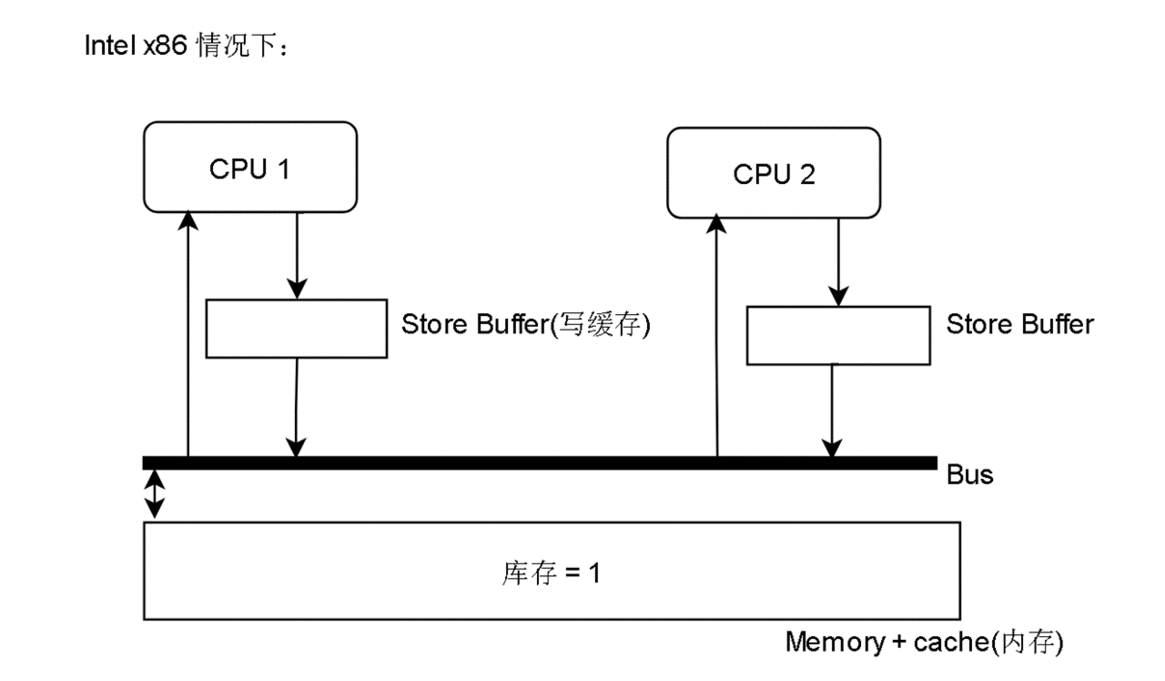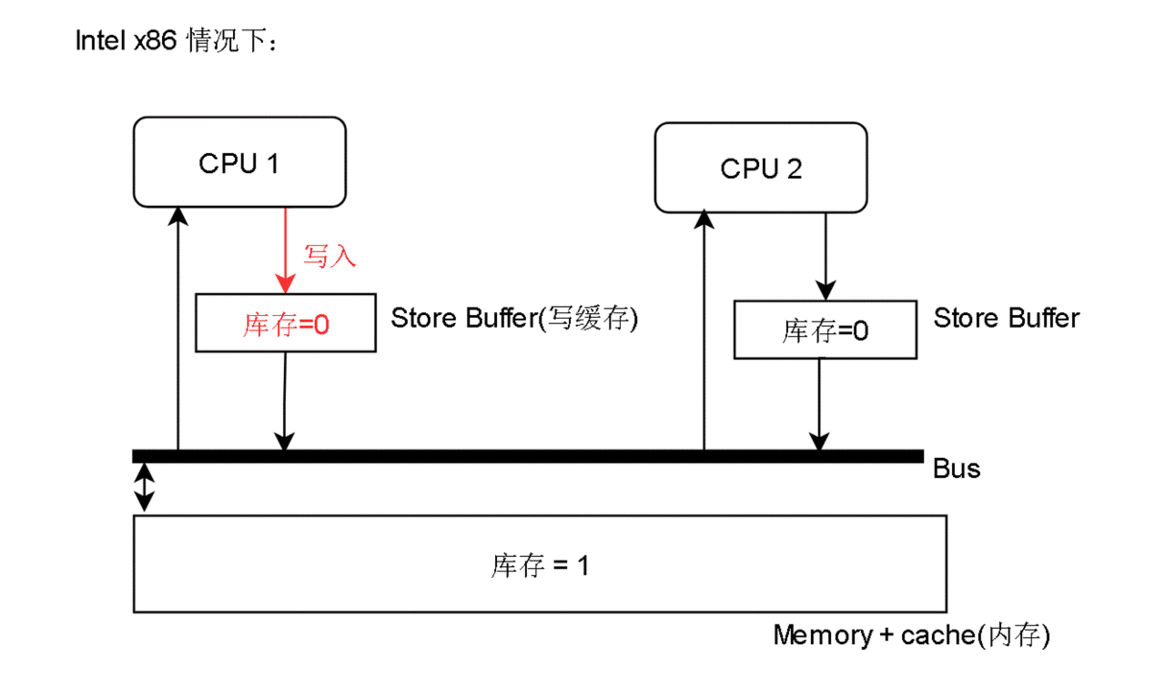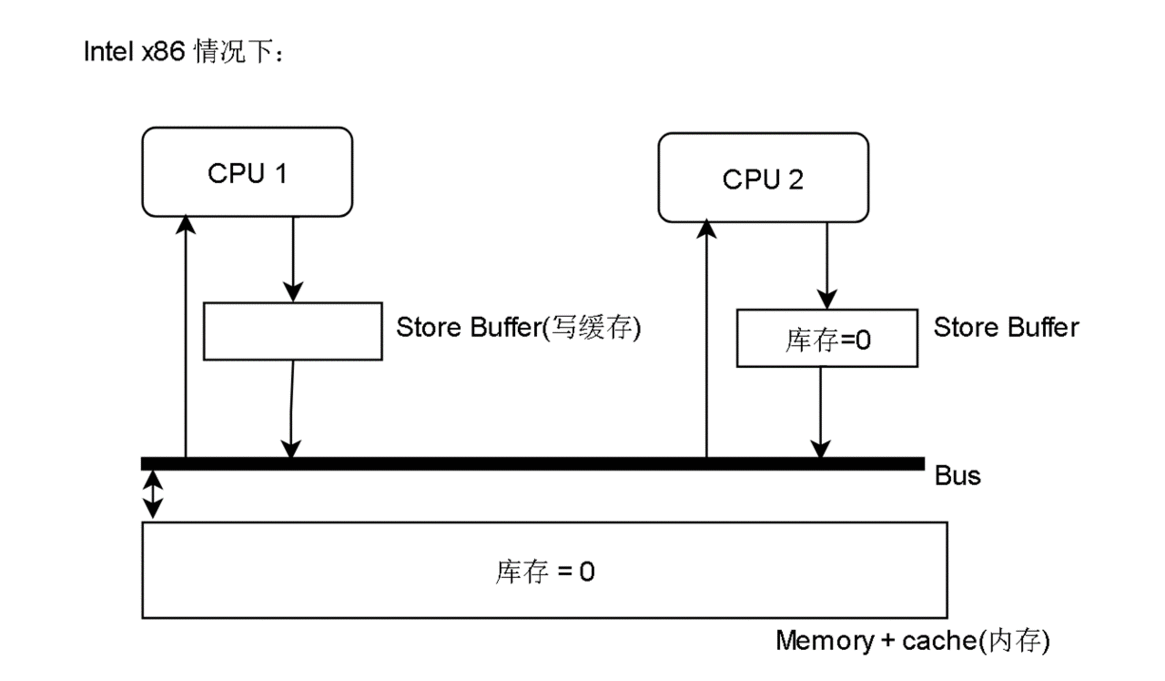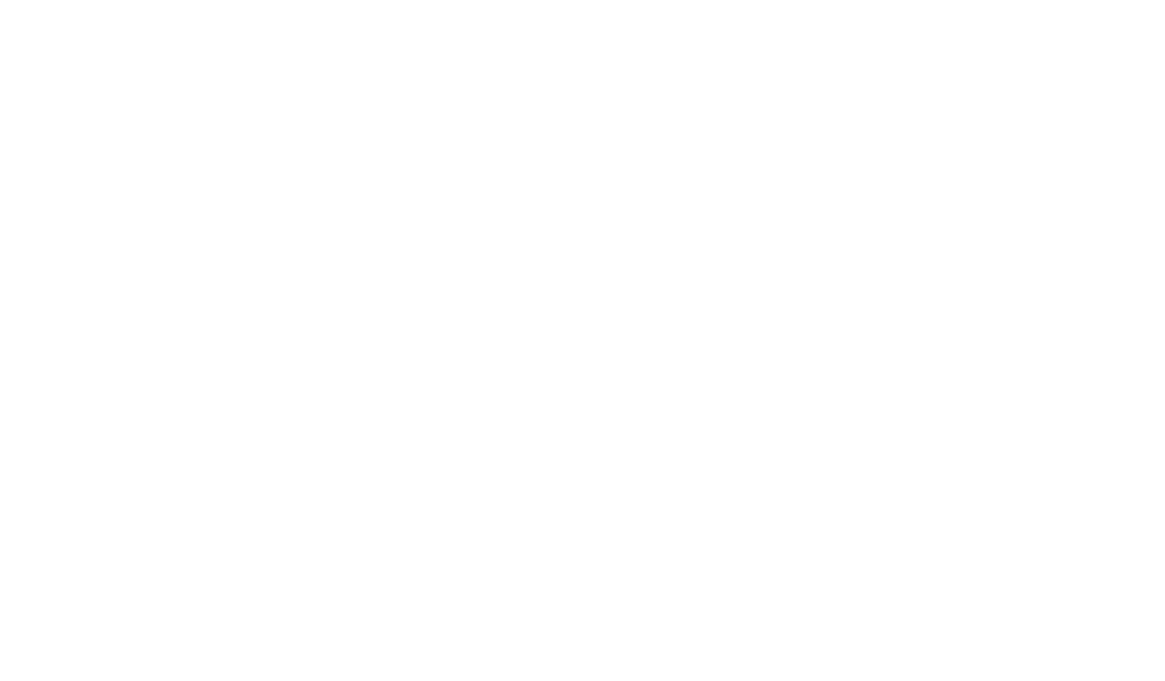
我们直接看最简单,只有Store Buffer的是怎么工作的:
在多线程情况下,假如两个用户发出购买请求,处理他们请求的线程分别跑在 CPU1 和 CPU2 上
CPU写出的内容是会被缓存在 StoreBuffer 里的,因为写在StoreBuffer里很快,写回缓存或内存会慢得多。
所以 StoreBuffer 正如其名,写缓冲区
CPU 2 先读到 库存 = 1,然后 -1 ,表示买了一件,然后放到 Store Buffer 里
CPU 1 也读到 库存 = 1,然后 -1,表示买了一件,然后也放到 Store Buffer 里
最后他们把 库存 = 0 都写回内存,最后只有一件商品,但是卖了两次,结果可想而知,其中一个用户买了,但是最后没有货给他。这样就有损企业信誉

一种可行的解决方法是令原本的简单写指令 变成 上锁-比较-写
各位以后学习深入之后,会发现,无论是操作系统,JVM或其他流行软件,他们的并发控制机制无一例外都是上述硬件上的控制 + 软件上的队列或者其他数据结构 实现。这里引申出后台要学什么的一个答案:硬件工作机制 和 数据结构。其实软件套路都一样,真的,都是在硬件的基础上戴着镣铐跳舞,根本原因是因为硬件是软件的根,是整个计算机体系的根,所有软件上的进步都要依赖硬件去实现。
进一步地,我们用更加微观的视角去观察:
各位高中都学过化学,硼原子最外层是三个电子,硅原子最外层是四个电子
把这两种粒子结合起来,用特殊光线处理,他们会通过共价键结合。这时候他们的共用电子对有7个电子,我们都知道
原子会尽可能让自己最外层电子呈 8电子稳定结构。所以硼和硅的结合体容易得电子。
换成磷和硅的话,会多出一个电子。

现在用一个绝缘容器,先填好硼和硅的掺杂物,然后再挖两个洞,填进磷和硅的掺杂物。插两根导线。
如果通电,因为中间是容易得电子的硼和硅的掺杂物,电子浓度低,两边是容易得到电子的磷和硅掺杂物,电子浓度高。
无论电压方向,在边界都要逆浓度运动,所以电子怎样都流不通,也就没有电流。可以在上下两端加如图电压,电子就会汇集到这条沟道上。左右再加电压,电流就能通了。

上面这种结构叫 NMos 管,本身可以控制电流的流通,一个CPU要锁总线的时候,可以把其他 CPU 连接总线的 mos 管的上下电压断掉,左右两边电流就流不通,其他CPU无法和总线交换数据,这样就能控制总线。

总结一下,刚刚我们从微观层面观察一台电脑的并发控制实现是怎么样的,现在回到宏观层面。
现在用户量越来越多,可能从几十个人到几百个人,要怎么解决。

最简单的做法是,把功能分散到不同的物理机上去。而且可以根据功能做出不同的硬件资源调整。
比如 Web 服务器一般要求比较多的是 更多核心的 CPU。
数据库要求 较快的磁盘 IO 。那就可以给数据库节点安装 IO较快的固态硬盘。并且把存热点数据的表放在固态硬盘上。
文件服务器 一般是要求较大的容量,那就可以换上廉价的大容量机械硬盘。这就好比 一开始你一个人开店,收钱,记账,搬货 都要你一个人干。
后来客人越来越多,你受不了了,于是雇佣一个数学好的人来记账,雇佣一个身强力壮的人来搬货,自己负责收钱。物尽其用,人尽其材。

但是,用户量又变多,从几百人上升到几千人,要怎么解决?
最简单的做法是,给每种功能加机器,就好比客户越来越多,一个收钱,一个记账,一个搬货已经不能满足需求。
那就多招几个搬货的,多招几个记账的,多招几个收钱的。
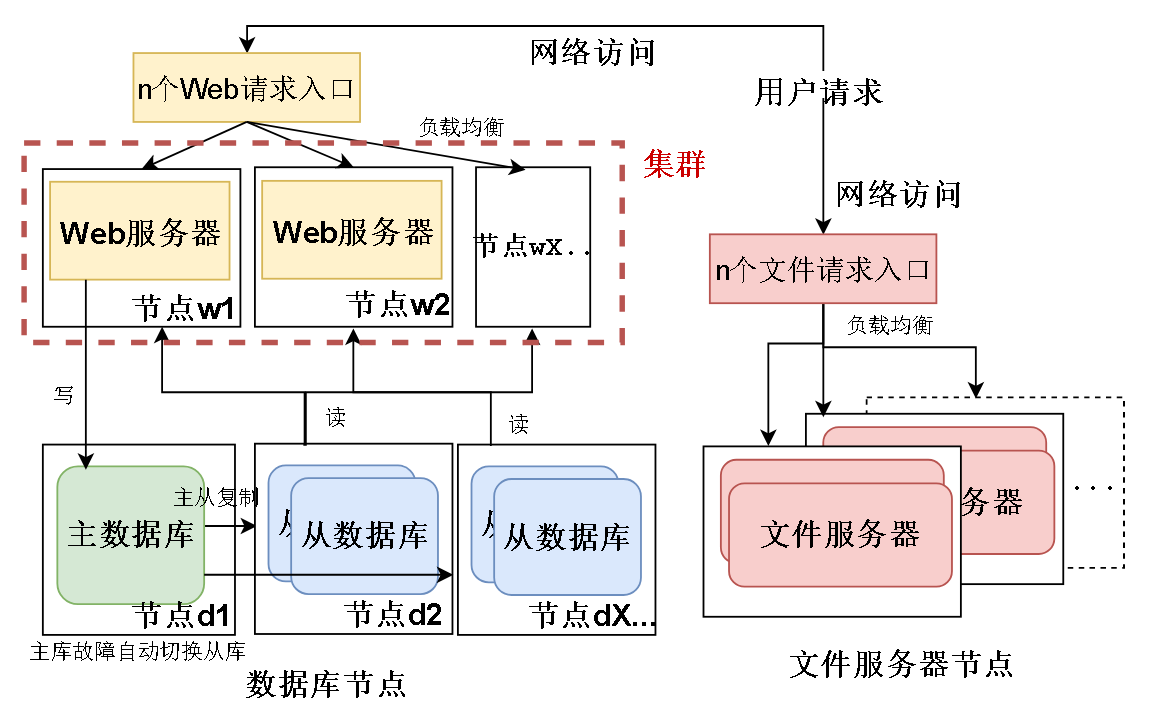
于是我们引入“集群”的概念,集群指的是,一群行使同一功能的机器。他们之间不会沟通交流。但是都是为了同一个目的。
比如说 上面这些 Web 服务器,都只是处理用户订单,完成同一个功能。他们是一个 Web 服务器集群。
同时还要引入“有状态” 和 “无状态” 这两个说法。
无状态的节点是对等的,完成同样的功能,而有状态的节点不一定是对等的。
比如上面这些Web服务器节点就是对等的,他们就好比收银员,收银员只会收钱,检查钱对不对,但是他不会记住用户剩下多少钱,不会记住状态,所以收银员是对等的,缺了任何一个收银员,都可以继续收银。
但是有状态的节点就不一样了,数据库就是有状态的,因为数据库存储用户余额信息,我们的例子里,主数据库是来写的,所以少了主数据库业务就不能运行。
我们先抽象一下,把刚才的架构用右边这幅图表示。
目前这个架构已经能满足一定数量的用户,但是随着用户的需求激增,我们应该提供更多的业务给用户。

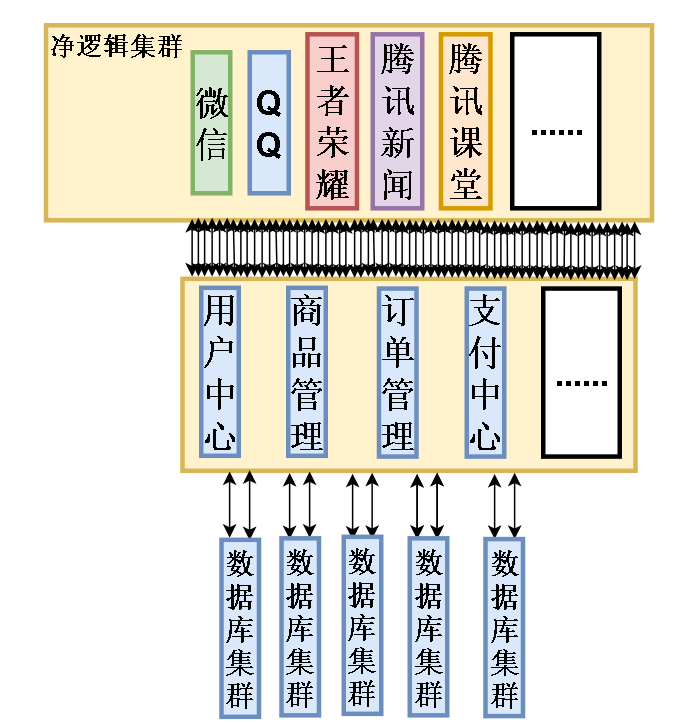
公司发展越来越大,业务越来越多,比如腾讯从一开始的QQ发展到 微信,QQ,王者荣耀,腾讯新闻 等等。
接着问题先出现在数据库上。
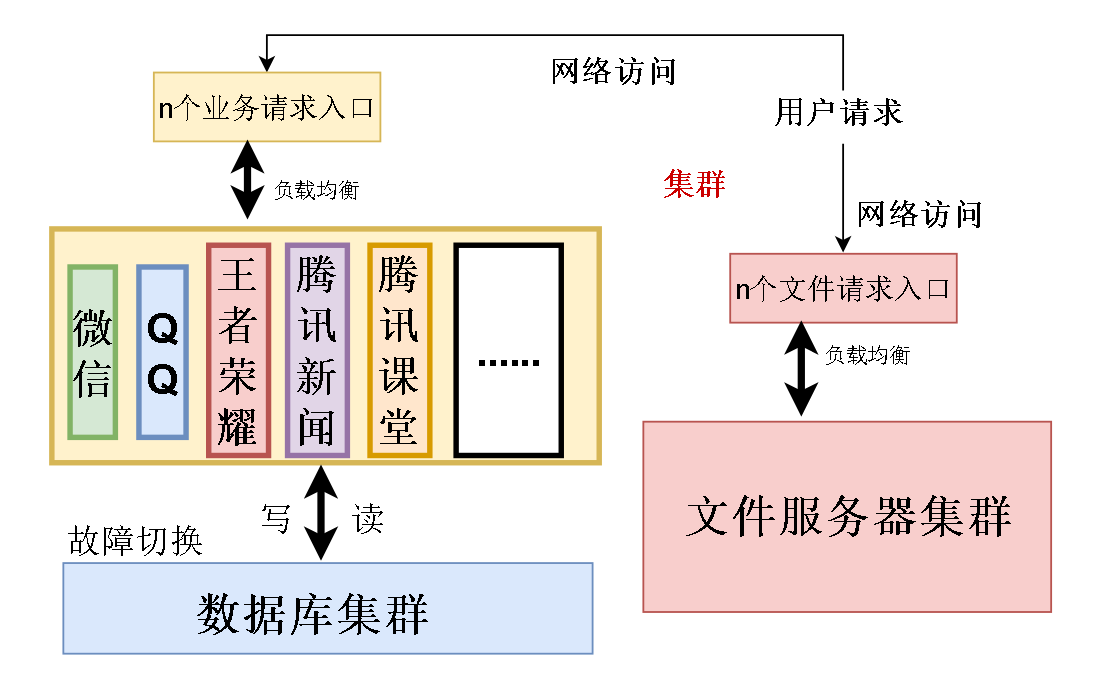
第一个问题是 数据库磁盘IO 的速度太慢,成为整个系统的瓶颈,每秒几百万甚至几千万的请求直接打在数据库上会把数据库压垮。各位应该都听过木桶效应,桶盛水多少取决最短的板。这个系统也一样,这个系统的速度天花板不是速度最快的部分,而是速度最慢的地方。

第二个问题是数据库连接过多,每一个业务,比如微信,都要几百台,甚至几千几万台机器支持,需要的数据库连接也要几千几万条
全部业务加起来需要的数据库连接十分庞大
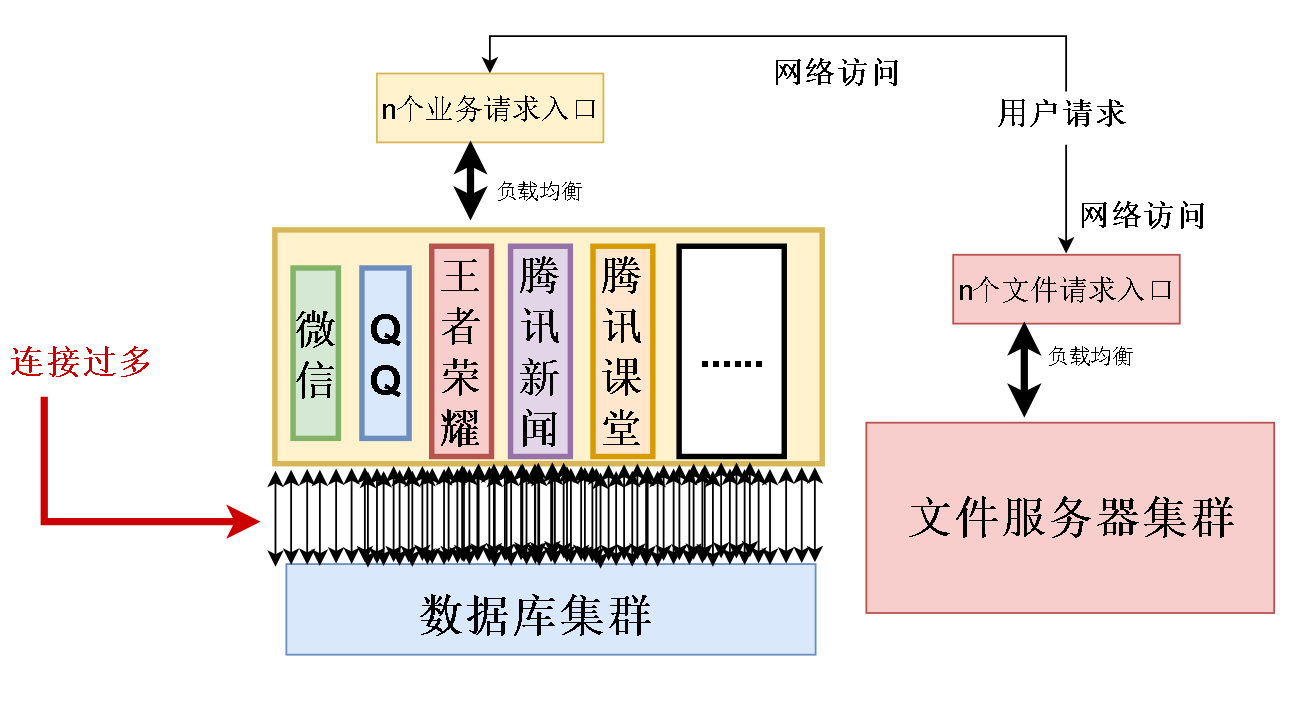
先解决第一个问题,加缓存,访问数据库之前先去缓存看一下有没有数据,没有再读数据库
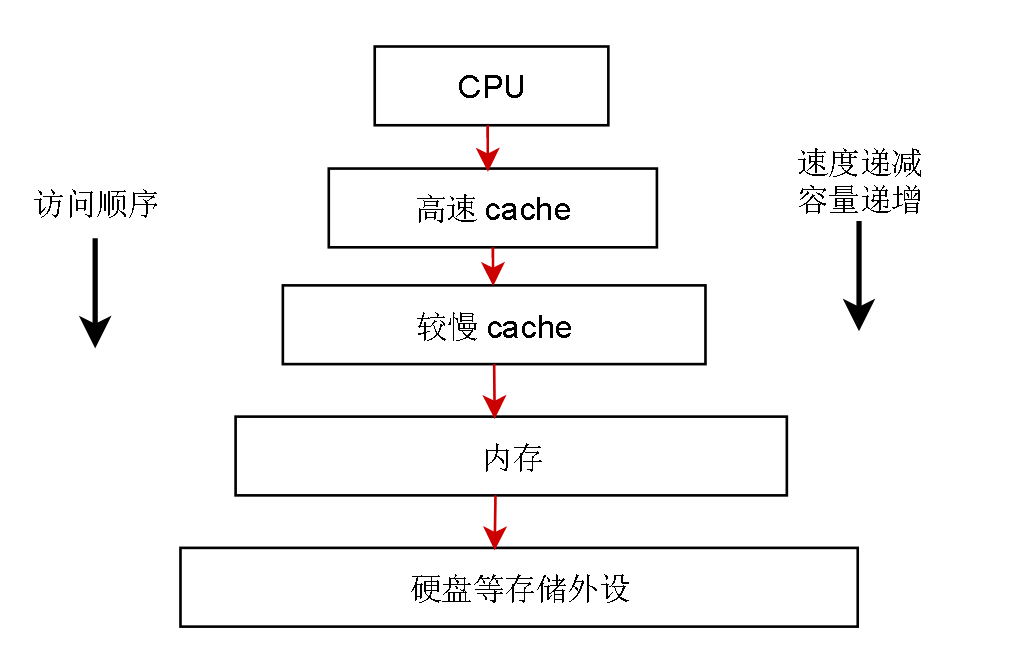
缓存之所以会快,是因为缓存的数据集中放在内存中,可以把缓存简单地看成速度快的内存,把数据库看成是速度慢的硬盘。
所以可以简单看作先去内存里读,如果内存没有,再去硬盘读。

这种设计思想在计算机领域很常见,典型的计算机架构采用的就是这种先读快的,读不到再读慢的设计思想
这里给出后台要学什么的第二个答案:设计思想
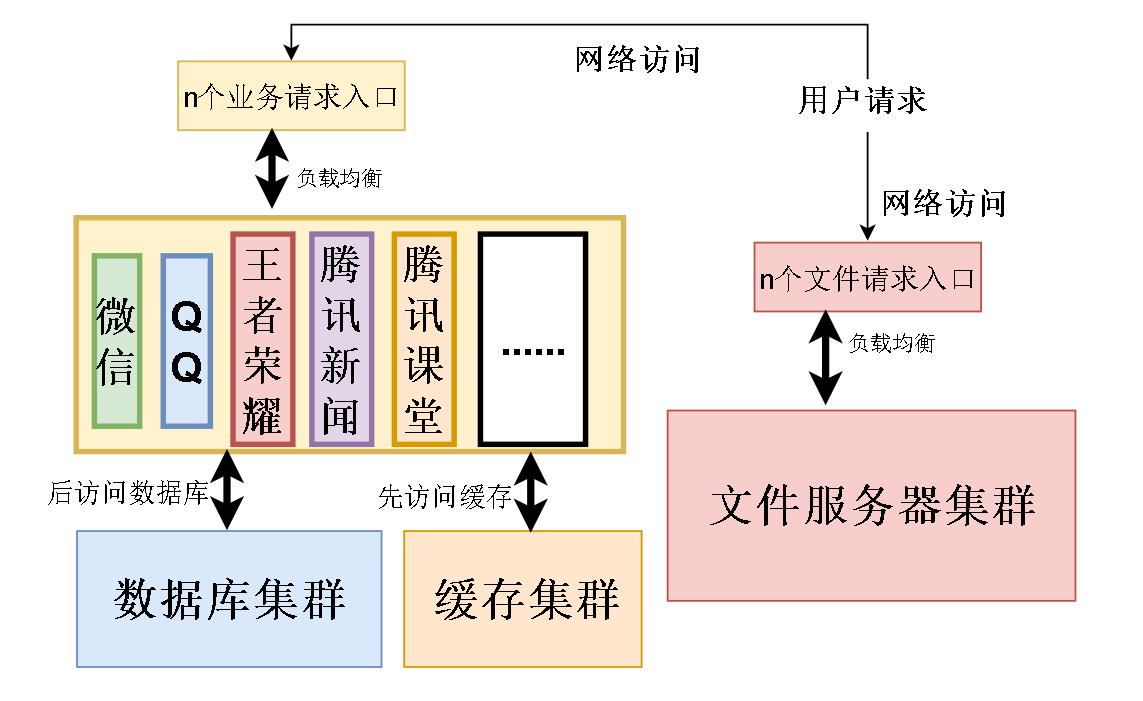
现在解决第二个问题,怎么把数据库连接数量减少?

分析一下,这些应用的功能需要访问数据,所以和数据库连接。但是他们很多功能都是重复的
比如他们都有用户注册和用户登录,购买商品和支付,这些功能其实可以独立出来。
如此一来,数据库连接的数量大大减少。这些被分出去的功能被成为服务,如果分得足够小,足够合理,被称为微服务。
如果把这些微服务分布到不同的主机上,并且用集群去加强高可用性,这样的架构被称为分布式微服务架构。
所谓高可用,High available,指的是一个系统就算部分机器坏掉了,这个系统还能正常对外提供服务。
这是目前比较流行的一种架构,有不少落地的项目
这里要阐明一个误区,有人可能觉得分布式微服务只是单纯把一个个单体应用的共同功能拆出来,做为服务放在不同的机器上,应用简单的通过网络请求同步调用这些服务,服务和服务之间如果通信也只是简单的网络请求。如果这样的话,应用和服务之间还是强耦合关系,要想办法把该拆解的地方拆解掉。
举个例子,李二狗和赵铁柱在一家超市上班。李二狗是售货员,赵铁柱是搬运工。
有一天,李二狗发现自己的货架上的货不够了,他去仓库让赵铁柱搬一些货出来。然后他自己呆呆地站在仓库里,等赵铁柱搬完货才回去干活。可以想一下这期间如果大量客户来买东西,大概率气的直骂娘。这就是一种耦合的体现,李二狗必须在赵铁柱搬完货之后才能继续自己的工作,依赖于赵铁柱。

解耦的方法是,李二狗没货了就去喊赵铁柱搬货,但是自己接着回货架上干活,赵铁柱找到货,把货搬出来后再喊李二狗来拿。这才是合适的方式。

前一种方式 被称为“命令”,发出命令的人要等到接收命令的人 反馈结果才继续运行。
后一种方式被称为“事件”,“缺货了” 是事件,“货搬好了” 是事件,各个功能之间通过 “事件驱动” 的方式减少依赖,松散耦合。
整个分布式的结构该松的地方松,该紧的地方紧,服务切分的边界得当,才是真正的分布式微服务结构。否则只是一个分布式单体。和一台电脑上部署的一个单体应用没什么本质区别。
至此,整个业务系统已经挺完善了。但是还远远不够。
我们先要介绍一下 分布式能力这个概念。我们把业务代码封装到一个机器里,让他变成分布式集群中的一个节点。时间关系我只讲三个比较重要的。
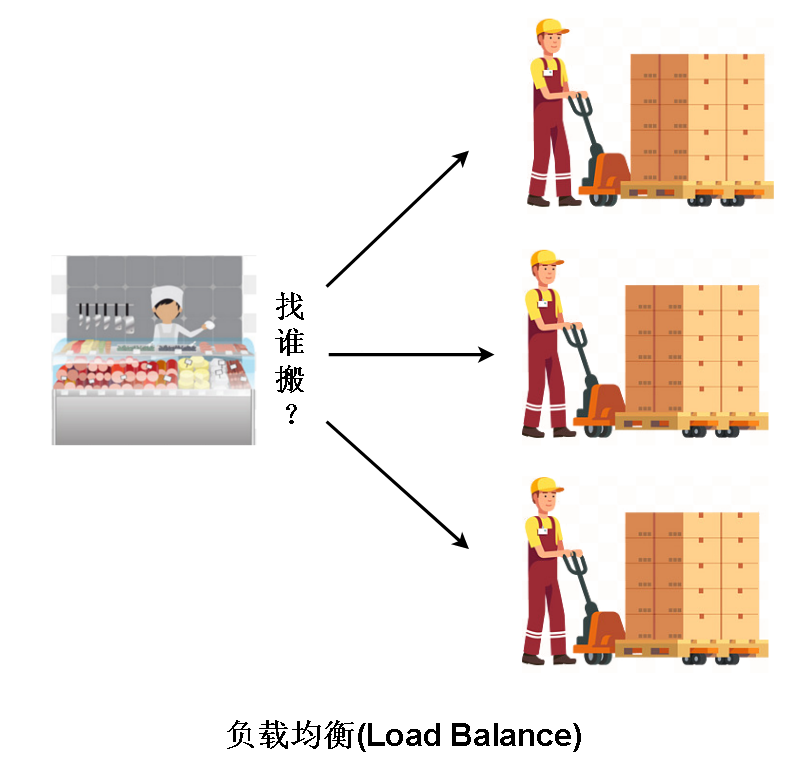
第一种能力是负载均衡,解决的是已经知道有谁能干活,但是找谁帮我干活的问题。 如果有三个人能帮我干活,我要找哪一个,如果每次都只找同一个人,那么这个人肯定累个半死,速度也越来越慢,理想的情况是按照每个人能力不同,让每个人干适量的活,负载均衡解决的就是这个问题。
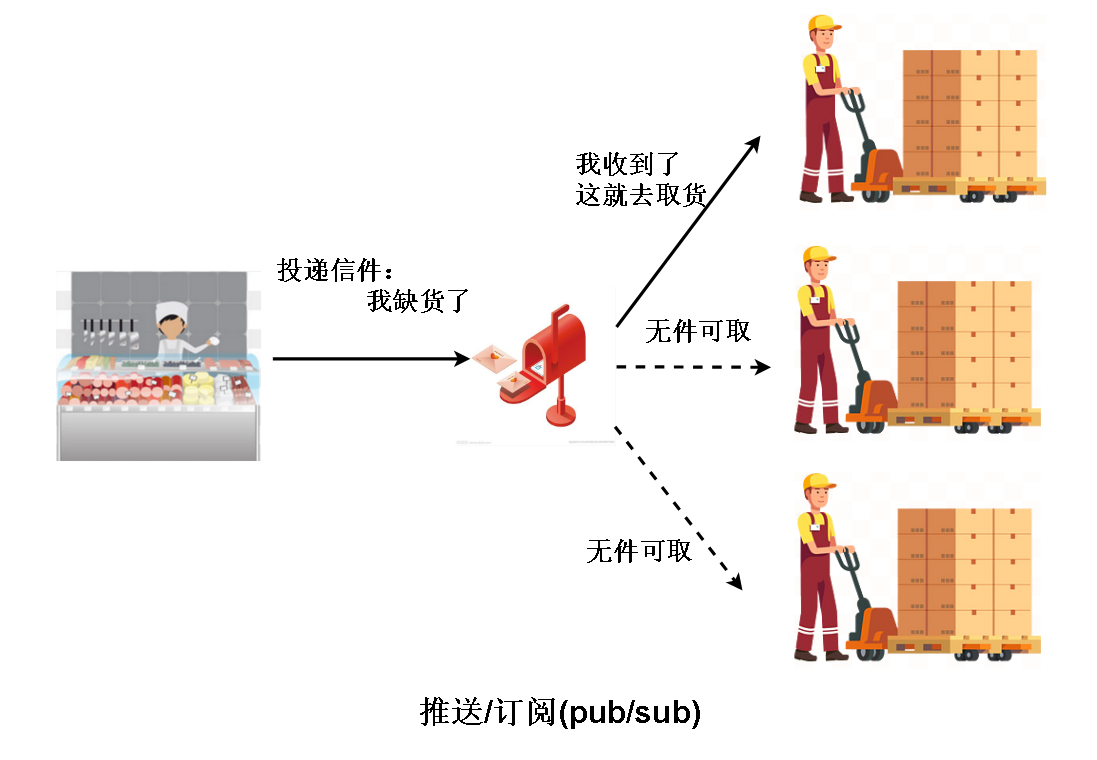
第二种重要能力是 信息推送 与 订阅。这是一种解耦的方法。其实就是上面说的 “事件驱动” 的方式,信件就是事件。
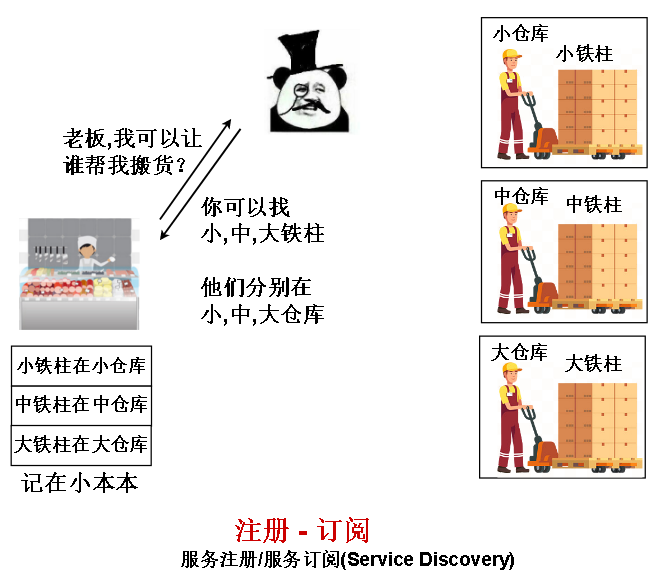
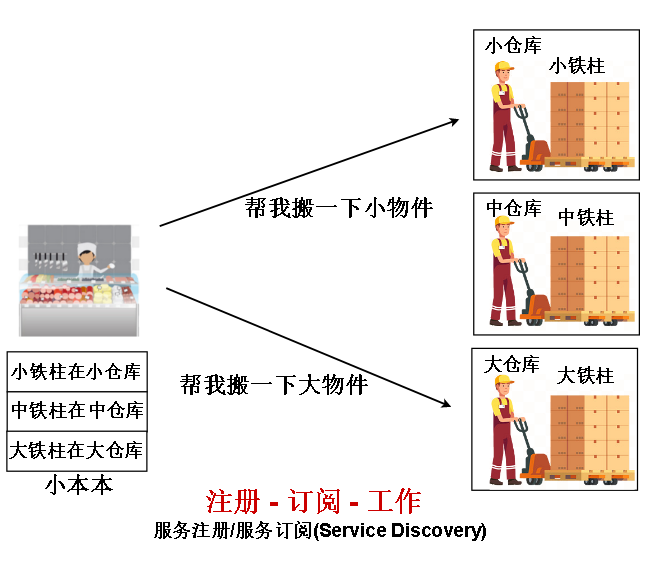
第三种重要能力是 服务发现,解决的是 “去哪找干活的人” 这个问题。
先是服务告诉注册中心 他们自己在哪里,接着应用向注册中心 询问 服务在哪里,最后应用调用服务。

还有很多能力,比如重试,熔断,协议转化之类的(具体可见 lbryam 的论文 Multi-Runtime Microservices Architecture)

目前这些 能力大部分是以 SDK 中的函数库或者包的形式提供给开发者的,也就是开发者每开发一个应用或服务就需要往自己的的程序里嵌入这些库和包。
往往一小段的功能代码,需要几百M,甚至几G 的包或库。

内存和CPU时间等硬件资源十分宝贵,这些包和库的冗余是无法容忍的浪费。
于是有一种新的设想,Service Mesh 和他的 SideCar!
Side Car 起源于,一种老式军用摩托车,这种摩托车,有一个副座,主座上的人负责专心开车,副座上的人负责解决掉一路上遇到的麻烦的敌人。
有人提出一种新的设计,将通信相关的 分布式能力 从业务代码中拆出来,放到单独的一个进程里去运行,并且和业务代码跑在同一台电脑上以加快通信效率。

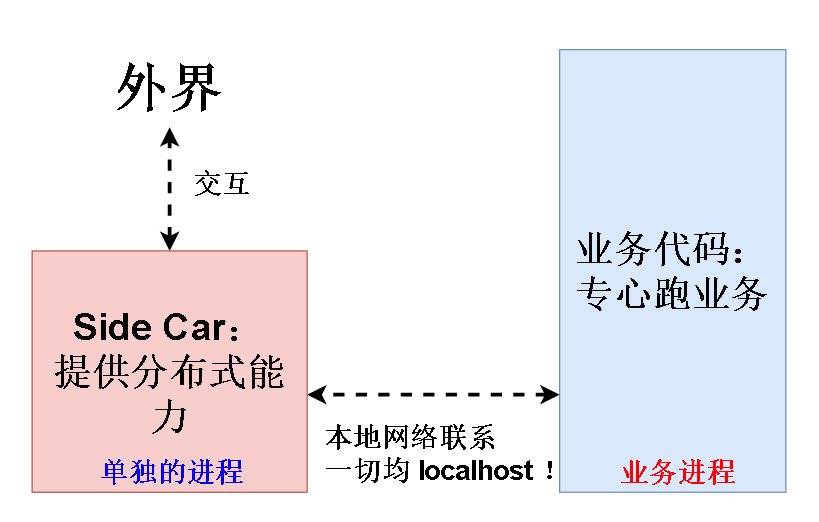
原本通信能力也是业务代码的一部分,现在加上 Side Car,成为右边加强的网格,这种网格被称为 Service Mesh
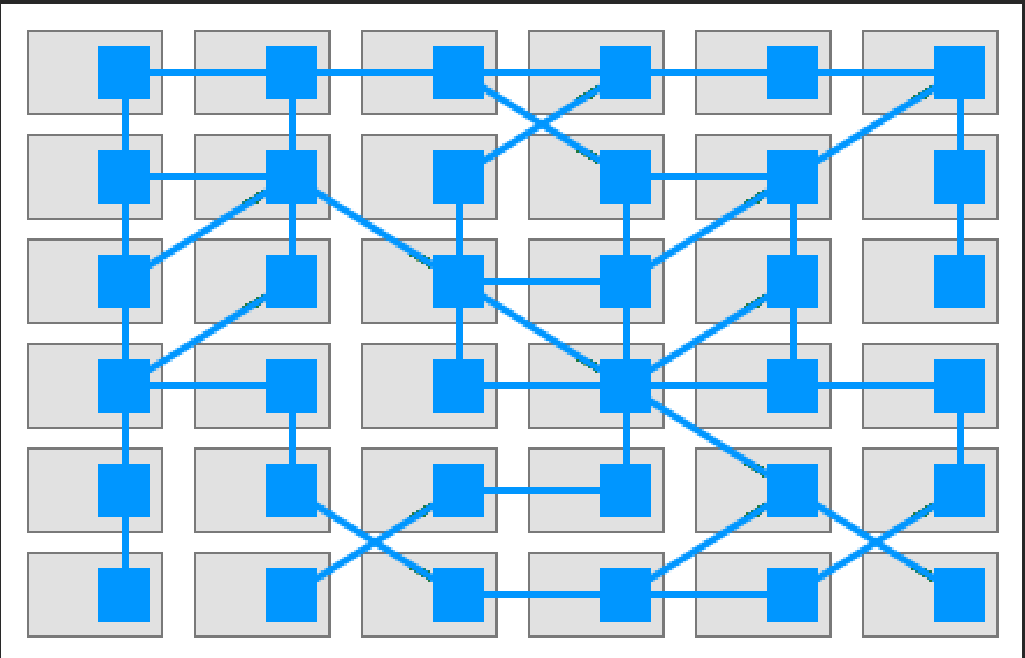
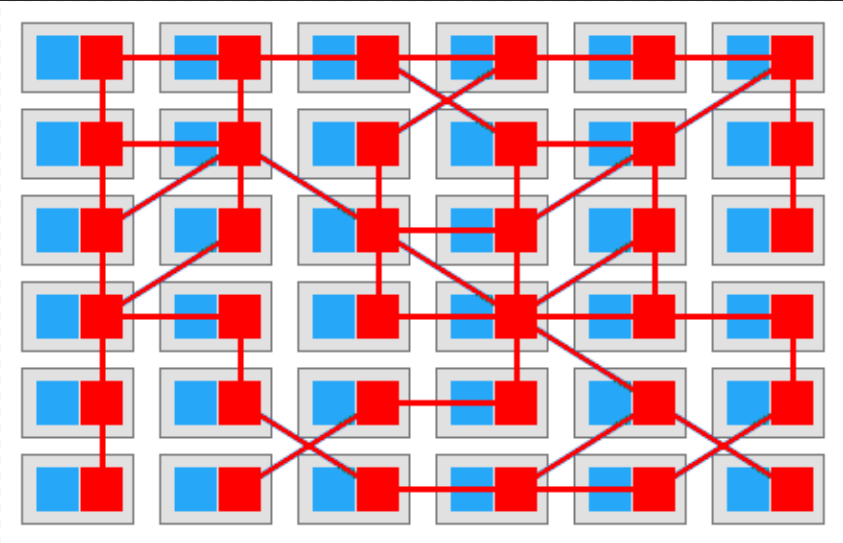
新起点:
上面的 Service Mesh 只是将 通信相关的能力封装在 Side Car 中,某位架构师(Bilgin Ibryam)又提出,能不能将所有的分布式能力都从业务代码中抽离出来?做为 SideCar 一样存在?
并且把对速度要求不高的 部分 部署到 云或者其他机器上?实现业务代码和 分布式能力的完全松耦合?
这种设想架构被称为 Mecha,也就是机甲。
我们的业务代码 就像驾驶员,可以操作强大的分布式能力。甚至一副机甲 可以被 多个驾驶员共享,实现资源充分利用。


目前这种架构还是在孕育阶段,但是已经有了许多支持他的项目。你们看下面三个 是船舵,帆船,船长,是一种新征程的寓意。这种架构只是一个新的开始。

至此,我讲完了架构的演化历程。最后,给各位留个思考题,时间问题来不及讲。
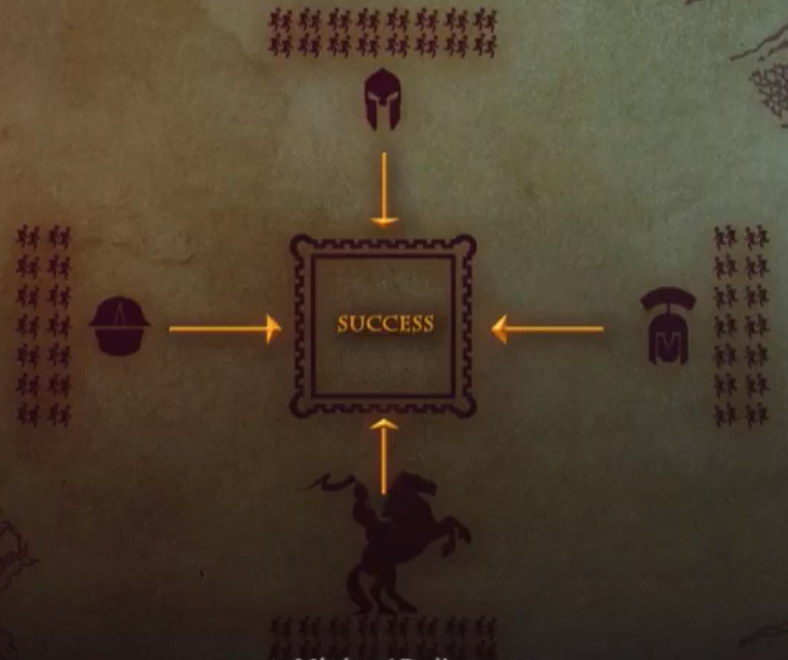
中世纪的时候,拜占庭帝国派四只军队夜里 攻打一座城池。这座城池易守难攻,必须半数以上(此处为3)的军队攻打才能攻克。
四只军队的将军 不能通过举火把照明的方式 相互示意进攻,因为会被城内守军发现。
他们之间只能通过 快马送信的方式相互通信 , 信里的内容只能 写进攻或撤退。
现在已知 四个将军中 有一个是叛徒,这个叛徒会 给其中两位将军发送 撤退的消息,但是给剩下一位将军发送进攻的消息。
如果他得逞的话,可能出现只有一个忠诚将军进攻,叛徒和其他两个忠诚将军撤退的局面。怎么才能做到三个忠诚的将军 要么都撤退,要么都进攻。
(answer : pbft 算法)
这其实是一个算法问题,而且是用来解决刚才讲的分布式系统的一致性的算法,区块链也是分布式的系统,目前也在找高效的算法来解决这种一致性问题。
一个系统选用什么算法很大程度上 影响了 系统的快慢程度。算法很重要。
这里给出后台要学什么的第三个答案:算法
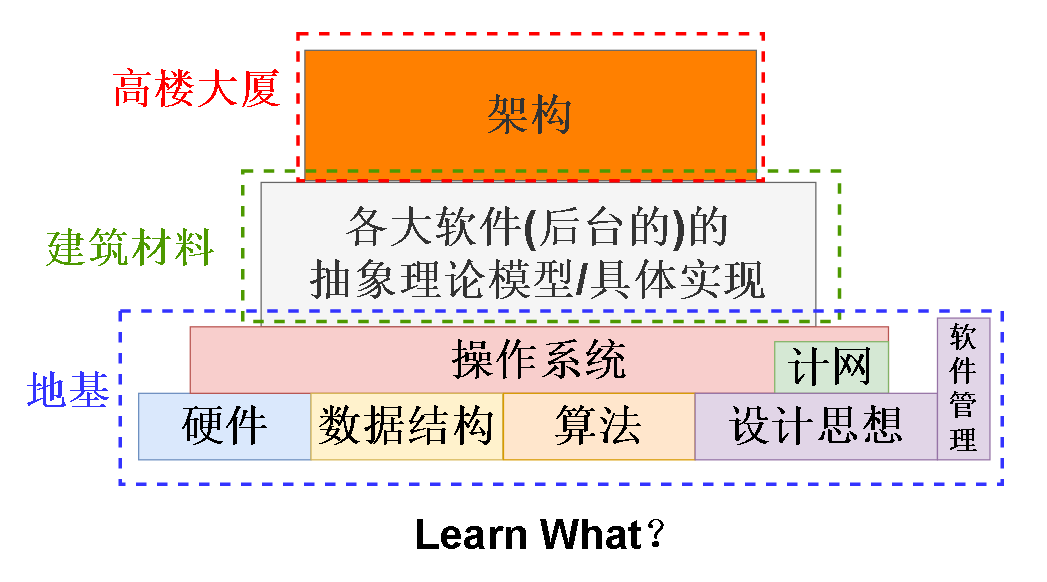
总结一下:后台这个方向要学什么:
地基这一部分 其实每个方向大部分是相同的,但是还是有点区别,比如做游戏的可能更加注重渲染之类的,更加注重显卡相关的硬件。
而后台更加关注怎么榨干CPU , 内存 和 硬盘。
最后是我的个人建议,学技术不是唯一的出路,人生还有许多路可以走,有无数种可能。在合适的时间干合适的事。
还有就是学技术只是 学会做点事,还有很多事情要去学习怎么做,学会做事同时还要学会做人。
还要就是不仅仅是只学专业知识,还要关注时事,有“两个大局”的意识,第一个大局是国内的,国家现在各行各业都欣欣向荣,但是我们在某些尖端领域方面还是被卡脖子,能不能实现弯道超车可能就看各位,看我,看我们这代人的了。第二个大局是国外的,现在世界格局逐渐去中心化,可以去关注世界各个产业的发展情况,也是一种乐趣,不一定知识拘谨于我们计算机这个领域。

